AI视频生成新纪元 Seedance 2.0迎来最强竞争对手
Gemini Omni的正式亮相,证实了此前业内的广泛预测。然而,它远不止是一个视频生成模型。根据谷歌的官方定义,这是一个能够处理任意模态输入、并生成任意模态输出的“全能型”基础模型,视频创作仅仅是其当前能力版图中的一个重要组成部分。

在发布会上,DeepMind首席执行官Demis Hassabis展示了多个令人印象深刻的演示案例。用户仅需上传一张个人照片,Omni就能智能地重构人物所处的背景环境,轻松切换多种艺术风格。简单地画一个圆圈,它能理解并生成一个深邃的黑洞;用文字描述“傍晚林间漫步”,它会渲染出氛围各异的场景。任何原始素材,在Omni的眼中都能成为构建全新视觉现实的创意画布。
其核心技术突破,在于将文本、视频、图像乃至交互式仿真,统一整合进一个连贯的生成框架中。具体而言,Omni深度融合了谷歌旗下几款最先进的生成式媒体模型,包括图像模型Nano Banana、视频生成模型Veo,以及用于模拟物理世界的Genie模型。
这意味着,当用户输入“制作一段关于蛋白质折叠过程的黏土动画解说”这样的指令时,模型输出的不再是枯燥的文字说明,而是直接包含α螺旋、β折叠等三维结构动态演示的科普教学视频。
提示词:claymation explainer of protein folding, everything is made out of clay, no hands, stop motion, accurate
消息发布后,立刻有技术爱好者将Omni与当前热门的视频生成模型Seedance 2.0进行了多维度对比,从画面生成质量、运动动态自然度到跨帧一致性进行了全面评估。
视频来源:X@TopviewAIhq
总体来看,Seedance 2.0在通用场景下表现依然稳健,而Gemini Omni则在视频编辑与物理模拟等特定领域展现出了更突出的能力。根据官方技术博客的阐述,Omni的核心优势目前主要集中在这两大方面。
动动嘴就能剪视频:AI视频编辑进入「自然对话」时代
除了自动生成教学视频,智能视频编辑是Omni主打的另一大核心应用场景。它支持用户上传自拍视频或任意影视素材,随后只需使用自然语言进行描述,就像与真人剪辑师沟通一样,即可对视频进行多轮精细化修改,调整视觉风格或添加特定元素。这套直观的交互逻辑,与之前Nano Banana在图片编辑上实现的“对话式修图”思路一脉相承。
在最新的演示案例中,这种能力的强大之处尤为明显。拍摄一段手触摸镜面的普通视频,只需对Omni说:“当手指触碰到镜子时,让镜面像水面一样泛起美丽的涟漪,同时将手臂的材质变为反光的金属。”
生成结果令人惊叹。原始视频中人物的动作和构图得到了完美保留,但镜面的物理属性和手臂的材质被精准且逼真地替换了。更关键的是其“多轮对话与迭代能力”,用户的每一个新指令都会基于上一次的生成结果继续优化,Gemini Omni会智能地保持人物特征、环境光照、物理效果及整体场景上下文的高度一致性。
不仅懂像素,更懂物理:生成式AI理解真实世界法则
对物理世界的精准模拟,则是Gemini Omni技术含金量最高的部分。谷歌表示,Omni在模拟动能、重力、材质碰撞等物理现象时实现了“质的飞跃”。这意味着,更为逼真的动态视频、符合物理规律的图像以及复杂的交互式仿真内容,现在都能通过简单的指令生成。
