从零开始训练专属AI模型GitHub热门项目实战指南
最近刷抖音,一周之内被同一个项目推流了三次。
项目叫 MiniMind。打开 GitHub,50.4K stars,数字还在持续上涨。简单来说,它让你能用几块钱的成本、几个小时的时间,从零开始训练一个几十 MB 的小模型。
这事儿有点意思。
过去一提到“训练模型”,大家脑海里默认浮现的是一群工程师对着屏幕敲代码的画面。普通创作者看到这里,基本就准备关页面了。
仔细研究了一下 MiniMind,发现它已经把主要流程都打包好了。从数据清洗、预训练、SFT(监督微调)、LoRA(低秩适配)微调到推理测试,全都在项目里。
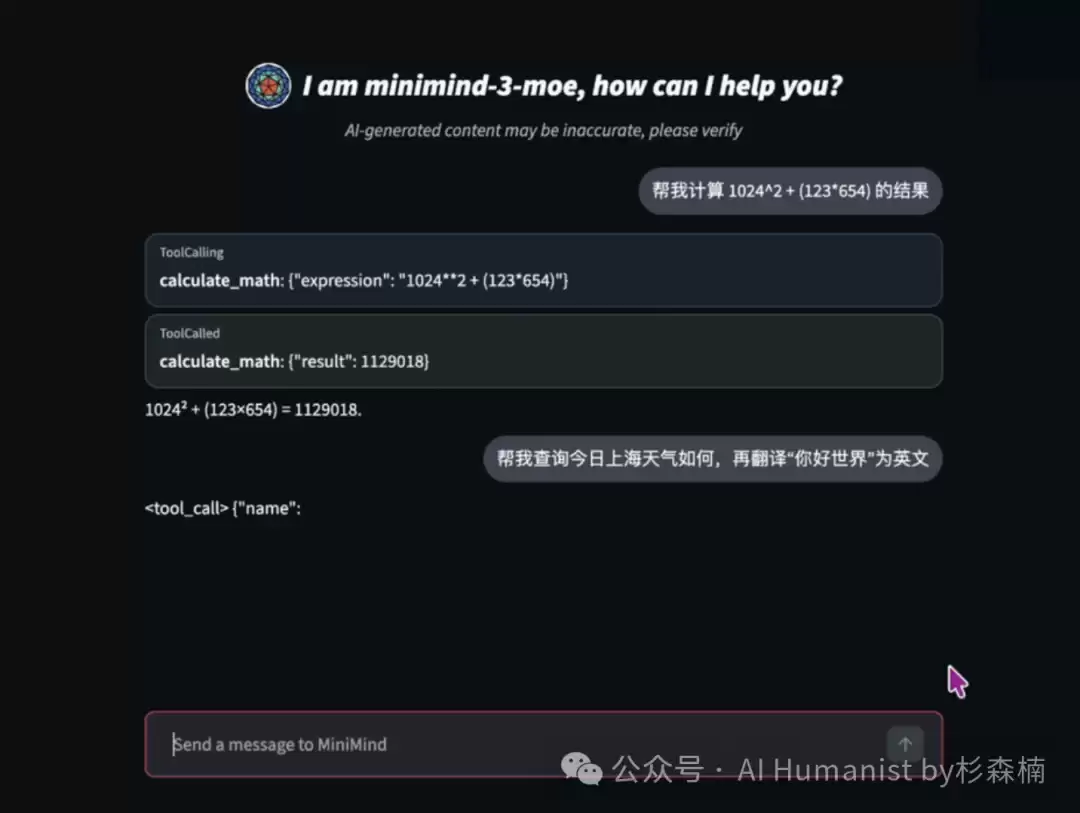
整个项目的架构大致如下:

整个流程,异常简单。
于是,我把过去写过的文章整理成数据集,训练了一个很小的个人专属写作模型。
目标很明确。
之前做过一个本地 AI 语音输入法,底层用 Whisper 做语音转录。它能准确地把我说的话变成文字,但转出来的内容终究是口述稿,标点混乱、口癖多、语序也比较松散。
我想在本地增加一个处理环节,让口述稿能自动润色成更接近我公众号文章风格的文字。这种窄场景的风格修正任务,正是小模型最擅长的。
一开始尝试了更直接的方式。
直接用个人文章材料从零开始训练,结果很快翻车。原因很简单:模型连稳定的中文表达都没学会,根本谈不上学习风格。输出结果完全驴唇不对马嘴。

