全球首个开源医疗视频理解大模型发布 附六千组测试集与评测榜单
手术视频的“黑盒”,被一脚踢爆了。
就在这两天,GitHub和Hugging Face社区上线了一枚医疗大模型领域的“核弹”。
全球规模最大、性能最强的医疗视频理解大模型——uAI Nexus MedVLM(中文名:元智医疗视频理解大模型)宣布开源。
最惊人的是,这玩意儿是真的能看懂手术。
相关论文已被CVPR 2026收录,团队还同步发布了一套由6245个视频-指令对构成的标准测试集。
这意味着什么?医疗视频理解这个领域,终于有了一把“公共标尺”。
而如此兼具规模与精度的医疗视频数据开源,在业内尚属首次。
到底有多能打?
先来看看uAI Nexus MedVLM的硬指标:
- 汇聚超53万条视频-指令数据;
- 支持4B/7B参数规模,单卡就能部署;
- 整合8个专业医学数据集,覆盖内镜、腹腔镜、开放手术、机器人手术、护理操作……几乎你能想到的手术场景,它全包了。
那么,实测效果究竟如何?
其Demo的体验设计非常友好:界面核心模块清晰,支持直接上传手术视频文件。
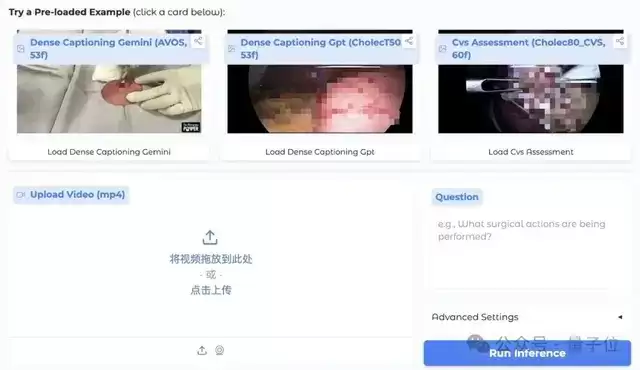
用户既可以上传自己的医疗视频,也可以使用预置的示例直接测试。
以示例中的腹腔镜胆囊切除术视频为例,测试了三个临床核心维度,并与通用大模型(GPT-5.4、Gemini-3.1及某国产大模型)进行了输出对比。
定量实测的数据堪称碾压。在手术安全评估任务上,其准确率高达89.7%。
作为对比,GPT-5.4只有16.4%,Gemini-3.1是24.2%,某国产大模型是30.9%。
也就是说,uAI Nexus MedVLM的准确率是GPT-5.4的近5.5倍,是Gemini-3.1的3.7倍,是国产大模型的近3倍。
在时空动作定位任务上,其mIoU指标是Gemini-3.1的3.2倍,是国产大模型的3.7倍,是GPT-5.4的47倍。
在视频报告生成任务(5分制)上,uAI Nexus MedVLM 拿到4.24分,而GPT-5.4为3.98分,某国产大模型为3.5分,Gemini-3.1为3.7分。
更关键的是,通过MedGRPO强化学习优化后,相比基座模型,其器械定位能力提升了14%;手术步骤识别能力暴涨52%;手术描述质量提升了16%~25%。
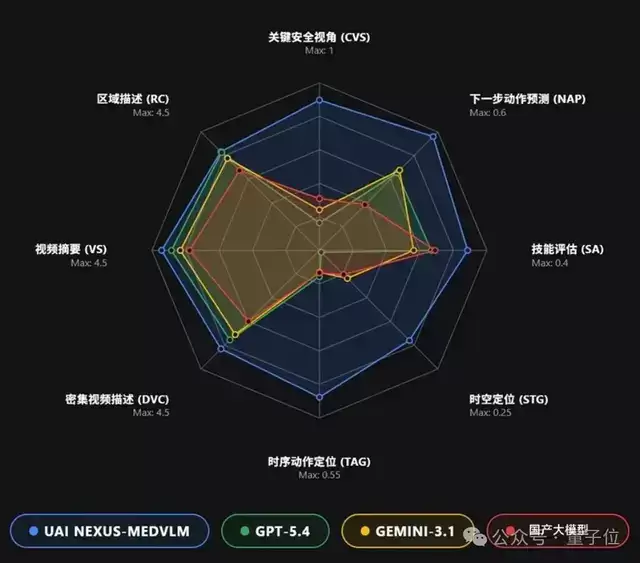
uAI Nexus MedVLM覆盖了内镜腔镜手术、开放式手术、机器人手术、护理操作等多类临床场景,在涵盖的8个手术数据集上,针对视频摘要(VS)、关键安全视野评估(CVS)、下一步操作预测(NAP)、技能评估(SA)、时间动作定位(TAG)、密集视频描述(DVC)、区域级描述(RC)和时空基础化(STG)这8项任务,表现均超越了GPT和Gemini系列模型。
再看定性实测的结果。将一段标记了绿色框的手术视频发给大模型,要求其进行描述。
输入问题:你是一名专攻微创手术的外科分析专家。这段视频展示了腹腔镜胆囊切除术的内镜画面。请描述0.0秒时,边界框内物体的状态,以及在0.0~29.0秒时间段内的操作。

