爱芯元智AX8850边缘AI芯片成功适配CosyVoice2大模型
今年下半年,随着业务推广需求的日益明确,我们在大模型适配方面的工作重心也发生了显著转变。不再仅仅追求将最新、最前沿的模型快速部署上线,而是更加聚焦于为一线销售团队打造真正具备“实战能力”的工具——即那些能够精准匹配客户核心需求、并可快速实现商业化落地的大模型解决方案。
因此,在接下来的技术分享中,我们将更侧重于基于我们自研的边缘AI芯片AX8850的实际应用落地,深入探讨如何帮助客户将一个个技术演示(Demo),转化为稳定可靠、可批量生产的成熟产品。
在这一过程中,离线语音智能助手无疑是一个至关重要的应用方向。
目前,实现离线语音助手的主流技术路径主要有两种:
一种是模块化组合方案,即采用ASR(自动语音识别)→ LLM(大语言模型)→ TTS(文本转语音)的流水线架构,或者使用Audio-LLM直接处理音频流后再接入TTS。
另一种是端到端一体化方案,期望通过一个全能大模型(例如Qwen3-omni)直接接收语音输入并生成语音输出。
从产品化与工程落地的角度来看,我们更倾向于推荐模块化组合方案。原因在于其优势明显:架构灵活,便于按需升级单一模块;总体拥有成本更低,投资回报预期更清晰;同时,它也更容易根据不同客户的特定业务场景进行深度定制与优化。
在组合方案中,TTS是让整个系统“开口说话”的最终环节,也是赋予机器设备“人性化”交互体验的关键。我们自然希望它不仅能高质量地合成语音,最好还能支持个性化语音克隆功能,让智能助手能够使用特定、亲切的音色与用户进行交流,从而提升用户体验与亲和力。
目前,在开源社区中,支持语音克隆的TTS模型已有不少优秀选择,例如阿里的CosyVoice 2、IndexTTS2、VoxCPM等。今天,我们将首先带大家快速了解,我们将CosyVoice 2成功部署到AX8850芯片平台上的最新进展。希望能为那些希望在边缘计算侧实现高质量语音克隆功能的开发者,提供一个切实可行的技术选型参考。