于是调整了方案。
先用已经发布的 MiniMind-3 作为基础模型。它只有 64 MB 左右,但至少具备了基本的中文能力。然后在这个基础上,再用我的文章材料做 LoRA 微调。
这一步非常关键。
个人文章数据只有一万多条,数量有限。如果指望用它从零教会模型中文,材料远远不够。用现成的基础模型保留语言能力,再让 LoRA 学习我的写作习惯,成功率会高得多。
首先,需要把历史的 Markdown 文章转换成 MiniMind 能读取的 JSONL 格式文件。主要分两类:一类用于继续预训练,巩固基础文本能力;另一类用于 SFT,专门教模型完成“给一段口述稿,改成公众号文字”这个任务。
预训练数据长这样:

JSONL 可以理解成一行一条样本。它特别适合训练场景,因为程序可以逐行读取,不需要一次性把整个大文件加载进内存。
原始 Markdown 不能直接拿来用。文章里的图片链接、HTML 注释、标题符号、无关空行,都会干扰训练。处理方式是先用代码扫描文章文件夹,把纯正文抽取出来,再分割成适合训练的小段落。
预训练数据不需要太复杂,核心是让模型继续熟悉我的语言材料。
SFT 数据则要更贴近真实任务。既然希望它处理语音输入法转写的口述稿,那么样本就应该构建成“输入一段口述内容,输出一段润色后的文字”的格式。
大概是这样:

至此,训练路线就基本确定了。
MiniMind-3 负责提供基础的中文能力,我的文章数据负责风格修正。训练方式可以选择 Full SFT(全参数微调),也可以选 LoRA。
最终选择了 LoRA。原因很现实:文件小,训练快,对本地设备友好,也更适合这类个人风格化的任务。
为了让过程更直观,还做了一个简单的网页记录器。终端里执行的命令、训练日志、loss 数值,都会实时同步显示在网页上:
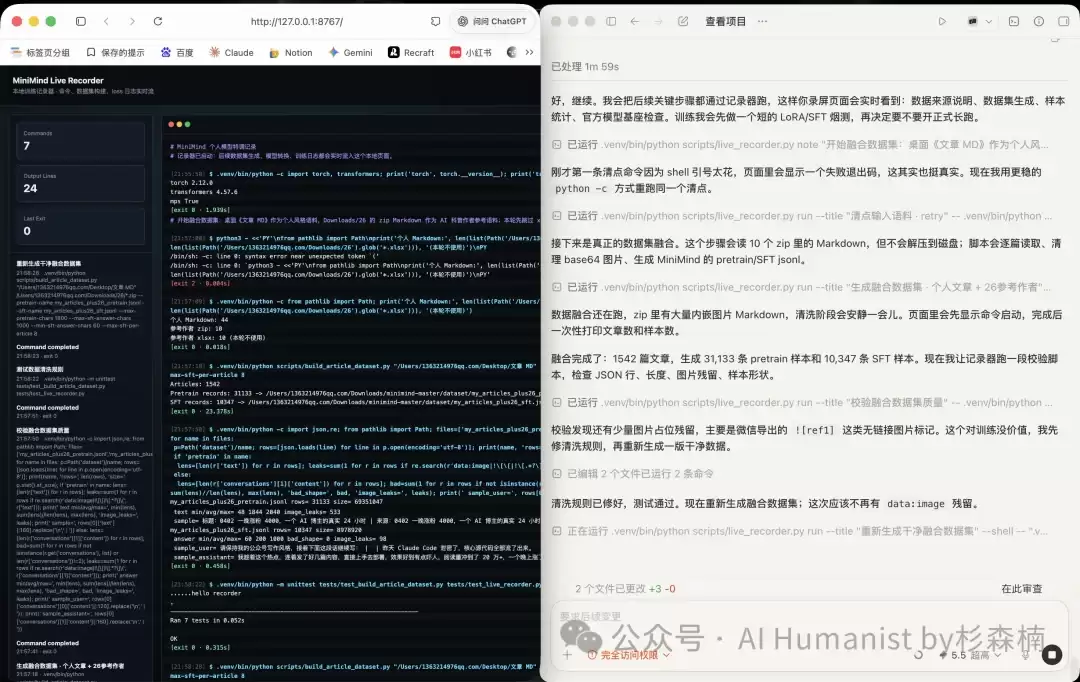
正式训练之前,先做了一次小样本验证。
只取前 80 条 SFT 样本,训练 1 个 epoch。这一步只确认几件事:数据能否正常读取、训练能否启动、LoRA 参数有没有被更新、模型生成的中文有没有完全崩溃。
小模型训练最怕一上来就把全部数据投进去,半小时后才发现格式错了。先用 80 条样本试跑,能省下大量排查时间。

