清华提出TaH方法大幅提升训练效率与模型准确率

在AI推理模型的发展中,一个明确的共识是:增加计算量通常能提升答案的可靠性。从扩展思维链到深化内部推理,诸如o1、R1等前沿模型的演进,都验证了“让模型进行更深入思考”这一技术路线的价值。
然而,一个核心问题常常被忽视:模型在生成每一个词元(token)时,是否都需要付出相同的“思考”成本?
这对于参数量有限的小型模型而言,尤其是一个关乎性能与效率的关键挑战。小模型部署成本低、推理速度快,非常适合边缘计算场景,但其固有短板也相当突出——在处理数学运算、代码生成和复杂逻辑问答时,往往因为少数几个关键token的预测错误,导致整个推理链条崩溃。现有的“循环Transformer”方案试图应对此问题,其原理是在生成每个token前,将最后一层的隐藏状态反馈给模型进行额外的“潜空间迭代”,相当于在不增加参数的前提下,为每个token都增加了计算深度。
但这种方法真的最优吗?来自清华大学、无问芯穹、上海交通大学等机构的联合研究团队在最新论文中发现,事实并非如此。他们的研究揭示了一个反直觉的现象:有相当一部分token在模型第一次前向传播时就已经预测正确,后续的潜空间迭代不仅没有益处,反而可能将原本正确的预测“改错”。研究团队将这一现象命名为“潜空间过度思考”。
基于这一核心发现,该团队提出了 **Think-at-Hard(TaH)** 方法。这是一种面向小型模型的选择性潜空间迭代框架,其核心理念是“将计算资源用在刀刃上”——只让模型在真正难以预测的token上“停下来,多思考一步”。该方法已入选ICLR LIT Workshop最佳论文候选,并被ICML 2026接收。

潜空间迭代是一把双刃剑:既能纠正错误,也可能引入新的错误。
核心贡献
这项研究的主要贡献可总结为以下三点:
首先,它首次系统性地揭示并量化了循环Transformer中存在的“潜空间过度思考”现象,明确指出统一深度的迭代会同时产生“纠错”和“致错”两种相反的效果。
其次,提出了完整的TaH框架。该框架通过一个轻量级的“迭代决策器”、创新的双路因果注意力机制以及深度感知的LoRA模块,实现了在token级别动态分配计算资源。
最后,在涵盖数学、问答和代码的9个主流基准测试中,TaH均带来了稳定的性能提升。最关键的是,它平均仅让约7%的token进入第二轮迭代,跳过了93%不必要的额外计算。与那种强制所有token都“思考两遍”的基线方法相比,TaH在显著减少计算量的同时,准确率反而提升了3.8%到4.4%。

