
近期,谷歌对其AI模型矩阵进行了重要升级,其中Gemini 2.0 Flash(图像生成版)的正式发布,为设计师和内容创作者带来了极具实用价值的工具。
该模型现已开放API接口,能够轻松集成到ComfyUI工作流中。实际体验后,其生成效果与可控性确实令人印象深刻。
可能部分用户对Gemini 2.0 Flash还不太了解。简而言之,该模型最初于2024年12月作为实验项目推出,经过数月测试与优化,已于今年3月全面开放使用。其核心功能是通过自然语言指令生成或编辑图像,拥有出色的可控性,这与ComfyUI通过节点工作流精确控制生成过程的理念高度契合。
强大的可控性意味着它在实际工作场景中能发挥巨大作用。这也解释了为何当下许多一线公司(例如腾讯)已将掌握ComfyUI列为团队核心技能要求之一,目的正是通过可视化工作流高效解决复杂的图像生成与编辑需求。
如何使用Gemini 2.0 Flash图像生成模型?
使用方法非常简便。首先,访问谷歌AI Studio的官方网站。
在模型选择列表中,找到“Gemini 2.0 Flash (Image Generation) Experimental”即可开始体验。
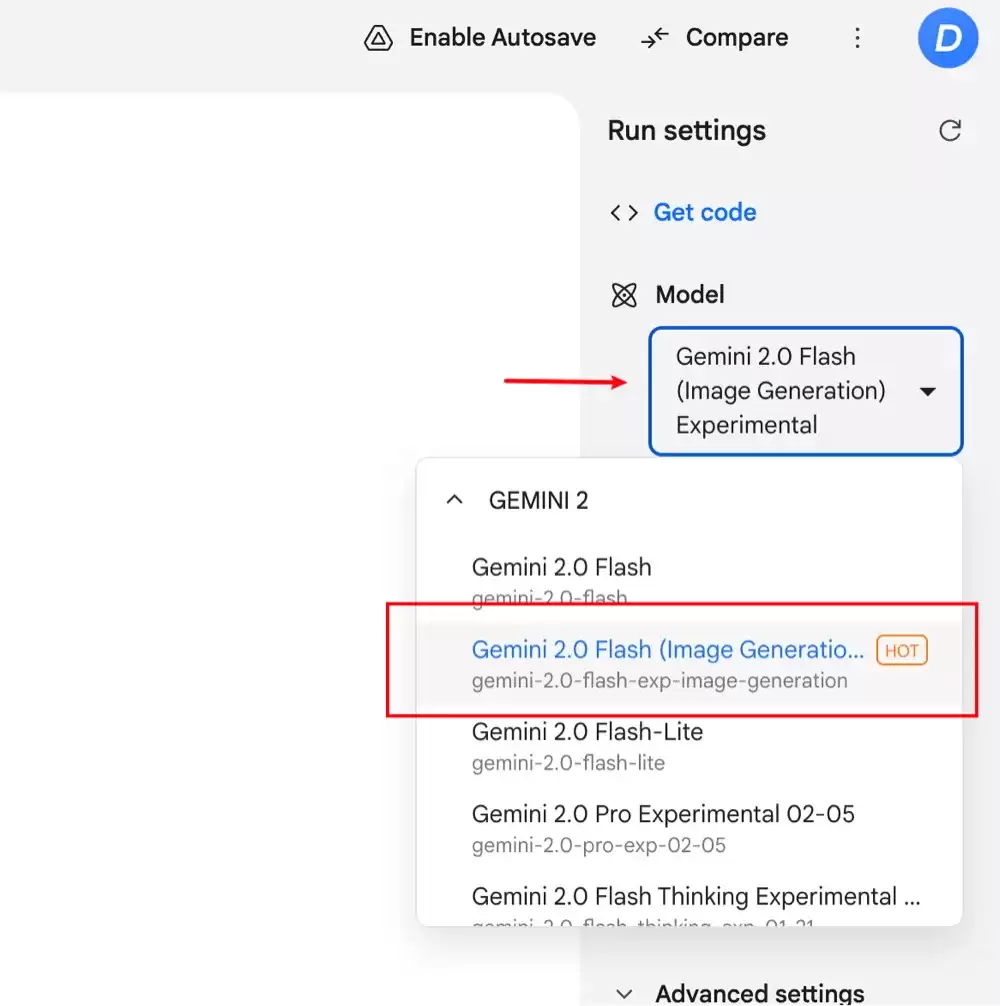
页面提供了三个基础功能示例,点击即可快速了解模型的核心玩法与应用场景。
下面我们快速解析这几个官方演示案例:
1. 智能图片编辑
使用最直白的语言指令即可修改图片。例如,输入提示词“给牛角面包撒上巧克力碎”,模型便能精准识别并执行。
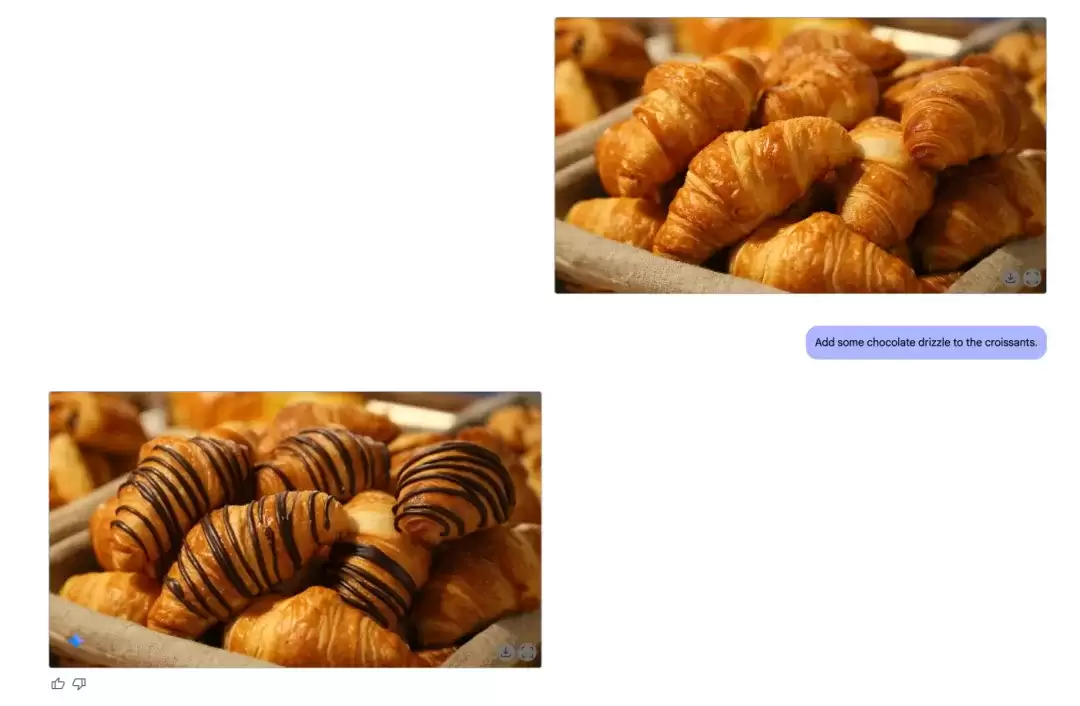
你还可以进行连续对话式编辑,例如接着说“在图片顶部添加一些奶油”,若觉得效果不足,可进一步补充“奶油再多加一些”。

其生成效果精准可控,基本不会破坏原始图片的构图与风格基调,类似于在Photoshop中进行非破坏性编辑,实用性极强。毕竟,AI修图最令人担忧的就是修改后图片面目全非,因此可控性至关重要。试想,当下次接到修改需求时,直接让需求方将想法转化为文字描述,一分钟内即可预览效果,极大提升沟通效率。
2. 自动生成图片故事绘本