当要求模型生成“一颗弹珠在复杂连锁反应轨道上快速滚动”的视频时,Omni展现出了对重力加速度、动量传递和碰撞能量的精确理解。
另一个更复杂的案例是“字母表创意物品视频”。当提示模型展示26个英文字母,每个字母需对应一个非常规物体(例如A对应宇航服、C对应水豚、D对应迪斯科球)时,它的表现超越了简单的图文匹配。
提示词:Prompt: The video shows items of the alphabet. An unusual item starting with each letter is shown sitting on a table . All 26 letters must be represented by 26 items with matching lower thirds displaying the letter. Only one item and lower third at a time. Each lower third must look like a black marker written on a slip of paper in the bottom left. Rapid fire, roughly 9 frames per item at 24FPS. Last frame is a slip of paper "THE END". The whole video is accompanied by calm smooth music.
Omni同时完美处理了字母与物体的语义对应、画面切换节奏、字幕呈现形式、特定帧率要求、背景音乐风格以及视频收尾方式。这背后,是模型深度理解语言指令、并将其与视觉元素及深层概念进行关联的复杂能力,而非进行浅层的图像关键词匹配。
目前,Gemini Omni Flash版本已同步集成至所有谷歌产品线,面向全球的Google AI Plus、Pro和Ultra订阅用户开放。用户可以通过Gemini独立应用和Google Flow工作流平台来调用它。在Gemini的网页端或移动端,只需选择“生成视频”功能即可体验Omni的强大能力。
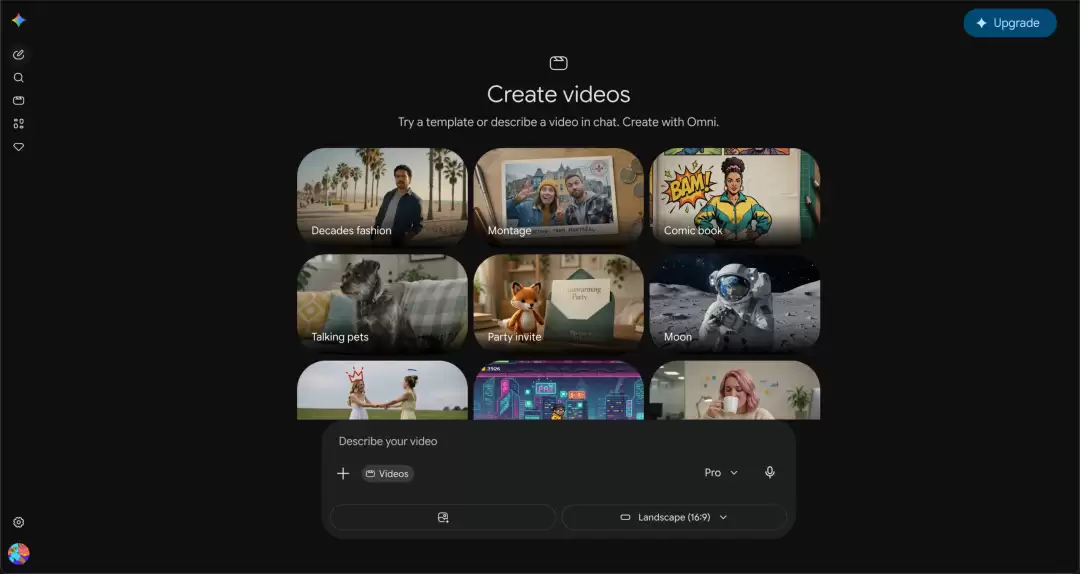
Gemini平台提供了年轻时尚、电影蒙太奇、美式漫画、会说话的宠物、派对邀请函等共18种预设视频风格。以Pro级别账户为例,用户每日拥有3次视频生成机会。只需输入一段简单的提示词,例如“一位男性汽车博主,身着女装JK制服,梳着双马尾辫,站在一辆经典跑车前”,并选择“80年代MV”风格,就能快速获得一段风格鲜明的创意短片。
谷歌还宣布,YouTube Shorts和YouTube Create App的用户将从本周起免费获得部分相关能力;未来几周内,公司将通过API向广大开发者和企业客户开放Gemini Omni的调用权限。该模型能够将用户提供的图片、文字、视频片段和音频作为参考素材,智能地整合成一段连贯、高质量的多模态输出。
为了应对公众对AI生成内容伪造的担忧,谷歌特别强调,所有由Omni生成的视频都会嵌入肉眼不可见的SynthID数字水印,并且可以通过专用工具轻松验证其AI生成来源。针对真人肖像的使用,它还推出了可安全克隆用户外貌和声音的“数字Avatar”功能。

