
从街景到仿真,离线地理信息正在成为车辆理解复杂道路的新线索。
大模型的发展揭示了一个核心趋势:智能体不能仅依赖一次性的上下文输入,它更需要具备检索、利用和管理长期记忆的能力。自动驾驶领域也正朝着类似的方向演进。未来的智能汽车,或许不应仅仅根据摄像头和传感器捕捉的瞬时画面做出决策,而应能主动调取一种关于道路的“空间记忆”——一种基于街景、卫星图、历史地图和车队经验积累的长期知识库。这样一来,即便在传感器因遮挡、恶劣天气或复杂路况而“看不清、看不全、看不远”时,车辆依然能凭借历史信息理解自己所处的道路环境。
现实驾驶中的挑战无处不在。夜间驶过无路灯的路口,车道线被阴影吞没;雨天穿行于城区,玻璃反光和水雾让路沿与人行横道变得模糊;面对复杂的立交或多岔路口,车载传感器只能捕捉当前一隅,却必须对完整的道路拓扑结构做出预判。
人类司机在此类场景下,会本能地调动记忆:这里原本有几条车道,路口在哪里分叉,人行横道大概在什么位置。这种“空间记忆”是人类驾驶的天然优势。然而,长期以来,主流的自动驾驶模型仍被禁锢在实时传感器的输入框内,只能依据当前“看到”的有限信息进行决策。一旦遭遇遮挡、低光、雨雾等长尾场景,模型就容易失去稳定的空间参考系,导致感知不确定性增加。
正是在此背景下,复旦大学可信具身智能研究院与上海交通大学的联合团队提出了创新性研究《Spatial Retrieval Augmented Autonomous Driving》。这项工作的核心思路颇具巧思:它并非给车辆增加又一种昂贵的硬件传感器,而是教会自动驾驶系统如何“回忆”——根据车辆的GPS和位姿信息,主动检索对应位置的街景、卫星等历史地理图像,并将这些Geo信息与车载相机特征进行融合,为模型提供额外的、稳定的道路结构参考。
更值得玩味的是,这项研究并没有将地理图像奉为圭臬。实验结果清晰地划定了它的能力边界:Geo图像最擅长补充的是那些稳定、长期存在的静态道路结构信息,比如车道线、道路边界、人行道、建筑轮廓和可行驶区域。而对于车辆、行人这类瞬息万变的动态目标,它的帮助则相当有限。
这一结论反而让研究的意义更加凸显——Geo的目标并非取代实时感知,而是要成为自动驾驶系统中的一种“空间先验知识库”。它的核心价值在于,当车辆看不清当下世界时,能提供一个“这条路原本是什么样子”的可靠参照,从而增强系统的鲁棒性和安全性。
因此,这项工作的真正贡献,或许不在于某个单一指标的提升,而在于开启了一种新的范式可能性:推动自动驾驶从“纯粹依赖当前传感器”走向“实时感知与历史地理记忆相结合”。在自动驾驶竞争日益聚焦于解决长尾场景、提升安全冗余和构建精准世界模型的当下,这种检索增强的思路,很可能成为下一代系统理解复杂道路空间的重要技术拼图。

Geo 的适用边界
整体来看,研究揭示了一个关键规律:不同自动驾驶任务从地理图像中获益的程度差异显著。与静态道路结构相关的任务提升明显,例如在线高精地图构建、占用栅格预测和世界模型;而动态目标检测类任务则提升甚微。
这背后的逻辑很直观:地理图像提供的是道路、车道、建筑等近乎不变的背景信息,它无法捕捉当前时刻路上飞驰的车辆或行走的行人。因此,它天然更适合充当空间结构的“参考书”,而非实时动态的“监控屏”。
在线建图是受益最显著的任务。由于该任务核心是识别车道线、路沿、人行横道等静态元素,Geo图像能有效补充道路结构细节。实验中,MapTR的mAP从50.3提升至61.2,MapTRv2则从61.5跃升至73.4。尤其在低曝光、雨天和遮挡场景下,加入Geo后模型恢复道路细节的能力显著增强,这相当于为模型提供了当前位置的“道路蓝图”。