关键洞见:对简单Token进行迭代计算反而有害
已有研究表明,在语言模型的推理过程中,并非所有token都同等重要。真正决定推理走向的,往往是那些表示逻辑转折、因果关联或中间结论的关键性token。
为了量化“选择性迭代”的潜在收益,研究者设计了一个“先知”策略:仅当模型第一次预测某个token出错时,才允许它进行额外迭代;如果第一次预测正确,则直接输出。实验结果显示,仅凭这一理想化策略,就能为下游任务带来最高7.3%的性能提升,且仅需让11%到19%的token进行二次迭代。
这传递出一个清晰的信号:推理时的计算资源分配,必须细化到token级别。复杂问题中也包含简单token,简单问题里也可能隐藏着关键token。更重要的是,对简单token强行施加额外计算,不仅浪费算力,还会导致一部分原本正确的预测被“过度思考”而改错,这正是“潜空间过度思考”的具体体现。
TaH框架:在困难之处停下来深入思考
TaH的思路简洁而高效:简单的token快速通过,困难的token才值得投入更多计算资源进行“深思熟虑”。
具体实现上,TaH在模型中引入了一个轻量级的“迭代决策器”(一个小型MLP网络)。每完成一轮潜空间迭代后,决策器会基于模型骨干网络的当前状态,预测一个“继续迭代”的概率。如果该概率低于预设阈值,模型就直接输出当前token;如果高于阈值,则进入下一轮迭代。
在实际推理中,TaH平均每个token仅执行1.07次迭代,相当于跳过了约93%的token的二次计算。相比“所有token都想两遍”的暴力策略,TaH成功地将宝贵的计算力集中到了那些更容易出错、更能影响整体推理方向的关键位置上。
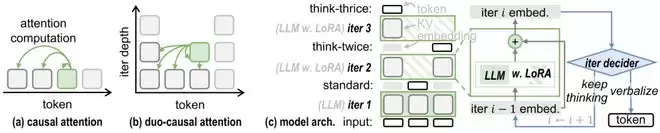
TaH的整体架构与双路因果注意力机制示意图。
为了让这种动态深度策略真正提升模型的精度和效率,TaH在模型架构和训练策略上都进行了针对性设计:
1. 双路因果注意力机制: 选择性迭代将模型处理的序列结构,从一维的token序列,转变为“token位置 × 迭代深度”的二维网格。TaH将传统的因果注意力扩展到了这个二维平面。对于某个位置第d次迭代的查询,它可以关注到前序位置中、迭代深度不超过d的所有键和值。这样既允许信息在不同迭代深度间有效流动,又保持了训练时序列维度的全并行计算能力。
2. 深度感知LoRA架构: 研究者观察到,模型的第一次迭代主要负责常规的下一个token预测,而更深层的迭代则专注于修正当前遇到的困难token。因此,TaH只在第二次及以后的迭代中启用LoRA适配器,让LoRA专门学习如何修正困难token。再配合跨迭代的残差连接,深层迭代就被自然地训练为“在前一轮结果的基础上进行精细化修正”,而非从头开始推理。
3. 两阶段训练策略: 由于迭代决策器的判断依赖于骨干网络的预测质量,而骨干网络的训练目标又依赖于决策器决定的迭代深度,两者紧密耦合,端到端训练极不稳定。TaH采用了解耦的两阶段方案:第一阶段,使用静态的“先知”策略来训练骨干网络;第二阶段,冻结骨干网络,单独训练决策器去模仿“先知”的继续/停止决策。这种方法显著提升了训练的稳定性和收敛速度。

在Qwen3-0.6B基座模型上,TaH展现出更快的收敛速度。
实验效果:更少的迭代,更强的推理能力
论文在Qwen3系列的0.6B、1.7B和4B三个规模的基座模型上全面验证了TaH。训练数据来自Open-R1中数学、问答和代码任务的均衡混合,并在GSM8K、MATH500等9个主流基准上进行了综合评测。
准确性方面: 在不增加参数总量的前提下,TaH相比标准Qwen3模型提升了3.0%到3.8%。而“TaH+”版本在仅增加不超过3%额外参数(来自决策器等模块)的情况下,将提升幅度扩大到了5.3%到6.2%。与同类循环Transformer方法“Ouro”相比,TaH取得了3.8%到4.4%的优势,TaH+的优势则达到6.1%到6.8%。
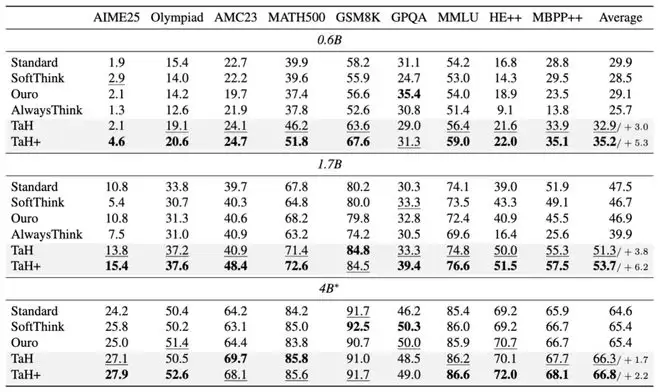
计算效率方面: TaH平均每个token仅执行1.07次迭代,完成问答的平均FLOPs和显存访问量相比标准模型只增加了4%到5%。在实际解码测试中,TaH相比“始终迭代”的基线方法,显存占用降低了1.48倍,解码速度提升了2.48倍,同时保持了更高的准确率。
迭代选择的语义可解释性: 一个有趣的发现是,TaH自动学习到了具有明显语义偏好的迭代行为。在验证集上,“But”和“So”是最常触发额外迭代的token,概率分别达到34%和18%。这些词汇通常对应着推理中的逻辑转折、因果关联和方向切换,恰恰是复杂推理中最可能决定后续路径的关键位置。