回顾AI视频生成技术的发展,谷歌曾凭借Nano Banana将Gemini的多模态能力成功拓展至图像生成与编辑领域。如今,Gemini Omni正将同一套“自然语言交互”的先进理念带入视频领域,并致力于打造视频创作领域的“Nano Banana式”颠覆时刻。
这对于广大视频内容创作者的直接影响,是视频制作门槛的又一次大幅降低:一段用手机随手拍摄的生活片段、一张风格参考图、甚至一段背景音乐,都可能成为可以“对话式”深度编辑的原始素材。而更深远的变革在于,当视频内容能够像文本一样被一句话持续修改和迭代时,整个内容生产的速度、真实性验证机制、版权界定标准乃至平台的内容治理规则,都将被共同推向一个全新的发展阶段。
相关攻略

在AI视频生成技术快速发展的今天,一款名为Seedance 2 0的模型正成为行业焦点。它并非诞生于海外实验室,而是由中国科技公司字节跳动旗下的Seed团队自主研发。作为中国AIGC(人工智能生成内容)领域的又一重大突破,该模型致力于攻克视频生成中的物理一致性难题,旨在为用户提供具备电影级画质与流畅

Seedance 2 0 提供了五种高效的 Facebook 广告视频批量制作解决方案:一、分镜脚本结合豆包 AI 批量文案生成;二、全能参考模式与种子图素材复用;三、九宫格分镜接力智能生成;四、音频驱动与精准口型同步技术;五、剪映 AI 模板与成品视频智能注入。这些方法能系统化提升独立站广告素材的

当Seedance 2 0生成的背景视频无法满足绿幕抠像或动态壁纸的制作需求时,需系统性地调整输出参数、进行后期处理与格式转换。核心步骤包括:设置H 264 Rec 709 30fps 无B帧编码、利用FFmpeg提升绿幕纯度、转换为WebP动画与APK动态壁纸格式,或采用DaVinci Resol

评估一款AI视频工具是否真正好用,不能只看官方宣传,更要看它在真实创作者手中的表现。Seedance 2 0究竟如何?我们不妨抛开参数,直接看看来自不同平台、不同背景的一线用户们,是如何用它干活、又是如何评价它的。 一、操作门槛与新手适配性 对于大多数创作者而言,第一个问题往往是:我能不能快速上手,

想在Coze平台快速搭建一个能自动生成电商带货视频的AI机器人,但面对复杂的配置流程感到无从下手?这是许多新手开发者遇到的共同挑战。别担心,本文将为你提供一套清晰的五步操作指南,帮助你从零开始,高效构建一个功能完整的自动化视频生成工作流。 一、创建基础Bot并完成核心配置 第一步是为你的AI助手建立
热门专题







热门推荐

近日,国家能源局联合发改委、工信部、国家数据局正式印发《关于促进人工智能与能源双向赋能的行动方案》。这份重磅文件的核心思路非常清晰:一方面,以坚实的能源基础支撑人工智能(AI)的快速发展;另一方面,利用AI技术赋能能源行业转型升级。其核心目标是推动能源、算力、应用场景、数据与算法模型五大关键要素深度

在挑选文生视频工具时,若您正在智谱清影与Runway Gen-3之间权衡,那么了解两者在生成效果上的具体差异,将有助于您做出更明智的选择。本文将从画质清晰度、细节纹理、运动自然度与视频连贯性等核心维度,通过实测对比为您详细解析。 一、画质与分辨率表现 首先对比硬性指标。智谱清影基于CogVideoX

想用通义万相生成一张科技感十足的数据可视化背景,但出来的画面总觉得少了点“内味儿”?数字界面、粒子流、电路纹理这些关键元素一个不见,画面平平无奇?这通常不是工具的问题,而是提示词没有精准锚定科技可视化的核心要素,或者模型参数没调到最佳状态。别急,下面这几种方法,能帮你把想法精准地“翻译”成画面。 一

想要在Vidu生成的视频中实现流畅的慢动作或快进效果?虽然模型界面没有提供直接调整播放速度的滑块,但通过巧妙的提示词设计、利用内置功能,或结合后期处理工具,你完全可以精准掌控视频的节奏与时间感。本文将为你详细解析四种实用方法,从生成前到生成后,全方位满足你的创作需求。 一、通过精准提示词引导运动节奏

当您使用海螺AI生成的英文论文在提交查重时遭遇高重复率或AIGC检测异常,请不要急于归咎于工具本身。核心原因在于,尽管AI生成的文本格式标准、语法地道,但其语言模式和常见短语组合,并未针对知网、维普、万方等中文查重数据库的语义比对逻辑进行专门优化。换言之,机器认为流畅自然的表达,在查重系统的算法看来