验证通过。
接下来,冻结 MiniMind-3 原有的参数,只训练 LoRA 部分。这样做的好处是,基础模型原有的中文能力得以保留,我的文章材料只负责调整它的表达习惯。
用 80 条样本训练完后,模型已经能生成比较连贯的中文。当然,“个人味道”还远远不够,因为样本太少,模型只能知道“任务大概是什么”,还学不到文章的内在节奏。
后面换上包含上万条样本的融合 SFT 数据,才算进入正式训练。网页上会持续显示 loss、epoch、学习率这些关键信息。

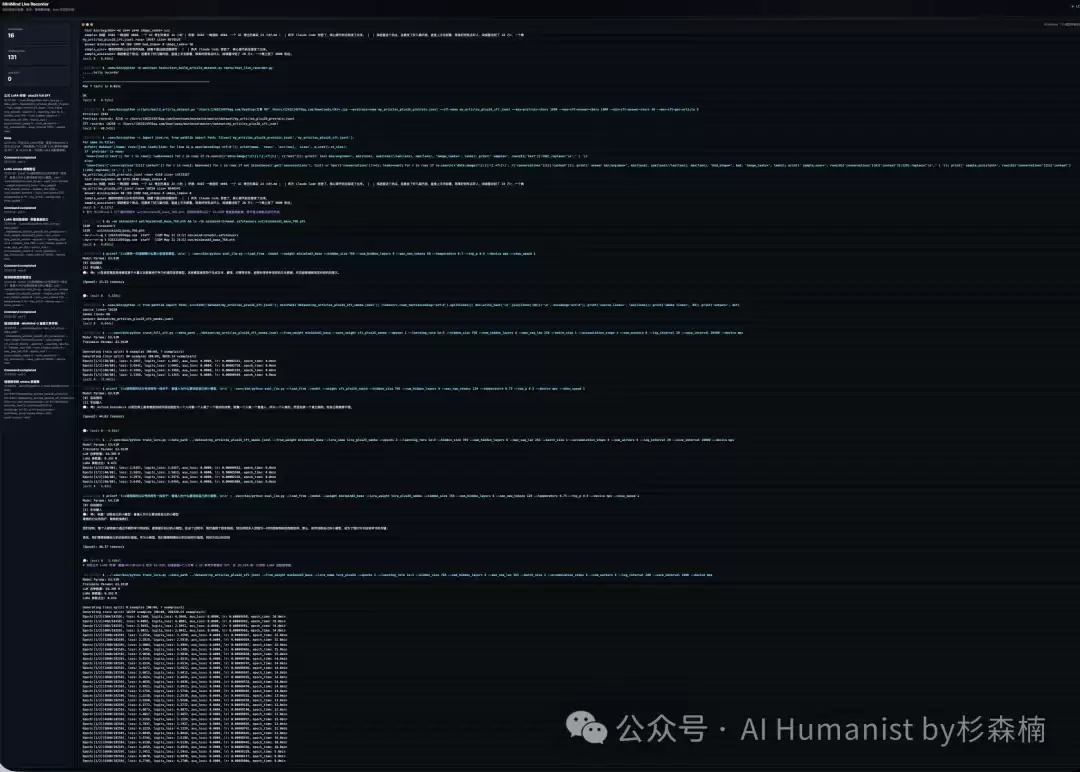
第 1 个 epoch 开始后,日志里很快出现了第一组数字。
200/10250,loss 4.296,预计当前 epoch 耗时约 16 分钟。
这时最关心的是训练是否稳定持续,数字是否好看反而在其次。只要样本在被读取,loss 在变化,显存和内存没有异常,就说明这条路能走下去。
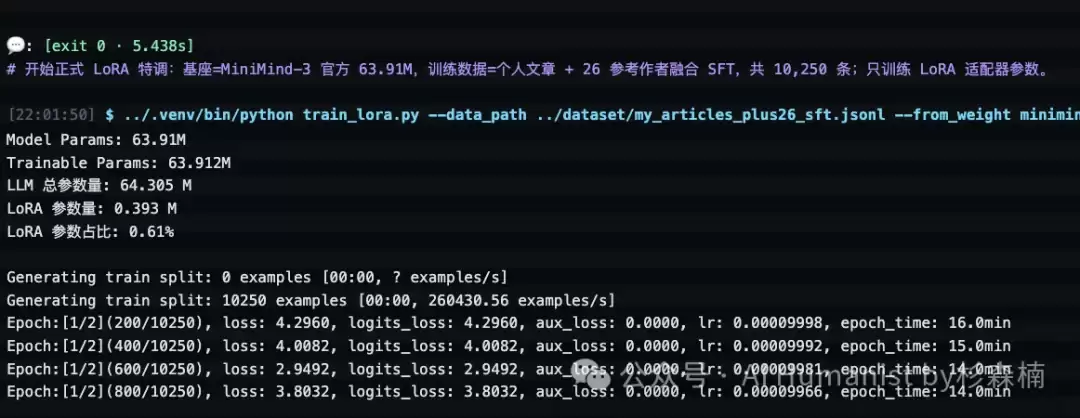
训练到后期,loss 从 4.296 降到了 2.949。
这里可以简单理解一下 loss。它衡量的是模型在预测下一个 token(词元)时犯错的严重程度。数字降低,说明模型更能“猜中”训练数据里接下来的表达。
当然,loss 不会一直平滑下降。数据里有短句续写,也有长文切片,有些段落语气强烈,有些偏重说明,难度不一。训练到 1800 step 左右时,loss 在 2.5 到 4.1 之间波动,这反而是正常现象。
如果它一路低得离谱,反而要担心数据是否过于重复,导致模型只是死记硬背了样本。
到 7600 step 左右,学习率已经降得很低。