你可以指令模型生成一个完整的故事脚本,并自动为每个场景配图,同时确保主角形象与艺术风格全程保持一致。
官方示例的提示词是:“生成一个关于小山羊在农场冒险的故事,并为每个场景生成一张配图。”点击生成后,模型会快速输出包含9个场景的完整故事,每个场景都配有风格统一的插图,效果相当惊艳。
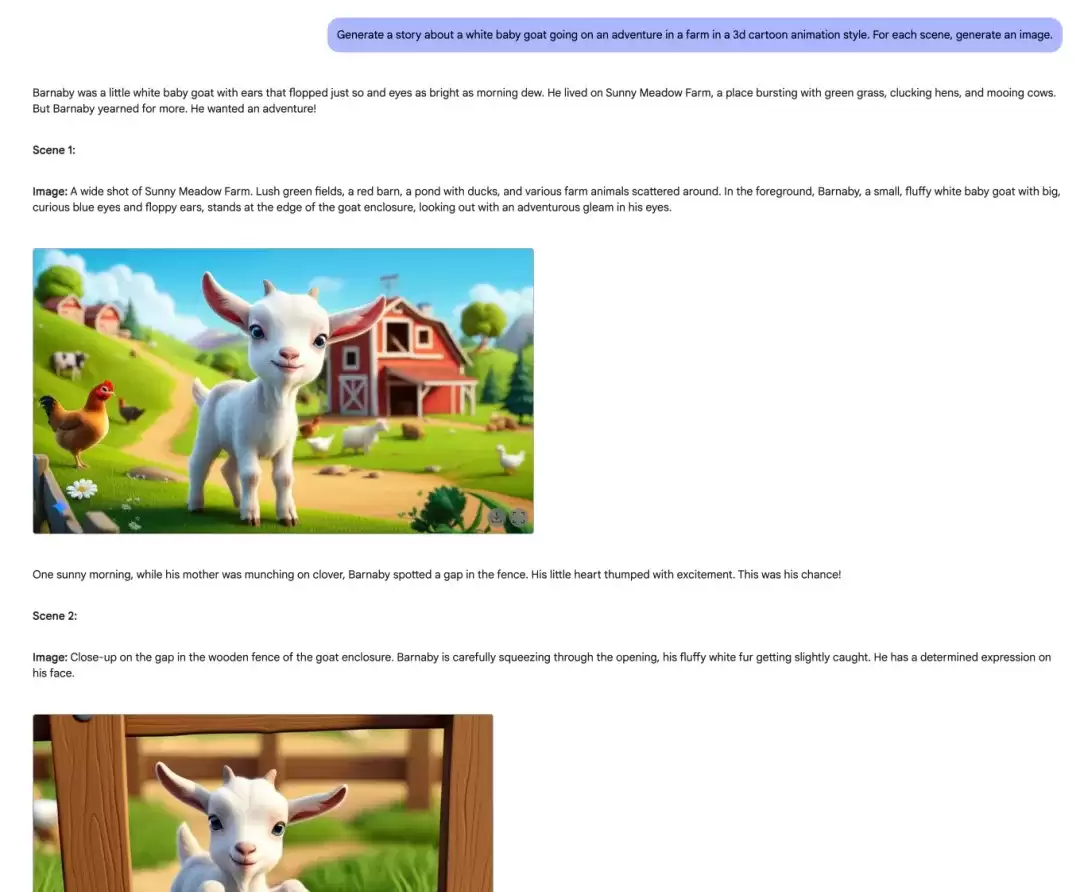
此功能显著降低了个性化视觉内容创作的门槛。
3. 定制化生日卡片生成
模型还能通过简单的对话,生成一张包含正确祝福文案的生日贺卡或海报,成品可直接用于发送,毫无违和感。

以上官方示例上手门槛极低,亲自尝试即可快速掌握。然而,接下来要介绍的进阶用法,才是该模型真正释放潜力的关键——通过API将其接入ComfyUI工作流。
许多用户曾因电脑配置限制,对ComfyUI望而却步。如今,借助谷歌这一新模型的API,只要你的电脑能够启动ComfyUI,无论显卡性能如何,都能通过工作流快速实现复杂的图像生成与编辑效果,这从根本上解决了硬件配置的核心痛点。
如何在ComfyUI中接入Gemini 2.0 Flash API?