CosyVoice2:一体双模,流式与离线兼备
CosyVoice 2是阿里巴巴通义实验室推出的开源多语言语音生成大模型,核心功能是文本转语音(TTS)。它在上一代基础上进行了系统性优化,其最突出的亮点在于:在流式(实时)合成模式下,其语音生成质量几乎可以达到与真人语音相媲美且无损的水平,同时显著降低了端到端的响应延迟。
简而言之,它既能实现“边接收文本边合成”的实时交互,又能保证合成语音的自然度与高保真度。
其模型架构延续了将语音的“语义内容”与“声学特征”分离处理的先进思路,主要由三个核心组件构成:
1. 监督式语义语音分词器
该模块基于一个强大的ASR模型(SenseVoice-Large)改造而成。它采用了一种名为“有限标量量化”(FSQ)的技术,能够将连续的语音信号,高效地离散化为一系列代表语义的语音标记(speech tokens)。相比传统的向量量化方法,FSQ的码本利用率更高,能更有效地捕捉和保留语音中的丰富信息。
2. 统一的文本-语音语言模型
这是CosyVoice 2的一项核心创新,它实现了流式合成与非流式(离线)合成的“架构统一”。模型直接采用一个预训练好的大语言模型(Qwen2.5-0.5B)作为主干网络,摒弃了前代模型中独立的文本编码器和说话人嵌入模块,使得结构更加简洁,同时增强了上下文理解能力。
其巧妙之处在于训练策略:
- 流式模式下,文本以数据流的形式分段输入。模型在训练时,会将N个文本标记与M个语音标记按特定比例(例如5:15)混合。当模型预测到一个特殊的“填充标记”时,系统便知晓需要接收下一段文本,从而实现边接收、边生成语音标记的实时处理流程。
- 非流式模式下,则是将完整的文本序列和语音标记直接拼接,进行一次性并行生成。
