
中国也有了世界第一的模型,它的名字叫Seedance 2.0
Seedance 2.0的热潮,正席卷全球AI创作领域。作为字节跳动推出的新一代视频生成大模型,其发布迅速引爆了行业讨论,凭借卓越的性能表现,为整个视频内容创作赛道带来了颠覆性的变革。
我们深度分析了数百个由Seedance 2.0生成的视频案例,提炼出五个最具实用价值与代表性的核心应用方向。本文将为您逐一详解,助您快速掌握这一强大工具的核心玩法。
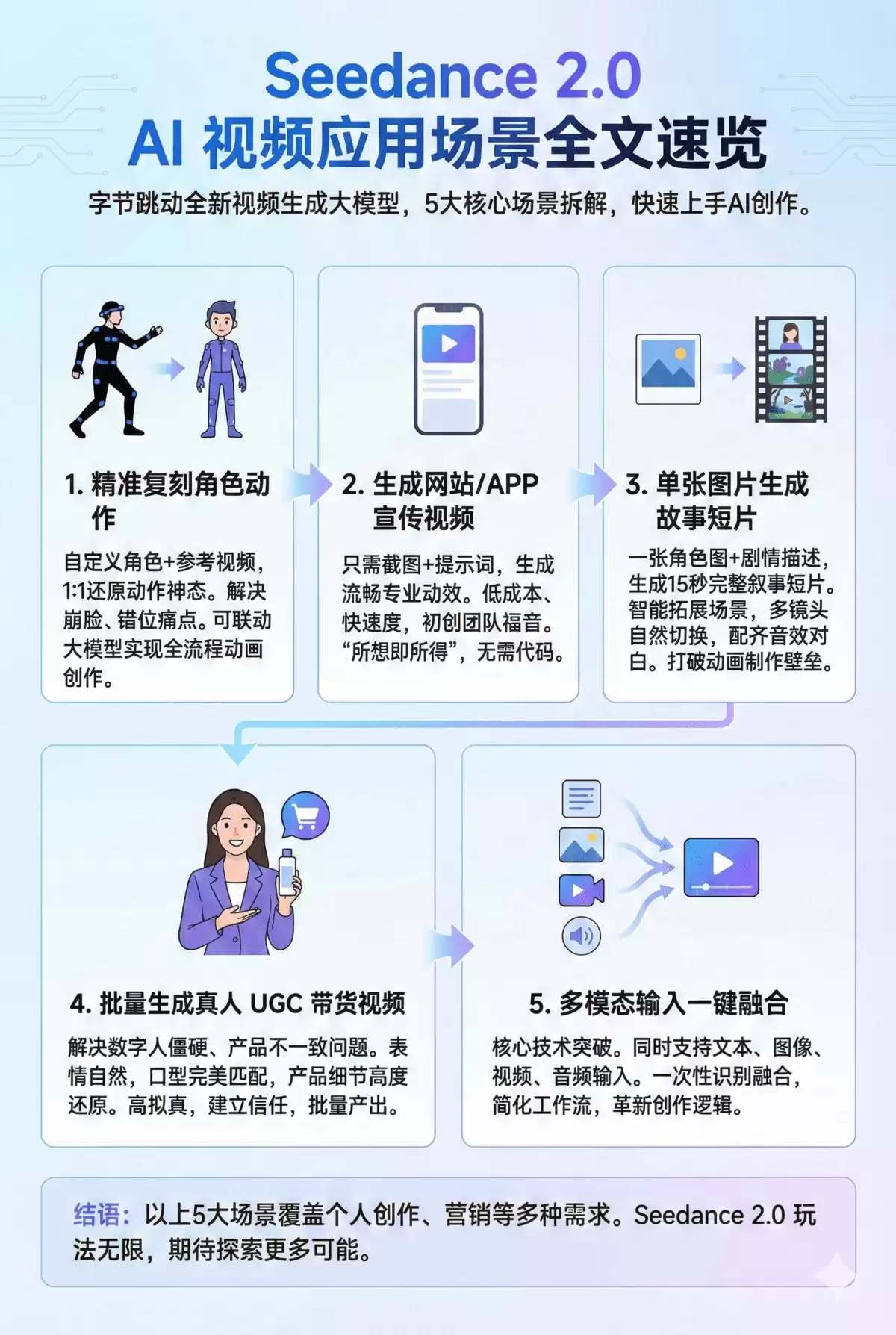
一、精准复刻角色动作
首要且最受欢迎的应用,便是角色动作的精准复刻。目前网络上广泛传播的演示视频,多数都集中展示了这一功能:用户可自定义角色与场景,并一比一还原参考视频中的动作与神态。
其操作逻辑直观高效。仅需上传一张自定义角色图、一张场景背景图,再搭配一段包含目标动作的电影或视频片段,模型便能将参考视频中的人物表情、肢体语言,无缝“迁移”至您设定的角色上。生成过程流畅自然,角色一致性保持极佳,有效解决了传统AI视频生成中常见的角色崩坏、动作错位及穿模等长期难题。
以下是一个效果演示:
更值得关注的是,它能与Kimi 2.5等大型语言模型实现高效协同。您可以先利用大语言模型构思剧本、设计分镜并生成首帧关键画面,再交由Seedance 2.0完成动作复刻与视频合成。这套完整的动画创作流程,即便没有专业背景的用户也能轻松驾驭。
二、生成网站/APP宣传视频
第二个极具商业价值的落地场景,是网站或移动应用的产品宣传视频制作。Seedance 2.0在生成产品界面动效与宣传短片方面,表现尤为出色。
您只需提供产品界面的静态截图,辅以几句清晰的创意描述,它便能自动生成一段画面流畅、动效专业、节奏把控精准的产品介绍视频。
这对于预算有限、难以聘请专业动态设计团队的初创公司或独立开发者而言,堪称降维解决方案。相较于传统视频制作流程,其生成速度更快,成本几乎可忽略不计,且AI生成的画面质感完全能满足商业宣传的基础要求。
关键在于,整个过程无需编写任何代码,不必调试复杂的动画参数,也无需反复调整关键帧。只要能够清晰表达创意构思,即可获得符合预期的宣传动画,真正实现了“创意直达成品”的高效转化。
三、单张图片生成故事短片
第三个场景,无疑是动画从业者与爱好者的福音——仅凭单张图片,即可生成一段完整的叙事短片。
仅需上传一张角色参考图,模型便能创作出长达15秒、包含多镜头自然切换、并匹配高保真人声对白与背景音乐的完整动画片段。例如下方示例:

