上海交大突破视觉语言模型空间感知 0.9B参数实现90%真机成功率
机器人视觉感知的精度不足,是当前视觉-语言-动作模型普遍面临的核心挑战。许多模型仍主要依赖二维图像信息,在执行需要精确定位、细微操作或复杂空间关系判断的任务时,成功率往往难以保证。
要弥补空间感知能力的短板,业界通常有两种主流方案,但各自存在局限。显式3D方法依赖深度相机与点云重建,硬件链路复杂且对设备标定精度极为敏感;隐式3D方法则尝试从RGB图像直接学习几何信息,虽免去了额外硬件,但许多方案依赖参数量巨大的基础模型,导致训练与推理成本高昂。
为此,上海交通大学MINT实验室团队创新性地提出了一条高效的中间路径:Evo-Depth。这个参数量约0.9B的模型,无需增加任何硬件负担,而是通过一种紧凑的隐式深度编码技术,将三维空间感知能力无缝集成到VLA模型的决策流程中。在仿真与真实机器人测试中,它实现了性能与效率的出色平衡。

实验结果表明,该模型在主流仿真基准测试中表现优异:在Meta-World任务上达到84.4%的成功率,在LIBERO任务上更是取得了95.4%的高成功率。部署至真实机器人平台后,其平均任务成功率仍能稳定在90%左右。更值得关注的是其轻量级部署优势:仅需约3.2 GB的GPU显存,推理速度可达约12.3 Hz,完全满足实时控制要求。
目前,该项目的代码、模型权重及完整训练脚本均已全面开源。
轻量化设计与端到端训练策略
Evo-Depth的核心设计目标明确:从多视角RGB图像中提取轻量化的隐式深度特征,并将其高效融入视觉-语言理解通路,最终通过一个基于流匹配的动作生成模块,输出精准、连续的操作指令。
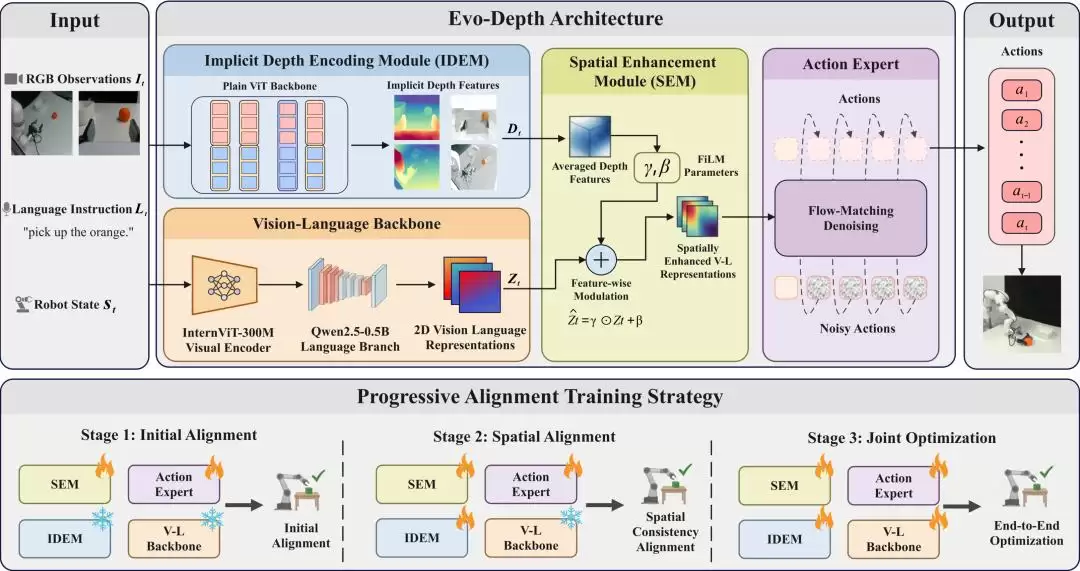
整个系统架构主要由三个关键组件构成:
1. 隐式深度编码模块
该模块负责从多视角图像中学习并提取隐式的深度表征。其设计重点并非生成高成本的显式3D中间表示,而是高效捕捉场景的空间布局与物体间的相对几何关系。为实现轻量化,该模块主干网络参数量控制在约0.13B,并借助多视角深度预训练进行初始化,从而在有限参数下引入了关键的几何先验知识。
2. 空间增强模块
该模块的作用是将隐式深度特征作为一种调制信号,来增强视觉与语言的联合表征。这种融合方式比增设独立的深度处理分支更为高效:原有的视觉语言模型继续专注于语义理解,而深度特征则专门提供空间信息的补充。这种分工协作的设计,在提升模型空间感知能力的同时,有效控制了计算延迟与内存开销。
3. 渐进式对齐训练流程
为了解决多模块联合训练时常见的优化不稳定问题,研究团队采用了渐进式对齐训练策略。训练过程分为三个阶段:首先对齐深度表征,然后进行多模态特征融合,最后学习具体的动作策略。这种分步训练方法显著提升了训练的稳定性与最终性能。动作生成部分则采用了当前VLA领域先进的流匹配技术。
在总计约0.9B参数的配置下,模型取得的综合性能如下:
仿真基准测试结果: Meta-World任务成功率84.4%,VLA-Arena任务成功率41.1%,LIBERO任务成功率95.4%,LIBERO-Plus任务成功率69.6%。
真实机器人部署表现: 平均任务成功率约为90%。
实际部署指标: 约需3.2 GB GPU显存,推理频率约12.3 Hz。
需要特别指出的是,除了关注基准测试分数,该研究也明确给出了实际部署所需的资源开销与实时性指标。对于最终需要嵌入机器人实时控制回路的VLA系统而言,这些部署可行性数据的重要性,丝毫不亚于任务成功率本身。
在性能、成本与实时性间寻求最佳平衡
本质上,Evo-Depth旨在解决一个非常实际的工程问题:如何在不大幅增加系统整体复杂度和成本的前提下,显著提升VLA模型对三维空间的感知与理解能力。
从结果来看,它确实找到了一种巧妙的平衡点:相较于纯二维的VLA模型,它补充了关键的空间几何信息;而与那些依赖显式3D重建或庞大规模基础模型的方案相比,它又最大限度地保持了系统的部署效率和实用性。
对于专注于机器人灵巧操作、空间人工智能或VLA系统开发的团队而言,这类在模型性能、硬件成本与系统实时性之间取得精妙折中的方案,其应用价值正日益凸显。在追求更高层次智能的同时,如何让先进算法真正实现高效、稳定的落地应用,始终是机器人技术工程化道路上必须攻克的核心难题。
相关攻略

