数字人视频生成技术迎来重大突破。美团技术团队正式开源了其LongCat-Video-Avatar模型的1.5版本,标志着该技术从实验室研究迈向商业级应用的新阶段。

此次版本升级的核心目标,是从追求“高拟真度”的学术标杆,转向打造“高可用性”的生产力工具。这意味着模型不仅需要看起来逼真,更要在实际使用中稳定、高效、易用。
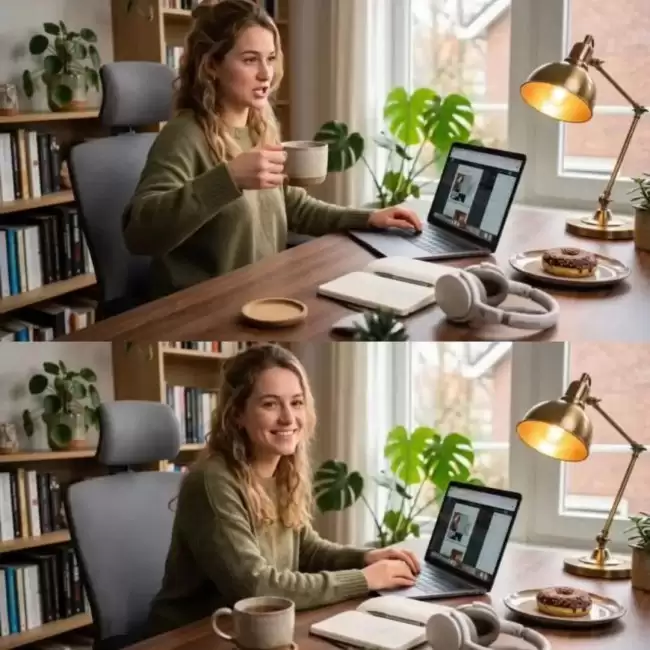
具体而言,1.5版本在多个维度实现了显著提升。首先,基础体验全面增强。新版模型能够更稳健地处理长句子、快速语音甚至歌唱等复杂音频输入,确保口型同步精准且自然。同时,面部表情、头部姿态与肢体动作的协调性也得到优化,整体动态表现更为流畅生动。
在场景适应性方面,得益于更高质量的数据训练体系,模型能够稳定生成真人、动漫角色乃至动物等多种主体形象。一个关键的实用突破是,它现在能较好地理解和生成多人对话场景,可以自然地分辨说话者与聆听者,并进行相应的视觉反馈。
效率是技术商业化的生命线。1.5版本在推理部署上实现了巨大飞跃。通过创新的DMD蒸馏技术,模型生成所需的步数从50步大幅压缩至仅需8步。这直接带来了约15倍的推理效率提升。生成一段10秒的数字人视频,现在仅需1分钟左右,极大地增强了其实用性与可部署性。

技术架构的三大核心升级
这些卓越体验的背后,是底层技术架构的三项实质性革新。
第一,基础体验的商用级打磨。模型将音频特征提取编码器从Wav2Vec2升级为参数更庞大、多语言先验知识更丰富的Whisper-large。这一改进能更精细地捕捉语音中的音素细节与韵律节奏,从而显著提升唇形同步的准确性以及全身动作的时序稳定性。其直接益处是有效减少了长视频生成中常见的画面抖动、跳帧以及角色身份漂移等问题。

第二,数据体系的系统化构建。为攻克虚拟人生成的典型难题,龙猫团队构建了一套涵盖离线标注与在线验证的多阶段数据处理流程。尤为重要的是,他们针对性引入了三类增强数据:用于训练多人交互理解的“多人对话数据”、提升静默状态自然度的“静默帧数据”,以及赋予表情更多情感的“情绪化数据”。这套组合策略精准应对了当前AI数字人生成的核心痛点。