首先,请确保你的ComfyUI已经成功安装并可以正常运行。
接着,打开ComfyUI的插件管理器(Manager),搜索并安装名为“Gemini-API”的节点插件。安装完成后,重启ComfyUI即可生效。
如果你还需要实现基于两张图片的融合生成等高级功能,可以额外安装“ComfyUI Gemini Flash”这个节点插件。
然后,在ComfyUI的主画布上双击,搜索“gemini”,将对应的生成节点拖拽到工作区中。
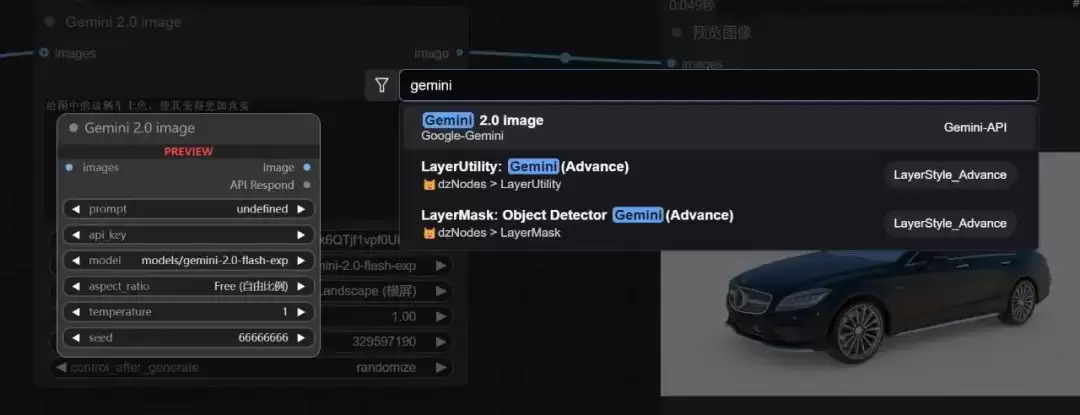
将需要处理的图片连接到节点的前端输入口,将节点的输出端连接到图片预览节点,基础链路便搭建完成。
但在运行工作流之前,还需要一个关键的“api_key”(API密钥)。这个密钥需要回到谷歌AI Studio的页面获取。
在页面左上角找到“Get API key”按钮,点击并创建一个新的API密钥。
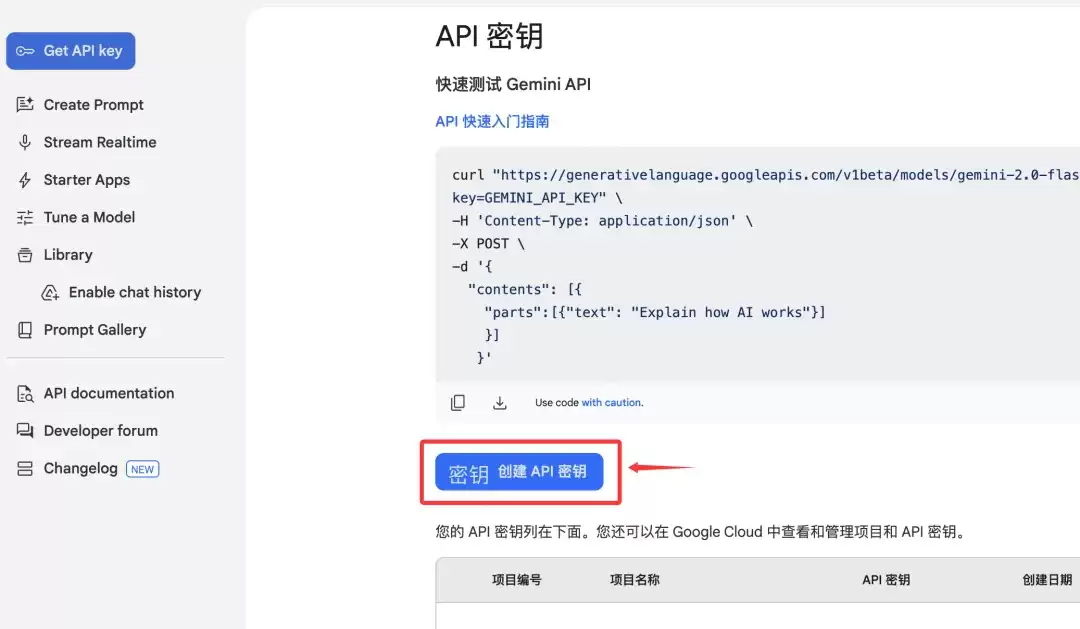
创建成功后,复制这串密钥字符串。
