为什么那些在理解和推理上表现出色的多模态大模型(MLLM),一旦被应用于图像检索任务就容易表现失常?研究者们精准地将这一问题的根源归结为“范式冲突”。
这结论初看似乎有悖常理。当MLLM凭借其卓越的图文理解与逻辑推理能力成为AI领域焦点时,将其用于图像检索,特别是需要解析复杂修改指令的组合图像检索(CIR),理应是一次能力上的“降维打击”。然而现实却截然相反:将生成式大模型强行适配为判别式检索器后,模型常常出现令人困惑的能力衰退,甚至对原本能轻易解决的问题也开始出错。生成与判别之间的这道鸿沟,成为了大模型向检索领域落地的主要障碍。

如今,这一行业难题迎来了关键性突破。由AI国家队紫东太初团队与新加坡国立大学联合提出的ReCALL框架,通过一套独创的“诊断-生成-校准”闭环系统,从根源上化解了范式冲突。它使得大模型在成功转型为高效检索器的同时,完整保留了其原生的细粒度视觉推理能力。
这项重要成果已被计算机视觉顶级会议CVPR 2026正式收录。在CIRR、FashionIQ等主流图像检索基准测试中,ReCALL全面刷新了性能记录,更为大模型在下游任务中实现“能力无损迁移”开辟了一条全新的技术路径。
行业痛点:范式冲突引发的“智能倒退”
问题的核心在于“范式冲突”。原生的大模型遵循生成式范式,习惯于通过逐步的链式思考来解析图像中细粒度的视觉元素与关系。然而,传统的检索适配方法却采用了判别式范式,简单粗暴地将这种高维、复杂的推理过程压缩成一个单一的向量表示,用于计算图像相似度。
这种暴力的范式转换带来了一个致命后果——模型能力退化。
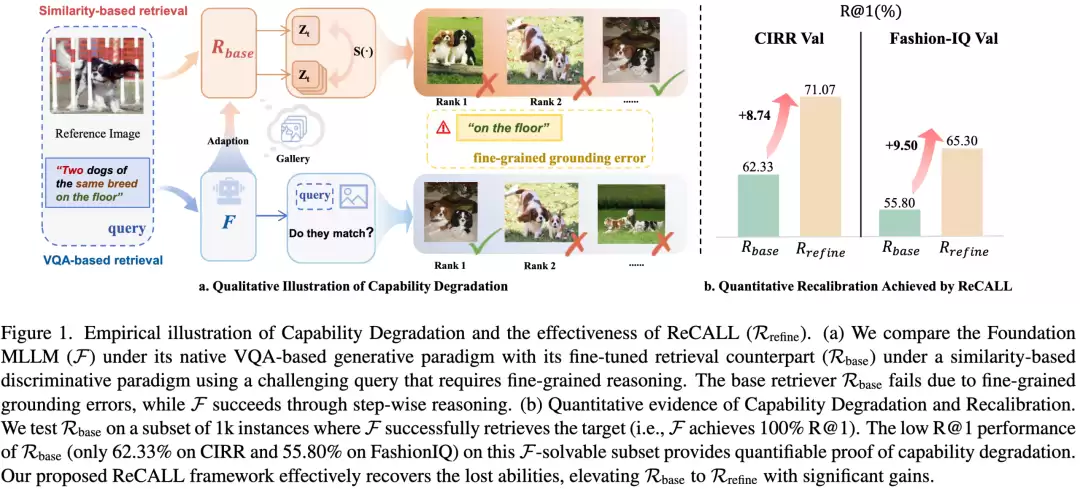
如上图左侧所示,面对“地板上的两只同品种狗”这类需要细粒度推理的查询时,原生大模型通过视觉问答可以轻松锁定目标图像。然而,经过传统微调方法改造后的检索器版本,却完全丧失了这种精准定位的能力,检索出的全是错误答案。
定量数据更为触目惊心:在原生大模型原本能100%答对的样本子集上,微调后的检索器在CIRR数据集上的R@1指标暴跌至62.33%,在FashionIQ数据集上更是跌至55.80%。模型不仅没有学到新的检索技能,反而将其与生俱来的深度推理天赋给“遗忘”了。
破局之道:ReCALL四阶段校准框架
既然问题出在初期的检索微调将模型的认知“带偏了”,那么解决方案的思路就变得清晰:如何将其引导回正确的轨道?