标准答案是:钳持续夹持并将胆囊向手术视野的左上方牵拉,提供反向牵引和暴露。
GPT-5.4只能给出笼统的描述,未能识别出具体器械。
Gemini-3.1则将工具错误识别为“电凝钩”,描述成了不正确的操作。
某国产大模型则无法识别出正确的手术操作步骤。
只有uAI Nexus MedVLM,给出了接近标准答案的描述:
位于左上方的抓钳持续向上并朝中央牵引胆囊,保持张力并为钩子暴露分离平面。
随后,示例中展示的8个任务表现,一个比一个令人印象深刻。
为避免真实手术场景带来的观感不适,选取了一段温和的示例视频,内容是护士给患者监测身体指标。
视频涵盖了护士查看血压计、查看体温计、护理记录、洗手、测量血压、测量体温、脉搏测量、呼吸测量等工作。
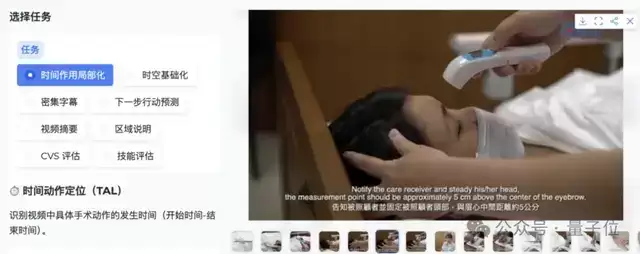
现在,随机考察8个任务中的一个,比如「时间动作定位」。
输入问题:脉搏测量动作发生在什么时间?
标准答案是:46.0-61.8seconds。
模型给出的预测是:43.0-65.0seconds。前后误差不超过4秒,且正确答案完全落在预测范围内。
为什么手术视频是AI最难啃的骨头?
在AI医疗领域,将AI用于影像辅助诊断、病历书写、质控管理等场景早已不是新鲜事,在不少医院已经落地。
但有一个方向,至今仍是公认的“无人区”,那就是手术视频理解。
之前少有人涉足,原因在于三重地狱级难度,和静态影像完全不是一个量级:
第一关:数据极难获取。临床手术视频涉及患者隐私与医学伦理,获取本身就困难重重。
即便拿到了原始视频,让专业医生进行逐帧标注?其成本之高足以劝退绝大多数团队。
第二关:没有统一评测标准。这是行业里一个很尴尬的现实:各家用自己的数据集、自己的指标,模型效果根本没法横向比较。
你说你强,他说他强,缺乏公认的标尺,严重阻碍了整个赛道的发展。