学习率可以理解为模型每次调整参数的幅度。前期幅度大,是为了快速向训练数据靠近;后期幅度变小,是为了微调,避免“乱改”。最后看到学习率降到 1.36E-5(即 0.0000136 左右),基本就进入收尾阶段了。
整个训练耗时大约一小时。说实话,这比预期要短。
最终产出两个文件:一个是 MiniMind-3 的基础模型文件,另一个是训练出来的 LoRA 文件。前者提供通用的中文能力,后者承载我的文章习惯。两个文件组合起来,就能在本地启动一个专属于个人的小型写作模型。
训练完成,真正的问题才刚刚开始。
必须清醒认识到,一个 64 MB 左右的小模型,能力必然有限。它做不了复杂推理,也不适合回答开放性的知识问题。如果拿它当 ChatGPT 用,结果大概率会让人失望。
给它安排的场景非常具体:放在语音输入法里,专门处理我的口述稿。
之前做过一个叫 Whisper input 的本地语音输入法。它用本地 Whisper 模型转录语音,再把文字发送到光标所在位置。平时写文章、回消息、记想法都用得上,体验还算丝滑。
它原来的流程很简单。
按下快捷键说话,Whisper 在本地完成转录,结果直接送入当前输入框。因为模型在本地,响应几乎不受网络影响,也无需把每一句话都上传到云端。
这个方案已经比许多在线语音输入工具更顺手。尤其是在撰写中文时,其稳定性比之前尝试过的 Typeless、WhisperFlow 等工具更符合个人习惯。
但这个方案也有个明显短板。
Whisper 解决的是“听清我说了什么”,没有解决“这段话能不能直接放进文章”的问题。
口述内容天然带有重复、停顿、废话和半截句。比如描述一段体验时,嘴上会冒出很多“然后”、“就”、“这个”、“大概”,转成文字后很难直接使用。
如果每次转录完都调用大模型 API 来润色,当然也能改。麻烦在于,整个流程会变得像多个智能体协作,每个节点的优化和维护成本都会增加。