将其粘贴到ComfyUI中刚才创建的Gemini节点的“api_key”输入框内。
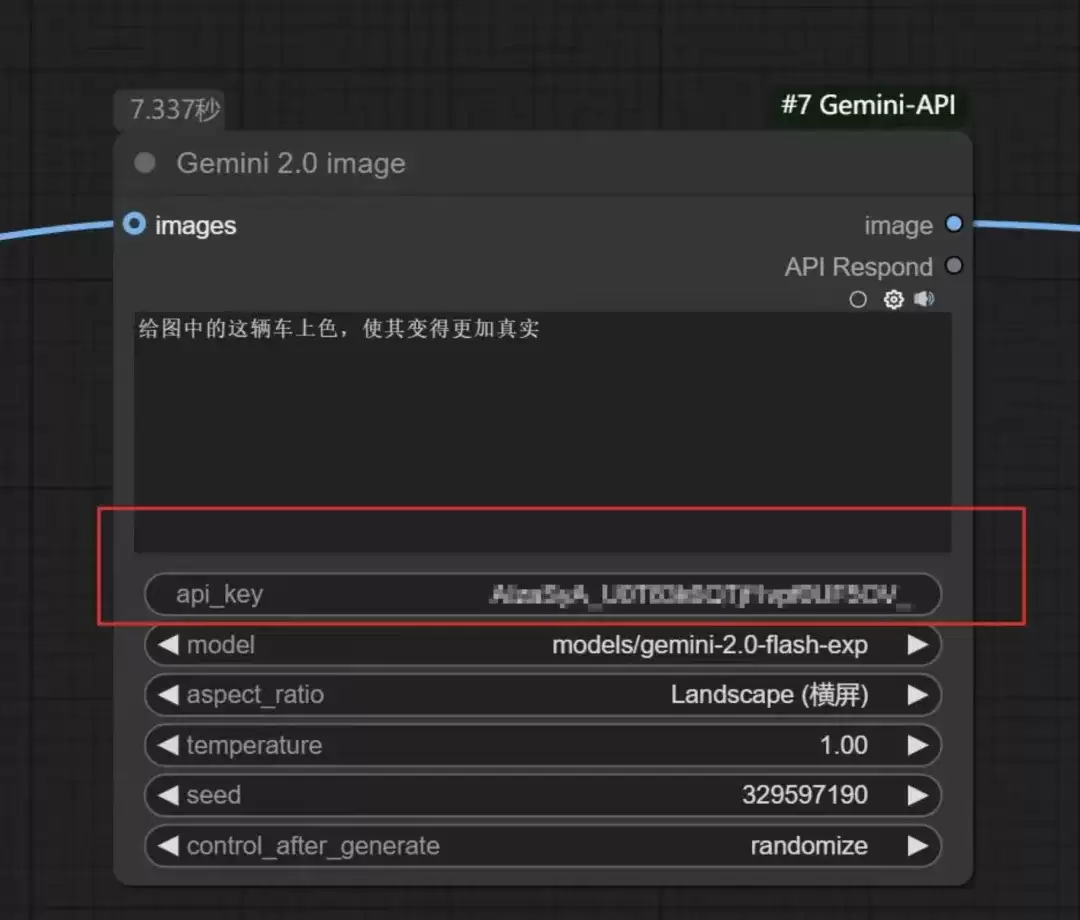
至此,所有配置步骤完成,整个过程并不复杂。
接入ComfyUI后的进阶应用场景
当Gemini 2.0 Flash与ComfyUI的强大工作流结合后,所能实现的花样便非常丰富了。这相当于将过去可能需要多个复杂节点组合才能完成的效果,现在通过一个节点就能高效实现。以下列举几个实用案例,更多的可能性等待大家共同探索。
① 智能去除图片水印
例如,找到一张带有水印的汽车白模图,希望去除水印。将图片输入节点,并给出提示词:“去除这张图片中的水印,只保留汽车主体。”

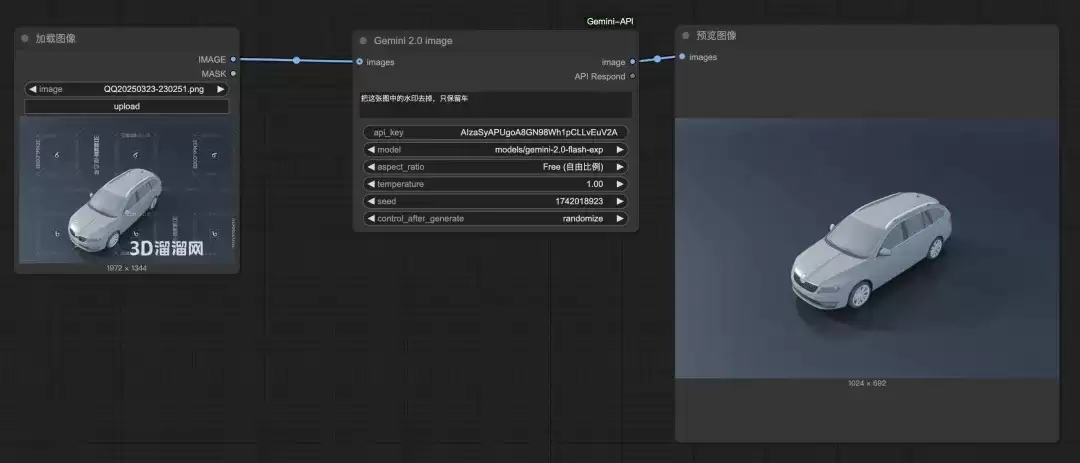
生成结果不仅干净地移除了水印,还优化了车辆的构图与光影,整体图片的清晰度与质感均得到提升。

② 一键上色与背景替换