通过让同一模型同时学习这两种生成模式,CosyVoice 2真正做到了“一个模型,两种模式”的灵活切换,并且确保了流式合成下的音质几乎不产生损失。
3. 块感知因果流匹配模型
这个模块负责将上游生成的语义语音标记,转换为包含音色、韵律、节奏等细节信息的梅尔频谱图。它基于“流匹配”这一先进的生成式建模技术,属于非自回归生成模型。
为了支持流式合成,它设计了一个因果卷积Transformer UNet结构,并引入了四种不同的注意力掩码策略:从完全非因果(性能最优,适用于离线合成),到完全因果(延迟最低),再到两种折中的“分块”掩码(在延迟和性能之间取得平衡)。训练时随机选择掩码策略,使得单一模型就能灵活适应从低延迟流式到高质量离线的各种应用场景,极大地简化了部署的复杂性。
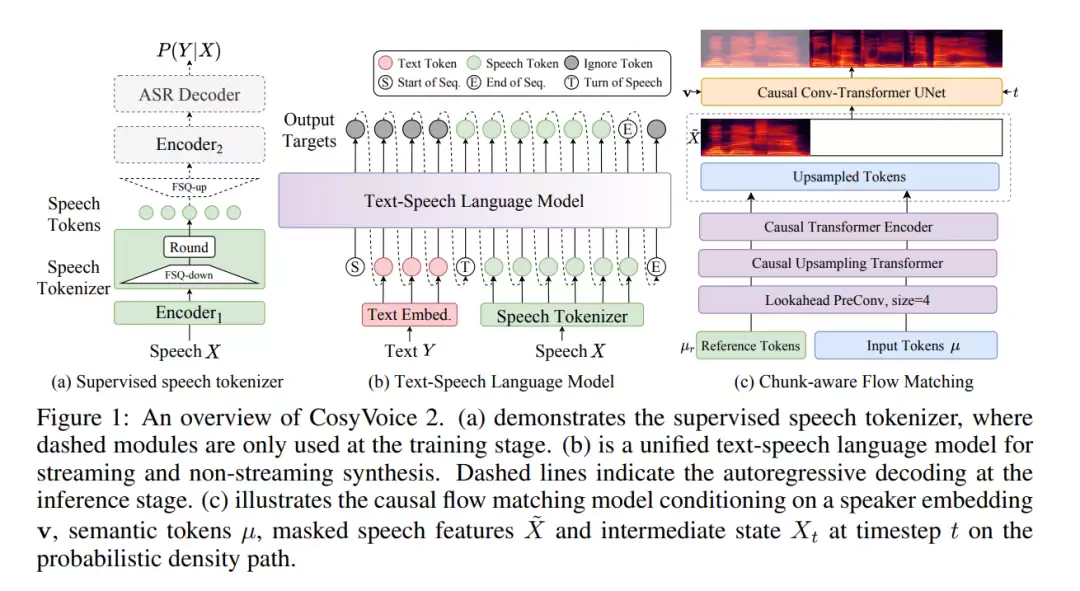
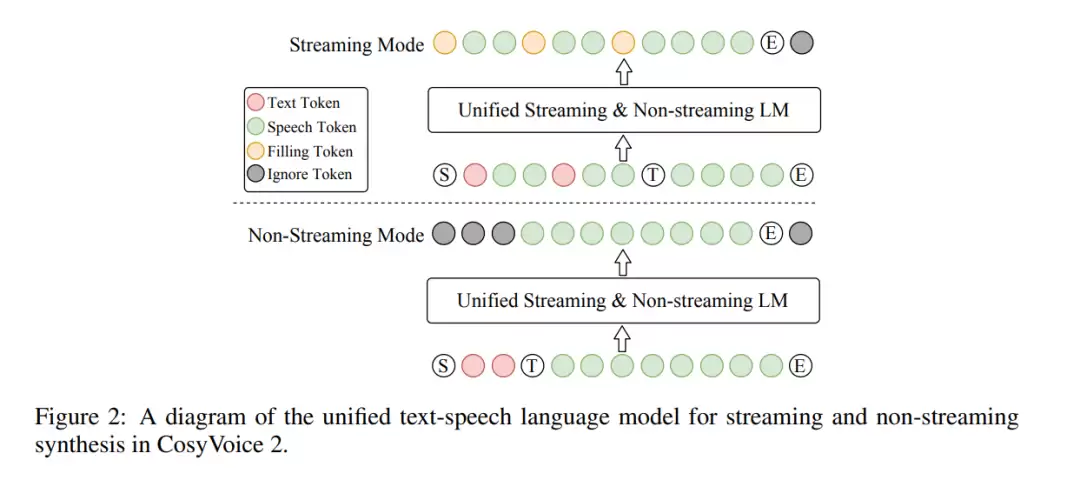
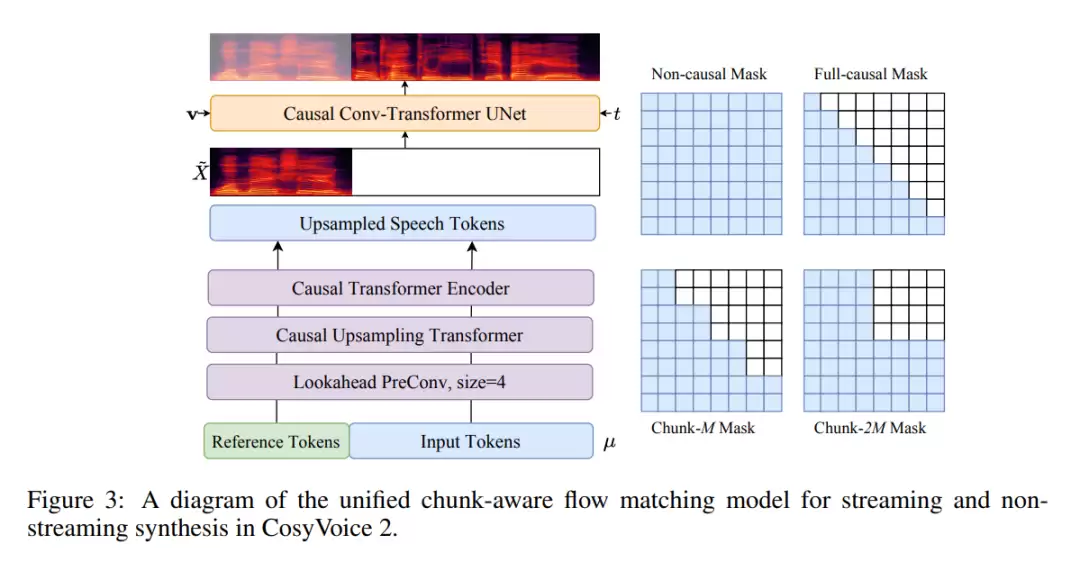
总结来说,CosyVoice 2通过FSQ技术提升语音编码效率,利用统一的LLM架构打通流式与非流式生成路径,再借助块感知的因果流匹配模型支持灵活高效的声学特征合成,最终构建出了一个兼具高质量、低延迟且易于部署的先进语音合成系统。
实战部署:在边缘设备上运行CosyVoice 2
为了便于在广大开发者社区中进行技术演示与推广,我们选择了生态极为成熟的树莓派5(Raspberry Pi 5),搭配我们的AXCL算力卡作为演示平台。当然,基于AX8850芯片的官方社区开发板同样可以完成部署,此处不再赘述。
假设您已具备访问HuggingFace等模型仓库的网络条件。
硬件准备
您可以选择以下两种硬件搭配方案:
方案一:树莓派5 + LLM8850-Card(M.2接口算力卡)