这时,本地文章小模型的价值就凸显出来了。
它只专注于一个任务:把语音转写稿,修改成更接近我文章风格的初稿。
为此,给演示程序做了两个模式。
一个是普通对话,用来测试模型是否正常启动。另一个是语音润色,专门把口述稿发进去,让它清理口癖、补充标点、调整语序。
整个组合非常轻巧。MiniMind-3 基础模型,加上个人文章的 LoRA,总体积仍在 64 MB 左右。
这听起来有点像技术玩家的“整活”。但越深入尝试,越觉得这类小模型的价值,源于一个朴素的优点:文件小,启动快,可以无缝嵌入个人工具链,承担一个非常具体的环节。
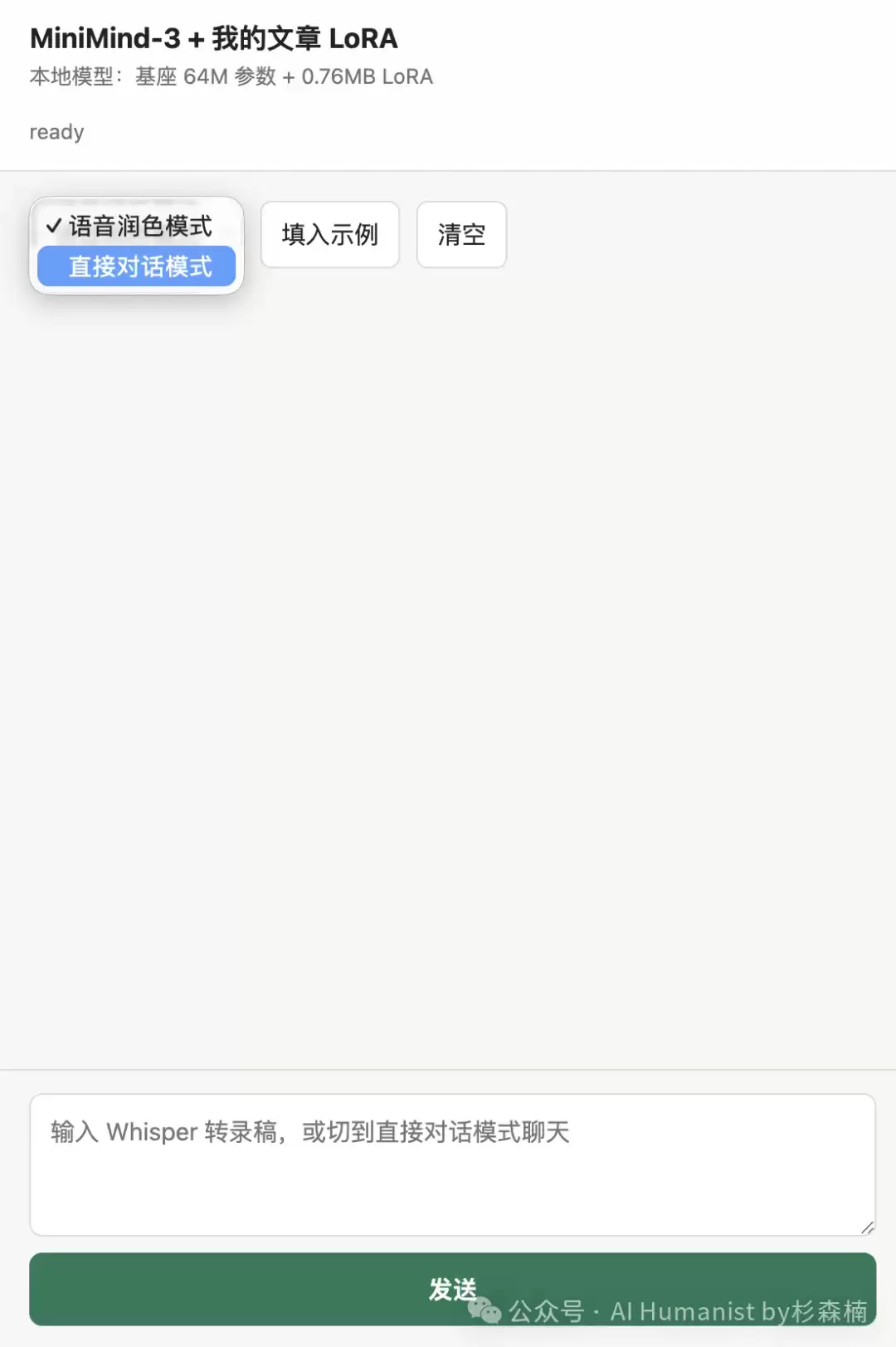
第一次启动演示程序,先问了一句“你好”。
它回复得极快,快到有些离谱。
这当然和模型体积小有关。64 MB 左右的参数量,能力上限固然不高,但响应速度也极其夸张。你不会看到大模型那种“长时间思考”的状态,它更像一个本地小插件,输入进去,很快给出结果。
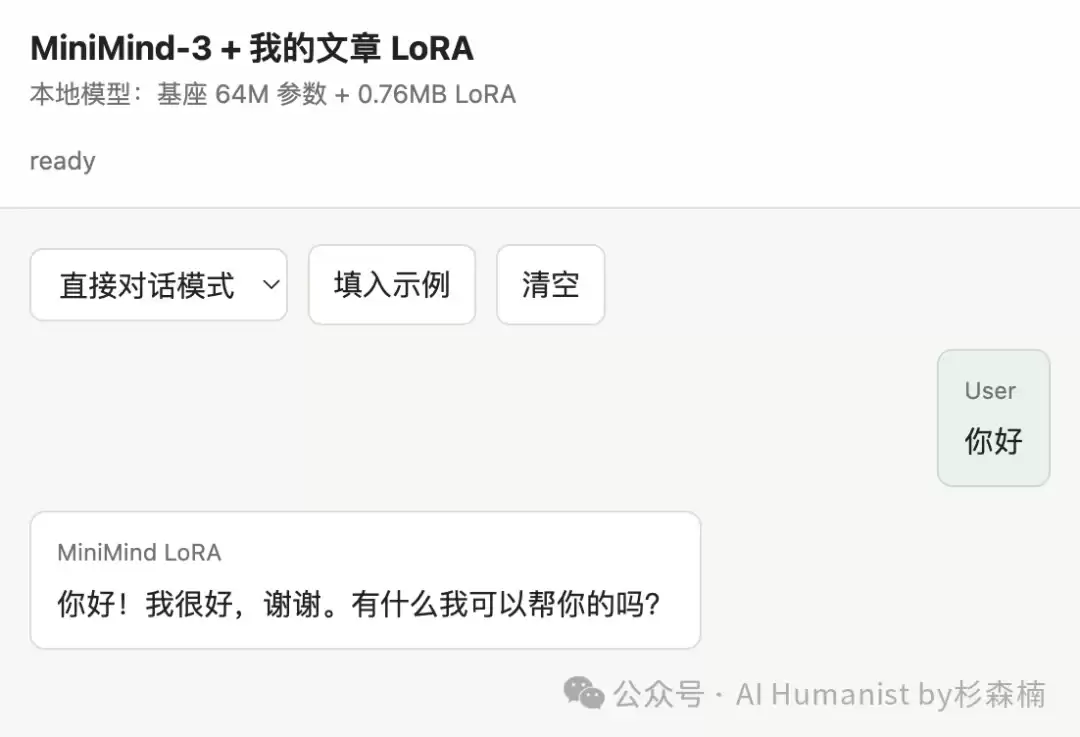
又让它介绍一下自己的能力。
回答谈不上惊艳,但至少结构正常,能把“写作分析”、“问题解决”、“内容调整”这些方向说出来。
到这一步,对它的预期就更稳定了:它能处理一些轻量任务,但不能指望它承担复杂的逻辑判断。
最适合它的场景,还是语音润色。
发一段典型的口述稿进去,里面充满了停顿、重复、语序混乱,还有一些临时想到的补充。它会尝试把句子重新切分,补上标点,删掉一部分口头禅。
效果虽然没有大模型那么稳定,但已经能把一段无法直接使用的语音稿,改写成可以继续编辑的文字草稿。对个人使用来说,这就足够了。