获得干净的白模图后,可以继续指令模型使其变得更真实。提示词可以这样编写:“为图中的汽车上色,使其看起来更真实美观,汽车行驶在户外的公路上,道路两旁有山林,请保持汽车的视角与特征不变。”
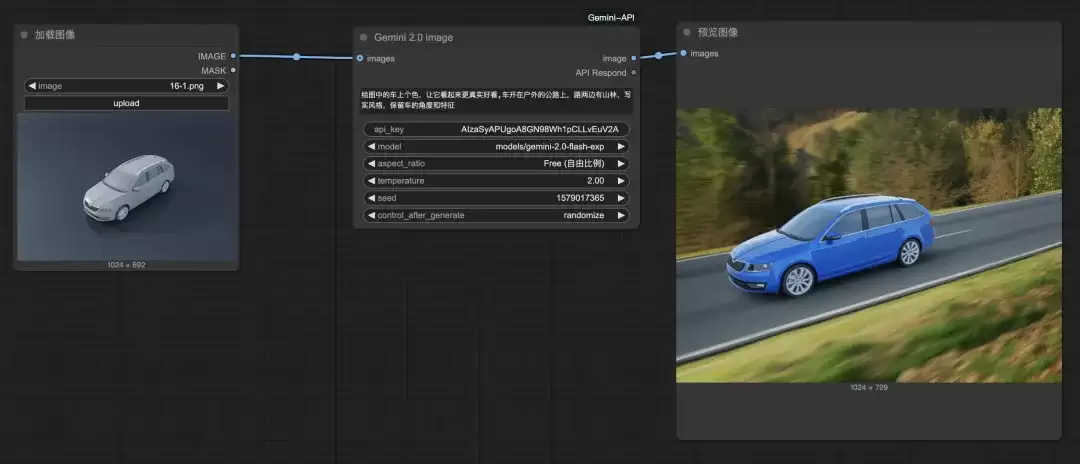
生成结果基本继承了原图的主要特征,并同步完成了高质量上色与背景环境替换。

③ 电商模特快速换装
这在电商领域极具实用价值。输入一张模特图,提示词为:“为这位模特更换一件白色衬衫。”

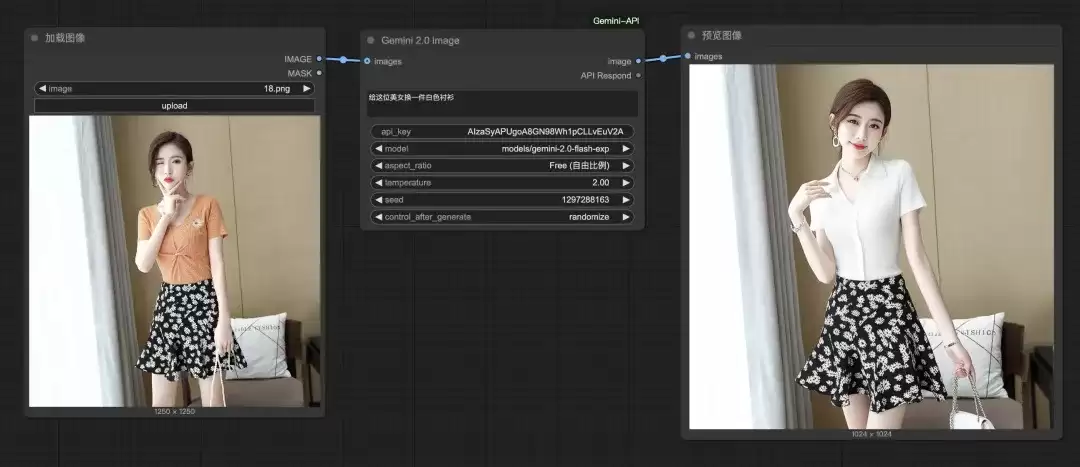
生成后,模特的服装已成功更换,虽然姿势可能有细微调整,但人物的面部特征、发型及背景都得到了很好的保留。

④ 为产品生成营销广告图
假设有一件服装产品需要制作宣传图。输入产品平铺图,提示词为:“为这件衣服添加一个儿童模特,生成一张适用于电商平台的广告图,请保持衣服的款式、颜色与纹理一致。”


⑤ 精准调整人物表情
过去在ComfyUI中精细调整人物表情可能流程繁琐。现在接入此API后,过程变得极其简单,且人物身份特征保持度极高。例如,让一张图中的“哪吒”角色笑起来。