方案二:树莓派5 + Maix4-HAT(算力模组)

软件部署步骤
首先,请确保已按照相应硬件产品的指导文档,完成了必要的驱动安装(例如AXCL驱动包)。
我们已经将预编译好的优化模型和完整的示例程序上传至HuggingFace平台(及国内镜像站)。
如果您想了解如何将原始PyTorch或ONNX模型转换为能在AX平台高效运行的axmodel格式,可以参考我们GitHub仓库中的详细转换流程。但需要提醒的是,此过程相对复杂,除非您确有对模型进行微调(Finetuning)的特定需求,否则建议初学者直接使用我们提供的预编译版本,以获得更高的部署效率。
1. 获取示例代码与模型
pip install huggingface_hub
export HF_ENDPOINT=https://hf-mirror.com
huggingface-cli download AXERA-TECH/CosyVoice2 --local-dir AXERA-TECH/CosyVoice2
2. 安装Python依赖包
cd AXERA-TECH/CosyVoice2
pip install -r scripts/requirements.txt
pip install modelscope
modelscope download --model pengzhendong/wetext --local_dir pengzhendong/wetext
3. 运行示例程序(以Gradio WebGUI为例)
首先,启动分词器(Tokenizer)服务:
cd scripts
python cosyvoice2_tokenizer.py
接着,运行基于AXCL加速库的推理API程序:
cp onnxruntime-Linux-aarch64-1.23.0/lib/libonnxruntime.so.1.23.0 libonnxruntime.so.1
./run_axcl_aarch64.sh
最后,启动Gradio交互式Web界面:
python scripts/gradio_demo.py
完成上述步骤后,使用浏览器访问命令行提示的本地地址(通常是 https://127.0.0.1:7860),即可看到一个简洁的语音克隆与合成操作界面。
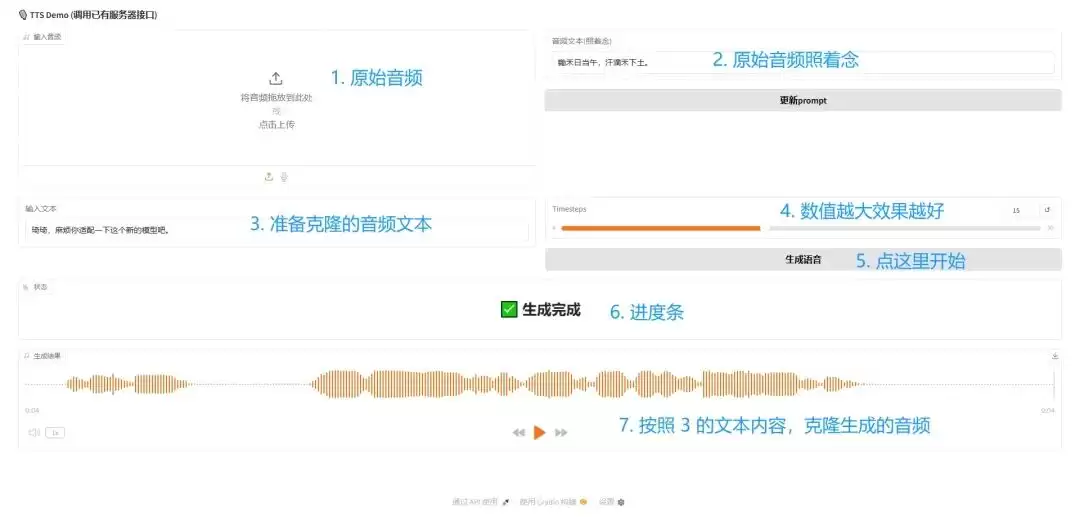
根据我们的性能测试,在AX8850开发板上,其实时性因子(RTF)大约在1.5左右;若使用M.2算力卡,RTF则可达到2.5左右。这一性能表现足以满足大多数对实时性要求并非极端苛刻的离线语音交互场景。如果您追求RTF低于0.1的极速TTS响应,并且对音色自然度的要求相对宽松,可以关注我们另一个刚刚完成适配的轻量级语音合成模型Kokoro。
拓展了解:FunAudioLLM开源生态
阿里巴巴通义实验室除了打造了广为人知的通义千问大模型,还开源了许多有趣且实用的项目。FunAudioLLM便是其中一个专注于语音生成领域的大模型项目集合。
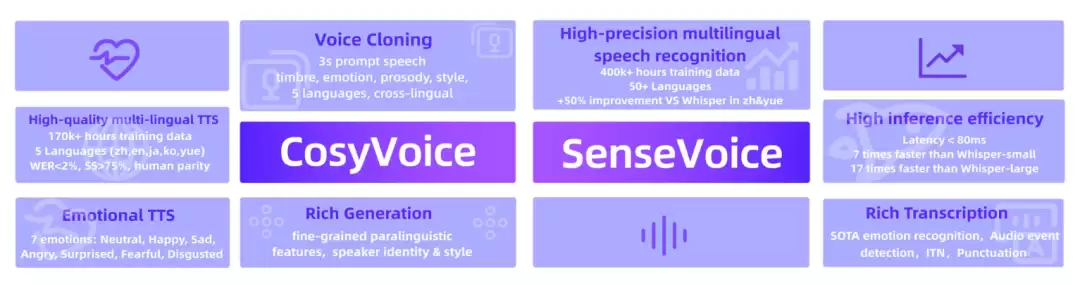
它并非单一模型,而是一个集成了语音识别(SenseVoice系列)与语音合成(CosyVoice系列)两大核心能力的开源工具套件。其目标是构建一个完整的端到端智能语音生成系统,实现从“精准听懂”到“自然说好”的全链路闭环,特别适用于智能客服、有声内容自动生成、实时语音翻译、会议纪要生成等需要自然、富有情感的人机语音交互场景。关于其中的SenseVoice语音识别模型,我们将在后续的文章中单独进行详细的技术解读与应用分享。
相关攻略