再看一个例子。
刚体验完一款新的 AI 产品,直接用口述方式说了一段感受。原稿里有很多重复表达,前后顺序也有些混乱。
小模型处理之后,会主动把句子切开,把几个核心判断调整到更顺畅的位置。它也会保留一点个人语气,不会把所有句子都改成千篇一律的客服文案:

当然,边界也非常明显。
这个模型太小,数据也少。一万多条样本在个人项目里算不少,但在模型训练领域只能算是很小的量。它能学到一点文章习惯,能处理固定模式的任务,但无法保证每次输出都稳定。
关键在于,训练数据不能只包含“私人样本”,还必须依赖基础的通用数据集。
因此,不会把它包装成什么“个人大脑”,也不会声称它已经能替代大模型。它现在更像一个本地写作小插件,放在语音输入法后面,帮我把第一版口述稿修改得稍微顺眼一点。
但这件事本身,确实令人兴奋。
过去,训练模型对普通创作者来说太过遥远。大家基本上只能跟现成的 AI 产品“交流”,很少有机会亲手看到自己的材料如何变成数据集,如何参与训练,最终如何生成一个能在本地启动的模型文件。
这可能才是本次实践最大的收获。
未来,每个人未必都需要一个通用的、全能的大模型,但很多人可能会需要几个很小的、专属的个人模型。它们的任务将更加具体,专门处理你每天反复遇到的那些小问题。
至于回答全世界的问题,仍然交给大模型。
而把一段乱七八糟的语音稿,改成你愿意继续写下去的文字——这种小事,交给自己的小模型就好。
对于每天都在跟文字打交道的人来说,这已经足够实用了。
相关攻略