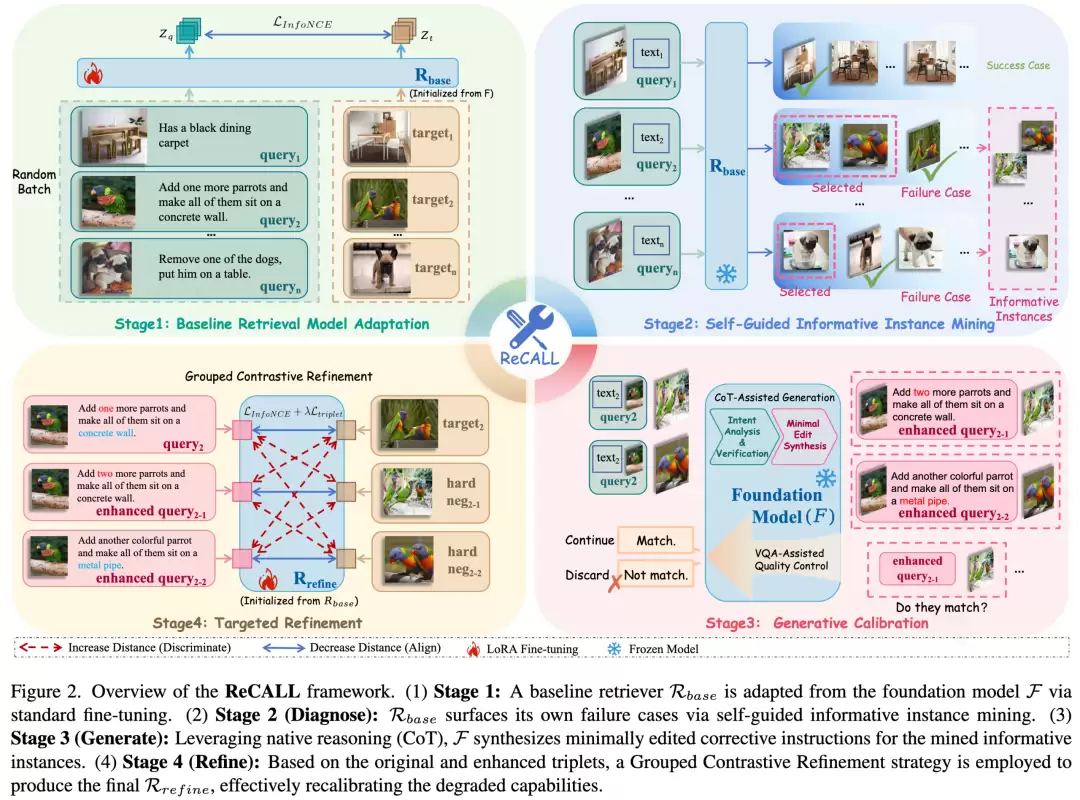
ReCALL框架的核心思想非常精妙:利用大模型自身的原生推理能力,来纠正其在检索向量空间中形成的认知偏差。整个流程被严谨地划分为四个阶段,其中第一阶段完成了基础的检索器初始化并暴露问题,后三个阶段则构成了精密的“诊断-生成-打磨”校准管线。
第一阶段:基础检索适配
首先,研究人员使用标准的对比学习损失函数,将原生大模型微调成一个基础检索器。这一步赋予了模型基础的图文匹配与图像搜索能力,但正如前文所述,这种单向量压缩也直接诱发了“能力退化”的症状。
第二阶段:自我诊断
常言道,错题本就是最好的老师。该框架让基础检索器在训练集上运行,专门收集那些它判断错误的样本。这些能够“迷惑”检索器的负样本图像,往往与正确答案仅有极其细微的视觉差别,它们正是模型能力退化、认知最模糊的“盲区”所在。
第三阶段:生成校正
获取这些“错题”后,研究团队设计了一套严密的链式思考诱导机制,让原生大模型来担任“讲解员”。这个过程被拆解为两个核心步骤:
首先是意图分解与验证:大模型会将原始的文本修改指令拆解成多个“原子意图”,并逐一对照参考图像和错误答案图像进行核查,精准定位究竟是哪个细粒度意图在干扰图像中被违背了。
接着是最小编辑合成:在抓住矛盾点后,大模型会保留那些在错图中依然成立的意图描述,仅对违背的部分进行针对性重写,从而以“打补丁”的方式合成出一条全新的、指向错图的修改指令文本。
通过这种精巧的设计,框架自动生成了从“参考图”指向“错图”的纠错三元组数据。这种极小幅度的文本编辑,在语义上精准对应了目标图与干扰图之间微妙的视觉差异,从而为检索模型提供了高密度、显式的细粒度对齐监督信号。更重要的是,“最小编辑原则”确保了新构建的数据与原始数据集的分布高度一致,再经过严格的语义一致性过滤,最终得到高保真的纠错信号。
第四阶段:针对性打磨
最后,通过分组对比学习来完成模型的最终进化。框架将原始查询文本和对应的纠错查询文本打包在同一训练批次中进行“对冲”学习,配合双重优化目标,迫使检索器去明确区分那些极其细微的视觉-语义边界,最终将原生大模型的深度推理能力完美内化到其向量表示中。