机器人能够“看见”世界,但如何让它们“看准”并精准操作,一直是视觉-语言-动作模型面临的核心挑战。 当前,大多数VLA模型主要依赖二维图像信息进行决策。一旦任务涉及精确抓取定位、精细物品摆放或需要理解复杂的物体间遮挡关系——这些对三维空间感知要求极高的场景,模型的成功率往往会显著下降。 为机器人模型

当前视觉-语言-动作模型普遍缺乏空间感知能力。上海交通大学团队提出轻量级模型Evo-Depth,通过隐式深度编码将空间信息融入策略,无需额外硬件。该模型参数约0 9B,在仿真与真机测试中成功率分别达84 4%与90%左右,仅需约3 2GB显存,兼顾了性能与部署效率。

上海交大团队联合企业提出MMSkills框架,使AI能结合视觉信息执行任务。该框架提供图文并茂的“技能包”,包含操作流程、状态卡片和关键画面参考图,指导AI“看什么”及“何时做”。团队还设计了分支加载机制,让AI在运行时智能筛选视觉证据,避免信息过载。测试显示,使用该框架后,多个AI模型在办公软件和游戏等。

上海交通大学等机构提出MMSkills框架,使AI助手能结合视觉信息执行任务。该框架整合操作流程、状态卡片与多视角参考图,形成可迁移的多模态技能包,并通过分支加载机制智能调用技能、实时对齐屏幕。实验显示,该方法可显著提升AI在办公、游戏等视觉任务中的成功率和效率,减少无效操作。

在大模型技术浪潮席卷全球的今天,如果您的企业仍将人工智能局限于“智能聊天”或“文案生成”的层面,可能已经错失了技术演进的关键窗口。真正的产业变革拐点已然降临。当领先企业开始部署能够自主决策、协同工作的“数字员工”团队时,许多组织仍在探索AI与核心业务场景深度融合的有效路径。 为此,一场由上海交通大学
热门专题







热门推荐

2025年底智能驾驶国标要求,使4D毫米波雷达成为特定安全场景的关键传感器。法规明确的测试场景如远距离静止目标、隧道事故等,恰好是摄像头和激光雷达的能力盲区,凸显其不可替代价值。行业技术路线多元化,边缘与中央架构将长期并存。产业链正从供应商模式转向联合创新,中国在量产速。

梅尔维娅是《芙娅之魂》中的锻造师,负责“余烬”养成系统。玩家通过她将余烬解析并绑定至武器,以解锁战技与词条。不同余烬适配不同属性武器,如雷系余烬可召唤雷电区域并降低敌人雷抗。每件武器仅能绑定一个余烬,且需属性匹配方可生效。

智谱清影生成古风视频时,需通过精准指令确保风格纯粹。可采用四种方法:使用结构化提示词明确镜头、场景与风格;利用图生视频功能配合动态描述与风格锁定;直接调用内置古风模板简化操作;生成后手动干预关键帧,局部修正以强化古风质感。

家用投影仪凭借沉浸式体验和空间灵活性成为家庭显示的重要选择。2026年市场竞争聚焦核心技术、画质与场景适配。选购需关注亮度、画质、空间与性能四大维度。当贝旗下三款机型精准满足不同需求:S7UltraPro提供顶级专业影院画质;X7Max兼顾客厅观影与游戏娱乐;D7XPro则以高性价比和强大空间适应性,成为小户。

苹果M6MacBookPro预计2026年第四季度发布,将采用覆盖主板的均热板散热技术,取代传统单热管方案,配合优化风道与风扇,显著提升散热效率。该机型搭载2纳米制程芯片,配备OLED触控屏,旨在确保高性能持续释放,但起售价预计将明显上涨。