作者基于MiniMind-3,通过LoRA微调训练出约64MB的专属写作模型。该模型能学习作者文风,将语音转写稿快速润色为公众号风格,有效清理口癖、调整语序。训练耗时约一小时,虽能力有限,但作为本地轻量工具,已可满足特定文本润色需求。

GitHub正面临严重危机:频繁故障导致开发者迁移项目,企业客户不满。核心源代码泄露暴露安全隐患,管理层取消CEO职位后并入微软团队,引发人才流失。同时面临AI编程工具竞争,商业模式改革致用户流失,开源社区信任受损,平台未来挑战严峻。

北京时间5月20日,代码托管平台GitHub通过其官方账号发布了一则声明,正式承认其内部仓库遭遇了未授权存取。目前,相关调查正在进行中。 公告中,GitHub试图安抚用户,强调“目前没有证据显示储存在GitHub内部仓库以外的客户信息受到影响”,并承诺会持续监控基础设施,一旦发现任何影响将及时通知客

微软内部警示GitHub面临生存风险,因AI编程工具正削弱代码托管必要性。微软虽以Copilot引领AI编程,但竞争对手产品快速发展,重塑开发者工作流。微软内部试用后强制转向自家工具,旨在控制成本并巩固生态。同时,OpenAI考虑自建托管平台,进一步威胁GitHub根基。AI正深刻改变代码生成与管理方式。

近日,GitHub官方通过社交平台X发布紧急安全通告,确认其内部代码仓库系统遭遇未授权访问事件。此次安全漏洞的源头,指向一名员工设备上安装的恶意Visual Studio Code扩展程序。 根据GitHub安全团队的初步调查,攻击者通过一个被篡改的VS Code插件渗透进入内部网络。在监测到异常活
热门专题







热门推荐

在《燕云十六声》中领悟“菩提苦海”,需沉浸探索游戏世界。主线剧情构建认知框架,战斗观察、场景细节与NPC对话皆暗藏线索。通过多元视角拼凑因果,方能深入理解游戏蕴含的宏大叙事与深邃魅力。

2026年618大促的序幕刚刚拉开,初期战报已经透露出一些耐人寻味的信号。截至5月21日,海信电视在京东平板电视累计销售竞速榜上拔得头筹,其RGB-Mini LED爆款王——海信小墨E5S Pro,更是同时拿下了天猫平板电视和抖音大家电的5 20单品销冠。 这并非偶然。奥维云网的全渠道监测数据给出了

充电桩领域的“军备竞赛”再次迎来重磅升级。5月22日,极氪汽车正式发布了其全新一代液冷超级充电桩,将单枪峰值功率一举提升至行业领先的800kW,标志着超充技术迈入新阶段。 根据官方披露的核心信息,这款超充桩主要具备四大优势:极速补能、高效节能、广泛适配与多重安全。具体而言,其单枪峰值电流高达800A

获取电弧机剑主要有五种途径:推进主线任务以解锁线索;探索遗迹、工厂等特定区域;挑战特定副本与Boss;完成提及传说武器或遗物的支线任务;参与限时活动并达成要求。玩家可根据偏好选择或组合多种方式获取该武器。

小米汽车再次为潜在车主带来惊喜福利!即日起至5月31日,用户只需提前完成预约,并到店参与任意车型的试驾体验,即可免费获赠一款1:64精致合金车模。车模款式与颜色随机发放,为试驾过程增添一份专属的收藏乐趣,诚意十足。 参与本次活动需注意以下细则:试驾必须通过官方渠道提前预约;各授权门店的车模备货数量不