第三,通过偏好对齐优化生成细节。模型采用了逐帧级别的GRPO(组相对策略优化)技术进行偏好对齐,专门针对手部稳定性与动作连续性进行强化训练。这有助于缓解数字人视频中常见的手部畸变、动作卡顿等细微瑕疵,使得最终生成效果更为细腻、专业。
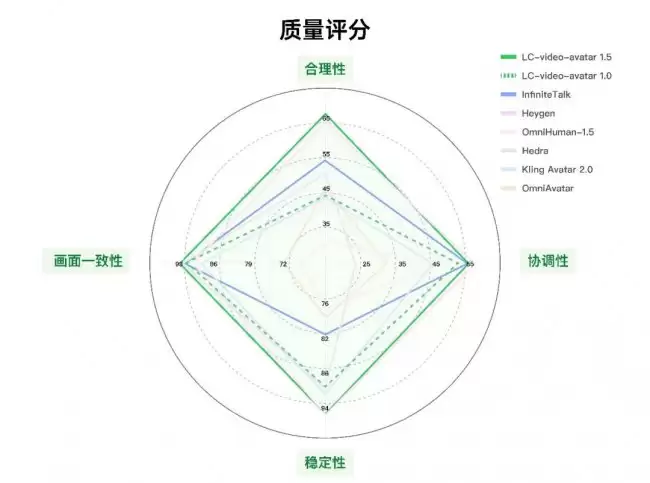
权威性能评测:展现领先优势
实践是检验真理的唯一标准。美团基于自建的EvalTalker评测基准,覆盖新闻播报、在线教育、娱乐互动等多种真实应用场景,展开了大规模综合评估。
这项由770名评估者完成超1.3万条主观评分,并结合10名专家结构化分析的结果表明,在物理合理性、时间稳定性、身份一致性和音画协调性这四个核心维度上,LongCat-Video-Avatar 1.5的综合表现雷达图面积处于行业领先水平。
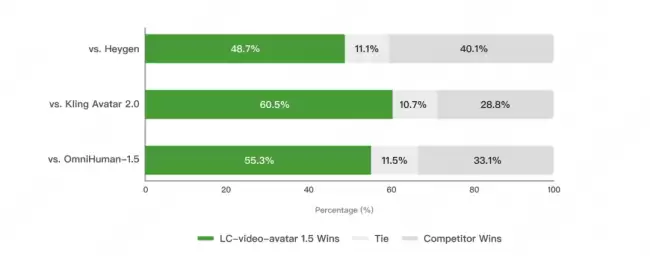
在具体的用户偏好盲测中,该模型相比其他主流数字人生成模型也展现出明显优势:对比Kling Avatar 2.0的胜率为65.9%,对比OmniHuman-1.5的胜率为61.1%,对比HeyGen的胜率为54.3%。
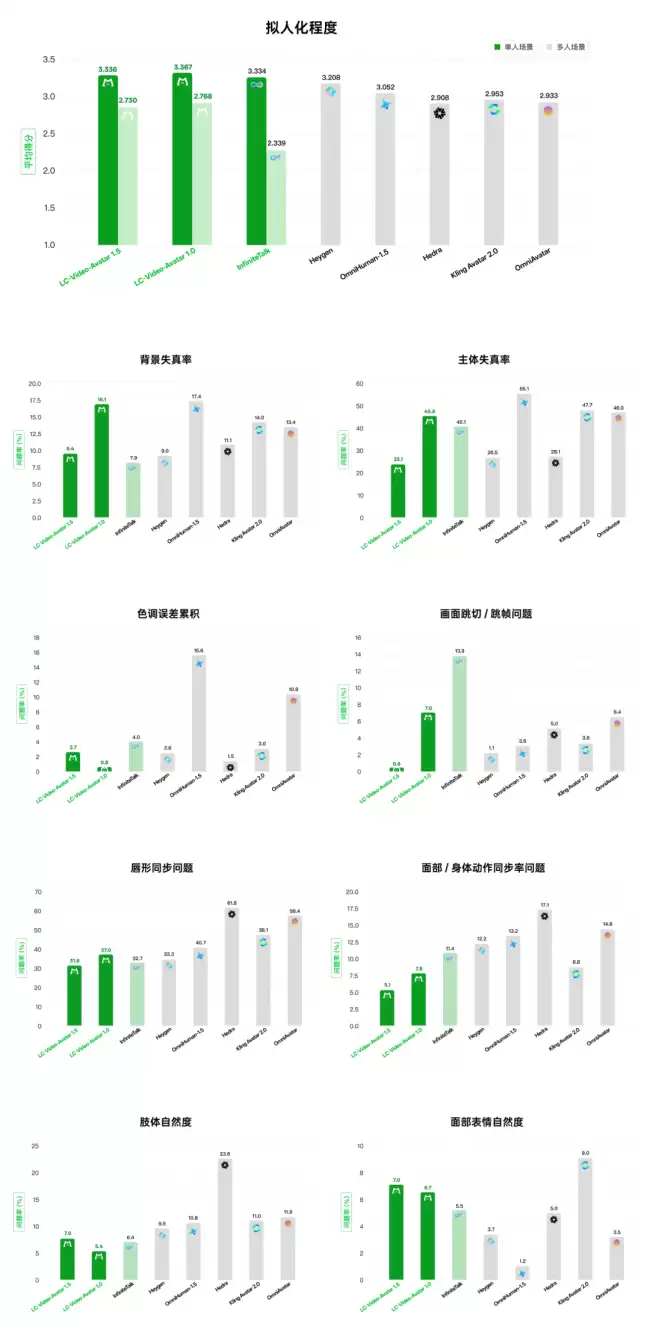
特别是在处理多人对话场景时,其得分大幅领先于InfiniteTalk等模型。在衡量生成稳定性的关键指标上,它的主体变形问题率控制在23.1%,跳帧问题率更是低至0.8%,这两项数据均优于参与对比的其他竞品模型。
此次开源清晰地表明,AI数字人视频生成技术正在跨越从“技术演示”到“生产工具”的关键鸿沟。正如美团团队所展望的,他们希望LongCat-Video-Avatar 1.5能成为一个坚实、可验证、可持续迭代的技术基座。让广大开发者与内容创作者能够基于此,深入探索虚拟数字人在电商直播、在线教育、虚拟客服、数字营销等更广阔场景下的应用潜力。
项目已全面开源,相关资源链接如下:
- Github项目地址:https://github.com/meituan-longcat/LongCat-Video
- HuggingFace模型:https://huggingface.co/meituan-longcat/LongCat-Video-Avatar-1.5
- 详细技术报告:https://github.com/meituan-longcat/LongCat-Video/blob/main/assets/LongCat-Video-Avatar-1.5-Tech-Report.pdf
- 官方项目主页:https://meigen-ai.github.io/LongCat-Video-Avatar-1.5-Page/
- Modelscope平台:https://www.modelscope.cn/models/meituan-longcat/LongCat-Video-Avatar-1.5/summary