占用预测同样获得提升,但幅度不及建图。Geo的作用主要集中于可行驶区域、人行道等地形静态区域。FBOcc的整体mIoU从39.11提升到39.74,其中可行驶区域的IoU从80.07提升至82.47。这再次印证,Geo更擅长帮助模型理解空间骨架,而非瞬息万变的动态物体。
相比之下,3D目标检测的提升几乎可以忽略不计。BEVFormer的mAP仅从41.60微升至41.64。原因不言而喻:目标检测紧盯的是实时车辆和行人,而离线地图或街景信息无法反映这些动态变化,自然帮助有限。
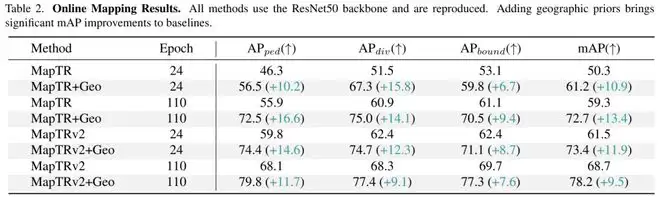
在端到端规划任务中,Geo对轨迹预测的误差影响不大,但却能提升安全性。实验显示,在夜间场景下,碰撞率从0.55%降至0.48。这表明,Geo不一定能让预测轨迹更“准”,但在夜间、雨雾等低能见度的复杂路口,它能提供更稳定的道路参考,从而降低碰撞风险。
世界模型是另一个明显受益的领域。研究人员发现,在长时间生成驾驶视频时,模型容易出现道路漂移和背景不一致的“幻觉”。Geo图像能提供真实道路结构的约束,让生成结果更稳定。实验中,UVG的FVD指标从36.10降至29.97,幻觉现象显著减少。
最后的消融实验进一步夯实了结论。移除Geo后,静态元素的mIoU为46.66,加入后提升至47.86。这证明性能提升并非偶然,Geo图像本身、位置编码以及可靠性估计模块共同构成了有效的增强方案。
从地理检索到可靠融合
为了验证想法,研究团队首先基于nuScenes数据集构建了一个扩展版本——nuScenes-Geography。其目标是让自动驾驶模型在利用车载摄像头的同时,也能调用当前位置对应的地理图像信息。
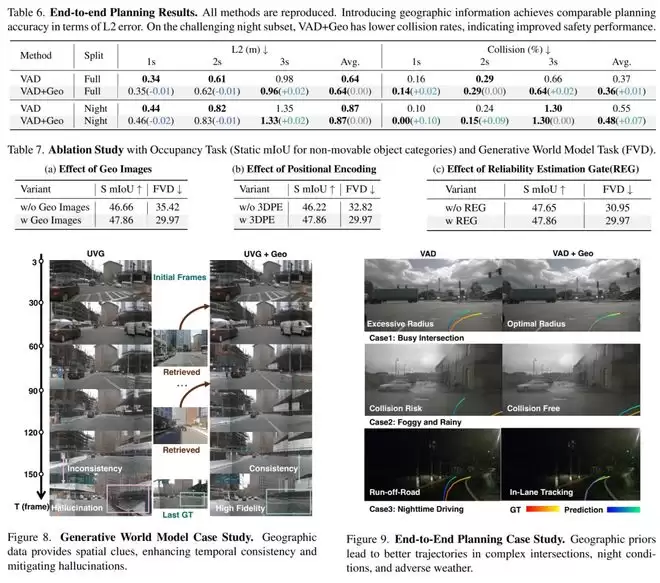
技术路径很清晰:先根据nuScenes提供的车辆位姿数据,计算出每一帧对应的经纬度坐标,再通过Google Maps API获取该位置的街景图和卫星图。获取地理图像后,关键一步是将其与车载相机画面进行空间对齐,使得模型能同时看到“当前视角”和“历史地理视角”。
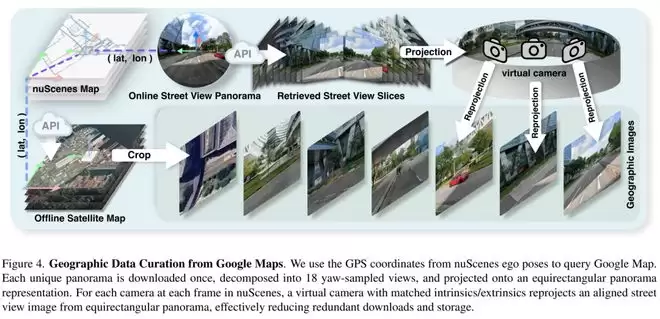
数据显示,训练集中94.32%、验证集中92.41%的场景都能成功获取Geo信息,覆盖率很高,说明实验并非只在少数理想样本上进行。
在构建数据集时,团队遇到了一个实际问题:街景图并非按车辆每一帧采集,连续多帧车载画面往往对应同一个街景位置。如果逐帧下载,会产生大量冗余数据,存储和计算成本高昂。
为此,研究人员采用了更高效的策略:每个街景位置只下载一次数据。为了覆盖多角度,他们在同一位置下载18个不同方向的街景视角,合成为全景图。然后,系统根据当前车载相机的方向、位置和视角参数,从全景图中重新投影,生成与当前驾驶视角匹配的Geo图像。这种方法节省了超过70%的存储空间,并减少了数据冗余,提升了实际部署的可行性。
然而,Geo图像并非永远可靠。现实情况复杂多变:街景可能缺失、数据可能过时、GPS存在定位误差、高架与地面道路可能混淆、道路施工会导致环境改变。如果模型盲目依赖过时或错误的Geo信息,反而可能做出误判。
因此,研究团队专门设计了一个可靠性估计模块(REG),用于动态判断当前检索到的Geo图像是否可信。该模块会综合评估Geo图像与当前车载图像之间的视觉相似性,以及地理位置匹配程度,从而决定模型应在多大程度上采纳Geo信息。