模型预测在两次迭代之间的变化情况。
消融实验分析
为了验证TaH框架中每项设计的必要性,研究团队进行了系统的消融实验。
模型架构方面: 将动态深度的决策器替换为固定迭代1次或2次的策略,基准测试性能平均分别下降6.1%和16.4%,这证明了选择性迭代本身优于固定深度策略。将双路因果注意力替换为传统的因果注意力,性能下降5.4%到8.5%,说明了跨迭代深度信息流动的重要性。移除深度感知LoRA与跨迭代残差连接,效果下降4.9%,确认了针对不同迭代目标进行架构优化的重要性。
训练策略方面: 相比TaH的两阶段训练,简单地用相同目标监督所有深度的预测会使性能下降4.3%,这说明不同迭代层应该承担差异化的优化目标。在训练中用决策器或动态“先知”策略替代静态“先知”策略,会因骨干网络与决策器的强耦合而导致训练不稳定甚至崩溃,从而证明了TaH两阶段训练策略的必要性。
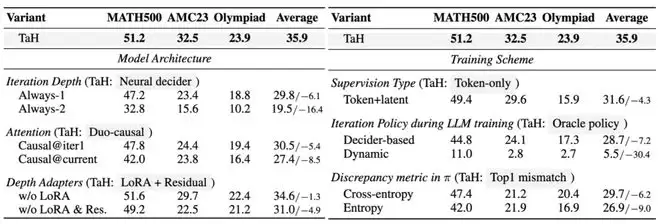
TaH在模型架构和训练策略上的消融实验结果。
总结与未来展望
TaH的意义,远不止于提出了一个新的循环Transformer变体或后训练方法。更重要的是,它探索了如何将“测试时计算扩展”推向更精细的token粒度。这项研究表明,更智能的动态算力分配策略,有时甚至比单纯堆砌更多计算资源能带来更优的效果。这为未来如何在有限资源下最大化模型推理能力的研究,指明了一个新的、富有启发性的方向。
参考文献
[1] Jaech, A., Kalai, A., Lerer, A., et al. OpenAI o1 system card. arXiv preprint arXiv:2412.16720, 2024.
[2] Guo, D., Yang, D., Zhang, H., et al. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025.
[3] Yang, A., Li, A., Yang, B., et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025.
[4] Abdin, M., Aneja, J., Awadalla, H., et al. Phi-3 technical report: A highly capable language model locally on your phone. arXiv preprint arXiv:2404.14219, 2024.
[5] Team, M., Xiao, C., Li, Y., et al. MiniCPM4: Ultra-efficient LLMs on end devices. arXiv preprint arXiv:2506.07900, 2025.
[6] Hutchins, D., Schlag, I., Wu, Y., Dyer, E., and Neyshabur, B. Block-recurrent transformers. Advances in Neural Information Processing Systems, 35:33248–33261, 2024.
[7] Saunshi, N., Dikkala, N., Li, Z., Kumar, S., and Reddi, S. J. Reasoning with latent thoughts: On the power of looped transformers. arXiv preprint arXiv:2502.17416, 2025.
[8] Zhu, R.-J., Wang, Z., Hua, K., et al. Scaling latent reasoning via looped language models. arXiv preprint arXiv:2510.25741, 2025.
[9] Wu, Y., Wang, Y., Ye, Z., Du, T., Jegelka, S., and Wang, Y. When more is less: Understanding chain-of-thought length in LLMs. arXiv preprint arXiv:2502.07266, 2025.
[10] Wang, S., Yu, L., Gao, C., et al. Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for LLM reasoning. arXiv preprint arXiv:2506.01939, 2025.
[11] Fu, T., Ge, Y., You, Y., et al. R2R: Efficiently na vigating divergent reasoning paths with small-large model token routing. arXiv preprint arXiv:2505.21600, 2025.
[12] Hu, E. J., Shen, Y., Wallis, P., et al. LoRA: Low-rank adaptation of large language models. ICLR, 2024.
[13] Hugging Face. Open R1: A fully open reproduction of DeepSeek-R1, January 2025. URL https://github.com/huggingface/open-r1.
相关攻略