第三关:任务本身极端复杂。手术视频的难,在于对空间、时序、语义的理解需要达到高度专业的水平。
例如,它需要精准识别毫米级的器械位置和解剖结构。稍微偏一点,可能就认错了。
而且手术步骤有严格的时序逻辑,胆囊得先分离再切除,不能反过来。AI如果看不懂时序,就根本无法理解手术进程。
各种约束叠加,再顶级的模型也只能望而却步。
但现在,这个无人区被uAI Nexus MedVLM一脚踩穿。
它不只是“炫技”,是真的能救命。
那么,这模型具体能干嘛?
术前:分析主刀医生过往的上万台手术视频,挖掘临床规律、辅助优化手术方案。
想象一位刚站上手术台的临床医生,即将做一台胆结石微创手术。
以前只能靠记忆和经验;现在AI把成千上万台顶级专家的手术经验沉淀下来,相当于有了一个最强的大脑,来辅助完成这台手术。
术中:在分离胆囊管、显露安全视野等关键步骤,实时给出指引;对违规操作、动作偏差进行毫秒级预警,成为医生的“第三只眼”。
术后:自动完成总结与结构化记录,这通常会占用医生大量时间,但现在,可以一键生成标准化报告。这台手术的经验,也能成为下一位医生的“决策依据”。
手术质控、术中安全、报告自动化、医学教学……uAI Nexus MedVLM的价值,远不止于技术突破。
在中国,优质医疗资源集中在三甲医院,基层医院医生成长周期长、手术经验积累慢。
而uAI Nexus MedVLM可以把顶级专家的手术经验“沉淀”下来,基层医院的医生也能获得“专家级”的术中辅助。
这或许才是AI真正理解手术视频的意义所在。
全球开发者,新机遇来了
这次发布,最值得关注的不仅是uAI Nexus MedVLM本身。
开发这一模型的联影智能,首次向全球开源大规模高质量医疗视频标注数据和模型,并提供了一个更具可比性的评测基准。
这意味着什么?手术视频理解垂直领域,终于有了一个“全球公共测评体系”。
以前,各家模型各说各话,效果没法比。
现在,拉出来在同一个数据集上跑一跑,谁强谁弱,一目了然。
而这,还只是开始。
研发团队同步上线了医疗视频理解大模型榜单,面向全世界开发者发出挑战。
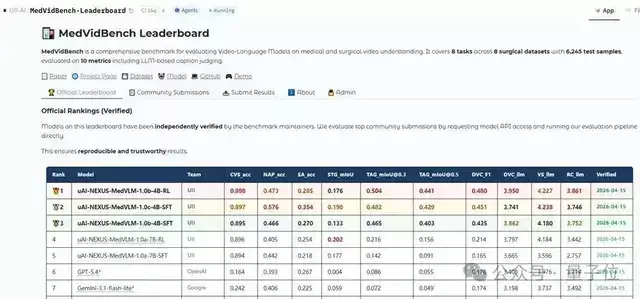
这是一个综合基准测试,用于评估视频语言模型在医疗和外科视频理解方面的表现。
开发者可提交自有模型结果,由系统基于标准自动评分,形成动态更新的统一排行榜。
当全球开发者都能下载模型、使用数据集、上传自己的成果时,一场关于谁能在医疗视频理解能力边界上再推进一步的竞赛,就此展开。
这个过程中,医生上传的罕见病例、复杂手术视频,尤其是现有模型表现不足的案例,都会成为极为珍贵的真实数据,持续驱动技术迭代。
医疗视频AI正在迎来面向全球开发者的黄金时代。
未来,uAI Nexus MedVLM将与具身智能融合,完善感知-推理-执行的能力闭环。从手术室拓展到更多临床场景,推动医疗全流程智能化。
数据开放、模型共享、全球协同……这条路,才刚刚开始。
相关攻略

手术视频的“黑盒”,被一脚踢爆了。 就在这两天,GitHub和Hugging Face社区上线了一枚医疗大模型领域的“核弹”。 全球规模最大、性能最强的医疗视频理解大模型——uAI Nexus MedVLM(中文名:元智医疗视频理解大模型)宣布开源。 最惊人的是,这玩意儿是真的能看懂手术。 相关论文

上海新华医院与商汤医疗合作推出基于“深思考”大模型的AI儿童全科医生,赋能基层儿科诊疗与居家健康管理。该系统将顶尖临床经验转化为可交互AI助手,通过高质量医学知识库与临床推理模拟,实现儿科领域专业应用,并以平台化模式推动医工融合与专科智能体开发,为智慧医疗转型提供。

12月22日消息,据云知声最新公众号透露,云知声正式推出医疗领域专家级大模型全新力作——“山海・知医大模型5 0”。这一里程碑式的发布,标志着其医疗大模型完成了从“智能工具”到“临床协作者”的关键跨
热门专题







热门推荐

为庆祝成立50周年,苹果在全球多地门店举办系列庆祝活动。最盛大的庆典在其总部ApplePark举行,员工齐聚草坪,传奇音乐人保罗·麦卡特尼登台献唱,首席执行官蒂姆·库克也参与其中。这场科技与艺术交融的盛会,既是对过往传奇的致敬,也寓意着新篇章的开启。

苹果公司成立五十周年之际,首席执行官蒂姆·库克发布内部信回顾历程。信中指出,公司从车库中的一台原型机起步,如今全球活跃设备已达25亿台。库克强调,未来需主动创造而非等待,并鼓励员工铭记创新精神,共同把握机遇,开创下一个五十年。

苹果CEO库克在专访中回顾了iPod的诞生历程。该产品以口袋装千首歌的能力革新了音乐消费方式。其爆红要求苹果在三个月内生产约1500万台,这极大考验了供应链。此次极限压力测试为苹果锻造出世界级供应链能力奠定了基础。库克还透露,首台原型机播放的第一首歌是《HeyJude》。

知名投资人段永平家族办公室持仓市值升至约200亿美元。本季度清仓阿里,减持苹果、台积电;重仓AI与电动车赛道,大幅增持英伟达并新建仓特斯拉,拼多多获增持。其首次跨足Web3领域,建仓稳定币发行商Circle,显示对合规区块链基础设施的关注。

Mac内置的“缩放”辅助功能可放大屏幕细节。通过系统设置开启该功能后,可选择画中画或全屏模式。用户可使用修饰键配合触控板手势、快捷键组合、双击Control+Option或鼠标智能缩放等多种方式灵活操作,满足不同场景下的查看需求。