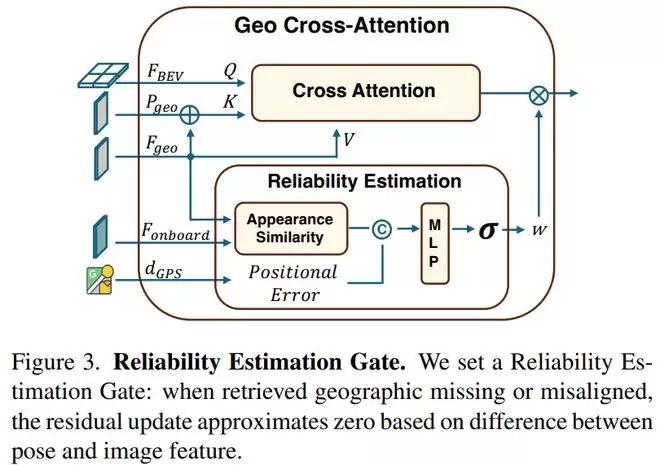
为了训练这个模块,团队人工标注了1800个错位样本。数据显示,训练集中错位图像占4.93%,缺失图像占0.75%;验证集中错位图像占6.88%,缺失图像占0.71%。这些数字表明,研究没有假设Geo永远正确,而是让模型学会“审慎采纳”——信息可信时增强使用,不可靠时降低权重,以此提升系统整体的鲁棒性。
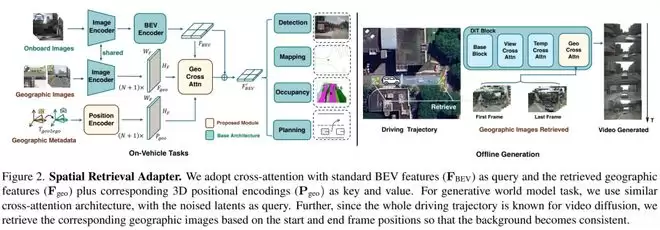
数据处理完毕后,团队将Geo接入多种自动驾驶任务进行验证。对于车载任务,流程是:先从车载图像提取BEV特征,再将检索到的Geo图像编码成另一组特征,最后通过适配模块将两者融合到同一空间表示中。其目的是让模型既能利用实时传感器信息,也能参考历史道路结构。
实验覆盖了3D目标检测、在线建图、占用预测及端到端规划等多个任务。对于世界模型任务,策略有所不同:由于需要生成未来驾驶视频,系统会根据预测的未来轨迹,提前检索相应位置的地理图像,并用这些Geo信息约束未来场景的生成过程,旨在减少长视频生成中的道路漂移和场景幻觉问题。
整个实验的核心目标,是验证Geo能否成为自动驾驶系统的“空间记忆”。团队并非只想证明某个模型指标略有改善,而是希望系统性阐明,自动驾驶模型除了依赖当前传感器,完全可以通过检索历史地理图像获得有价值的空间先验。通过将Geo接入多种不同任务和模型,研究验证了该方法的通用性,并清晰界定了其最适用的任务类型。
从感知增强到仿真约束
这项研究最重要的贡献,或许不在于那几个提升的百分点,而在于提出了一种新的思路。传统的自动驾驶系统高度依赖实时传感器输入,车辆只能基于“当下所见”做出判断。而这项工作证明,自动驾驶系统可以主动检索并利用历史地理图像,从而获得一种类似“空间记忆”的能力。这意味着,自动驾驶的感知范式,开始从纯粹的“实时感知”,转向“实时感知与历史空间记忆相结合”。
可以说,这项研究真正打开了“检索增强自动驾驶”这个新方向。过去的研究焦点多在传感器、模型架构和端到端学习上,而这项工作尝试将外部地理信息作为一种可检索的知识引入系统。未来的扩展方向显而易见:例如,利用车队积累的历史数据替代公开地图,或者同时检索多个邻近视角的地理信息,从而进一步提升系统对复杂空间的理解能力。
成果背后的科研团队
这项研究由复旦大学可信具身智能研究院的助理教授贾萧松主导。该研究院是复旦大学面向下一代人工智能设立的校级实体科研机构,重点探索AI如何从数字空间走向物理世界。其研究不仅关注具身智能体“能否感知与行动”,更关注其在真实环境中的安全性、可靠性与可控性。研究院围绕具身基础模型、数据引擎、交互、硬件本体及可信机制五大方向布局,旨在打通从模型、数据、硬件到安全评估的全链条,为工业制造等场景提供底层技术支持。
贾萧松博士毕业于上海交通大学,师从严骏驰教授。其研究聚焦于自动驾驶与具身智能,涵盖端到端自动驾驶、闭环评测、世界模型、强化学习、轨迹预测及多传感器融合等多个方向。同时,他也关注利用生成式与重建式模型构建更逼真的世界模拟器,并结合模仿学习与强化学习来训练端到端决策智能体。在学术成果方面,他已在IEEE TPAMI、IJCV、CVPR、ICCV、NeurIPS、ICLR等顶级会议期刊发表论文40余篇,参与的研究曾获得ICCV 2024 Mair2 Workshop最佳学生论文奖、CVPR 2024最佳论文奖,并在2025年Waymo仿真智能体世界模型挑战赛中夺冠。