通过这套组合拳,检索器不仅找回了丢失的细粒度推理能力,还将其深刻地编码到了自己的向量表示空间里。
实测成绩:全场景刷新纪录,细粒度能力拉满
ReCALL框架的有效性在主流图像检索基准测试中得到了充分验证。
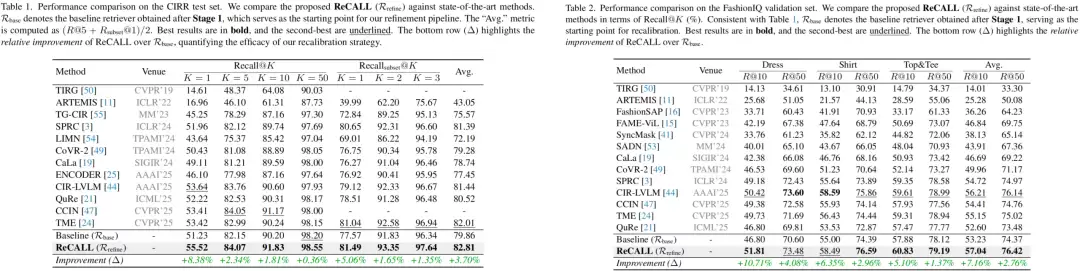
在开放域复杂图像检索数据集CIRR上,ReCALL创造了55.52%的R@1新纪录,相较于强大的基线模型实现了8.38%的相对性能提升。而在专门考察细粒度区分能力的测试子集上,其R@1指标更是达到了惊人的81.49%。在FashionIQ这类充满高度相似干扰项的细粒度时尚检索数据集上,ReCALL同样表现最佳,平均R@10达到57.04%。

从上方的实际检索案例可以直观看到,基线模型遇到“正视镜头”、“半袖”这类细粒度条件时几乎束手无策;而经过ReCALL校准优化后的模型,则展现出了精准的眼光,能够成功锁定符合所有复杂条件的目标图像。
结语
ReCALL的成功,不仅在于它刷新了组合图像检索的性能上限,更在于它揭示并修复了多模态大模型向下游任务迁移时存在的一道隐形裂痕。
这项研究指明了一个重要方向:让大模型胜任检索任务,不应只是粗暴地将其高维的“生成式智慧”压缩降维成单一的“判别式向量”。从“盲目对齐”走向“诊断—生成—内化”的逻辑闭环,标志着大模型的检索适配进入了一个新阶段——一个强调保留与激发其原生深度推理能力的新阶段。
当我们不再单纯依赖海量外部数据去“喂养”模型,而是引导它运用自己的思维链去剖析错题、缝合认知盲区时,模型找回的远不止是丢失的视觉感知能力,更揭示了生成与判别两大AI范式走向深度融合的广阔前景。这或许正是大模型在诸多垂直领域实现真正“能力无损适配”与高效落地的关键一步。
论文链接:https://arxiv.org/abs/2602.01639
项目代码:https://github.com/RemRico/Recall