提示词:“让图片中的人物开怀大笑,嘴巴需要张开,保持人物的发型、服饰等所有特征不变。”

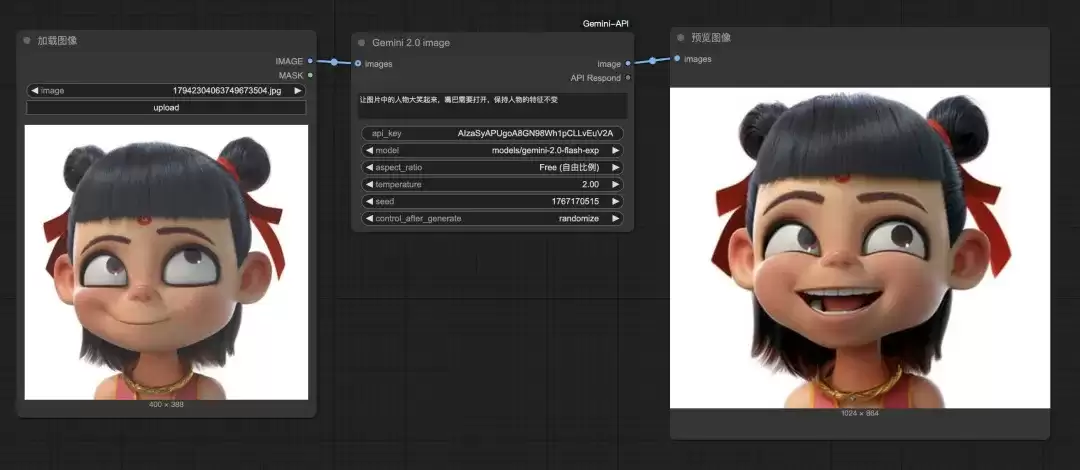
修改结果如下,表情生动自然,角色特征依旧清晰可辨。

当然,上述所有操作,你也可以直接在谷歌AI Studio的网页对话框内完成。但ComfyUI的核心优势在于,当需要进行批量图片处理、复杂条件控制或流程化自动化操作时,其节点化的工作流方式将更加高效与灵活。
AI技术的发展,始终朝着降低技术使用门槛、赋能更多创作者的方向演进。ComfyUI本身具有一定的学习曲线,曾让部分初学者犹豫。而如今,像Gemini 2.0 Flash这样通过API提供强大图像生成与编辑能力的模型,正是“化繁为简”趋势的生动体现。只是这个技术普惠的进程,比许多人预期的来得更为迅速。
在这个日新月异的AI时代,保持对前沿技术的关注、积极动手尝试、并持续学习与适应,或许是我们把握机遇、应对变化的最佳方式。