研究揭示循环Transformer存在“潜空间过度思考”现象,即对已预测正确的词元继续迭代反而降低准确性。为此,团队提出TaH方法,通过轻量级决策器动态识别困难词元并仅对其增加迭代深度。该方法在多个基准测试中平均仅对约7%的词元进行二次迭代,显著减少计算量的同时将模型准确率提升了3 8%至4 4%。

来源:环球网 科技日报记者 张梦然 植物王国里,一个埋藏了数亿年的核心秘密,最近被来自全球的数十位科学家联手揭开了。 顶级期刊《科学》近期在线发表了一项堪称里程碑的研究。一个由英国剑桥大学桑斯伯里实验室、以色列耶路撒冷希伯来大学、美国冷泉港实验室及马萨诸塞大学阿默斯特分校等机构牵头的大型国际合作项目

高精度测序技术问世,首次绘制大肠杆菌NAD加帽RNA高分辨率图谱 来源:科技日报 科技日报记者 夏凡 近日,一项来自浙江万&里学院、香港浸会大学及宁波东方理工大学的研究,为微生物RNA研究领域带来了关键突破。团队开发出一种名为pNAD-seq的高精度测序技术,成功绘制出大肠杆菌NAD加帽RNA的最高

INSPATIO-WORLD:将任意视频转化为可自由探索的沉浸式四维世界 这项由浙江大学等顶尖研究机构联合开发的突破性技术,其详细技术报告已于2026年4月发布于预印本平台arXiv,论文编号为arXiv:2604 07209。研究团队将这一创新系统命名为INSPATIO-WORLD,其核心目标直指

面对复杂连续任务的长程规划,现有的生成式离线强化学习方法往往会暴露短板。它们生成的轨迹经常陷入局部合理但全局偏航的窘境。它们太关注眼前的每一步,却忘了最终的目的地。针对这一痛点,厦门大学和香港科技大
热门专题







热门推荐

在创意写作领域,每位作者都梦想拥有一位能深刻理解自身文风、甚至精准模仿个人笔触的创作伙伴。如今,这一愿景正借助个性化人工智能技术变为现实。本文将详细介绍LAIKA——一款专为文字创作者量身打造的AI写作工具,探讨其如何成为作家的得力助手。 简而言之,LAIKA致力于成为作家的“智能创意伙伴”。其核心

制作PPT时,许多用户的第一反应往往是感到棘手:寻找合适模板、调整排版、搭配图片、撰写文案……整套流程既耗时又费力。是否存在一种解决方案,能让我们更专注于内容构思与逻辑梳理,而非繁琐的设计操作?本文将详细介绍一款融合AI智能生成与灵活编辑功能的在线工具——爱设计PPT,探讨它如何显著简化幻灯片创作流

在内容营销实践中,效率与质量往往难以兼顾。营销团队既要应对高频次的内容产出需求,又要确保每一篇内容都能准确传递品牌信息、驱动用户转化与业务增长。这一普遍痛点,催生了市场对更智能、更一体化解决方案的期待——一个能够覆盖内容从策略规划、创作生产到发布分析全流程的平台。Pepper Content正是为此

在UI UX设计工具领域,Sketch、Figma和Adobe XD等传统软件曾长期占据市场主流。然而,随着远程办公与云端协同成为现代团队的核心需求,一个名为Pixso的新一代一体化在线设计协作平台正快速崛起,受到广泛关注。它不仅是一款强大的设计软件,更致力于成为连接产品、设计、开发全流程的数字化工

提到AI歌手,许多人可能还停留在“电子音效”或“机械感”的固有印象中。但今天介绍的这款AI歌声合成软件,或许将完全颠覆你的认知。X Studio,由北京红棉小冰科技有限公司研发,是一款兼容Windows与macOS双平台的智能语音合成工具。其核心功能,是让软件内置的虚拟歌手们精准“理解”乐谱信息,并