今年下半年,随着业务推广需求的日益明确,我们在大模型适配方面的工作重心也发生了显著转变。不再仅仅追求将最新、最前沿的模型快速部署上线,而是更加聚焦于为一线销售团队打造真正具备“实战能力”的工具——即那些能够精准匹配客户核心需求、并可快速实现商业化落地的大模型解决方案。 因此,在接下来的技术分享中,我

MY VOICE AI产品介绍 在语音人工智能的快速发展中,安全性与实时响应能力已成为行业竞争的核心焦点。My Voice AI作为一家前沿的创新企业,精准地瞄准了这一关键需求。公司致力于构建一个覆盖端到端全流程的安全语音智能平台,其推出的首款核心产品——NanoVoiceTM,展现了独特的技术优势

什么是Voice Design? 如果你正在为视频制作、游戏开发或有声读物寻找独特且富有表现力的AI语音,那么ElevenLabs推出的Voice Design工具,正是你理想的解决方案。它不仅仅是一个传统的“语音生成器”,更是一个革命性的“语音设计师”——你无需从有限的预设库中挑选,只需输入一段简

谈到语音合成技术,许多人会联想到智能助手Siri或各类有声阅读应用。然而,在这一领域持续深耕、真正从底层推动行业进步的团队中,voice ai无疑是其中的佼佼者。这家由语音合成技术长期先驱团队创立的人工智能企业,在创始人兼首席执行官Heath Ahrens的引领下,始终秉持一个清晰的目标:彻底重塑人

Voicebox是什么 如果你正在寻找一款功能强大且将数据安全完全掌控在本地的语音合成软件,那么Voicebox无疑是你的理想选择。这款开源的本地语音合成桌面应用,采用Tauri(Rust)和React技术栈构建,天生具备跨平台特性。它的核心优势在于:声音克隆、文本转语音(TTS)、音频后期处理以及
热门专题







热门推荐

比特币转错地址后,交易确认即难以撤回,资金可能永久损失。若地址无效转账会被拦截;若转入陌生地址,资产由对方控制,追回困难。补救措施包括:交易未确认时可尝试RBF撤销;转入主流交易所可联系客服;转入个人地址则只能尝试联系持有人。法律追索困难,且需警惕诈骗。预防是关键,应养成小。

智能化内容创作:AI一键将Word转为PPT,办公效率革命 在快节奏的现代职场中,如何高效处理文档、将复杂信息转化为专业演示,是提升个人与团队生产力的关键。本文将深入解析智能化内容创作如何革新工作流,并重点介绍如何利用先进的AI工具,实现从Word文档到精美PPT的智能、快速转换,助您轻松应对各类汇

QoderWake移动端已上线,提供APK下载及核心功能。界面针对触控优化,采用卡片布局与手势操作,适配主流安卓设备。内置轻量级Agent运行时,可独立执行原子任务。通信经平台网关加密中转,确保安全。支持多账号切换与工作空间隔离,安装包小巧、绑定简便,可同步近期任务。具备跨端协同、远程调试、任务接管等功。

PowerBI与Tableau是主流数据可视化工具。PowerBI依托微软生态,侧重与Office集成及标准化报表,适合企业协作与稳定分发。Tableau擅长交互探索与视觉表达,适合深度数据分析和制作动态故事板。两者在定位、学习曲线、数据处理和可视化方面各有侧重,选择需结合团队需求、数据环境及使用场景。

《无尽噩梦7幻梦》开放预约,游戏以东方玄幻为背景,玩家扮演捉鬼师探索梦境与现实。玩法融合探索解谜与多流派技能搭配,强调策略性。虚幻引擎提升画面沉浸感,并加入团队副本与社交功能,提供高清国风恐怖体验。