用户只需提供一段详细的场景与剧情描述,模型便能基于参考图智能拓展出完整故事场景,自动补充与剧情高度契合的配角、道具及环境细节。其镜头语言流畅自然,有效避免了以往AI视频中常见的生硬转场与画面割裂感。
观看以下生成效果案例:
这是否意味着传统动画制作的部分技术门槛正在被打破?现在,即使您没有系统学习过动画制作,不具备手绘或关键帧调整技能,但只要拥有创意与故事,就能成为自己作品的导演与动画师。
四、批量生成真人UGC带货视频
第四个核心应用,直击电商营销与内容创作者的痛点——批量生成真人UGC风格带货视频。电商从业者深知,真人出镜的口播视频是引流与转化的关键,但传统拍摄成本高、效率难以稳定。
而此前多数AI视频模型,要么难以保证产品形态与细节的一致性,要么生成的数字人表情僵硬、口型不匹配、动作不自然,始终难以达到商用级标准。
参考下方示例:

其生成的视频效果如下:
Seedance 2.0精准地解决了这些行业痛点。它生成的真人出镜视频,人物表情生动自然,肢体动作流畅协调,口型与台词完美同步,产品细节与质感呈现也高度一致,整体观感近乎真人实拍,违和感极低。
这类高度拟真的UGC视频,能有效拉近与观众的距离,快速建立信任感,从而为产品带来显著流量。只要您能提炼产品卖点并构思创意,Seedance 2.0即可协助您批量产出高质量的营销视频内容。
您甚至可以利用它创作趣味性产品植入视频,以吸引用户关注:
五、多模态输入一键融合
最后一个场景,虽非具体案例模板,却是Seedance 2.0最核心且最具突破性的技术优势。
熟悉AI视频生成领域的用户了解,当前主流模型,无论是国内的Kling还是海外的Sora、Veo,大多仅支持有限的几种输入组合,难以实现全模态素材的同步识别、理解与深度融合。
Seedance 2.0在此实现了重要跨越。它支持在同一条指令中,同步输入文本描述、角色参考图、动作参考视频、背景音乐或人声台词。模型能够一次性解析所有素材的核心信息,精准融合各项创作指令,最终输出一段完整、连贯且符合预期的成品视频。
这意味着,所有创意素材可一次性提交,无需分步处理画面、动作与音频,也避免了在多工具间频繁切换导出的繁琐流程。这不仅大幅简化了操作步骤,更从本质上革新了AI视频创作的底层逻辑。
结语
以上便是近期总结的关于Seedance 2.0视频生成大模型的五个核心应用场景。无论是个人创作者、自媒体运营者,还是初创团队与企业营销部门,几乎都能从中找到契合自身需求的高效解决方案。
作为一款刚刚面世的尖端大模型,Seedance 2.0的潜力远未被完全发掘。它的诞生,无疑为AI视频创作领域开辟了更为广阔的可能性与想象空间。




