谷歌Gemma 4大模型本地部署安装配置完全指南
4月3日凌晨,谷歌DeepMind向开源AI社区投下了一枚重磅冲击波:Gemma 4正式发布。
这个拥有310亿参数的模型,性能提升堪称“暴力”。在数学竞赛基准上,它从上一代的20.8%直接跃升至89.2%;编程能力方面,LiveCodeBench得分从29.1%飙升至80%。更关键的是,它采用了Apache 2.0完全开源协议——这意味着下载、修改、商用,谷歌完全不加限制。
最令人兴奋的或许是,你现在就能把它装在自己的电脑上。无需联网,没有API密钥,不按Token付费,所有数据都留在本地。接下来,就让我们一步步把它跑起来。
先搞清楚你要装的是什么
Gemma 4并非单一模型,而是一个覆盖全场景的四档矩阵,从手机到服务器都有对应选择:
? E2B — 极轻量·端侧版
有效参数2.3B,支持128K上下文,具备图片和音频处理能力。量化后体积不到3GB,足以在手机或树莓派上流畅运行。
? E4B — 轻量·笔记本版
有效参数4.5B,同样支持128K上下文和多模态。经过Ollama量化后约9.6GB,任何拥有16GB内存的笔记本电脑都能轻松驾驭。
⚡ 26B MoE — 性价比之王(最推荐)
总参数2520亿,推理时仅激活380亿,却拥有256K超长上下文。量化后体积约14–18GB,速度接近4B模型,而质量则逼近31B的旗舰版。
? 31B Dense — 旗舰·工作站版
全量3070亿参数,256K上下文,在Arena AI开源榜上位列第三。量化后约20GB,建议配备双RTX 4090或A100 80G显卡的工作站使用。
对于普通开发者和个人用户,E4B或26B MoE是首选。E4B几乎兼容所有16GB内存的电脑,而26B MoE则需要16–24GB显存的独立显卡。下面的教程将围绕这两款展开。
方法一:Ollama(最快,5分钟搞定)
适合人群:Mac/Windows/Linux用户,习惯命令行操作,需要本地API。
Ollama是目前最便捷的本地模型运行方案。安装完成后,一条命令就能启动Gemma 4,并在11434端口暴露兼容OpenAI格式的API,方便对接各类AI应用。
# 第一步:安装 Ollama
curl -fsSL https://ollama.com/install.sh | sh
# Windows用户:前往 ollama.com 下载安装包 .exe 双击即可
# 第二步:拉取模型(根据硬件选择一款)
ollama pull gemma4 # 默认E4B版本,约9.6GB,适合大多数人
ollama pull gemma4:e2b # E2B版本,2.3B有效参数,极致轻量
ollama pull gemma4:26b # 26B MoE版本,约16GB,追求高质量
ollama pull gemma4:31b # 31B Dense版本,约20GB,旗舰性能
# 第三步:运行并开始对话
ollama run gemma4
# 验证本地API是否正常(端口11434)
curl https://localhost:11434/api/generate \
-d '{"model":"gemma4","prompt":"你好,介绍一下你自己"}'需要注意的是,Ollama默认的gemma4标签指向E4B版本(9.6GB)。若想运行工作站版本,需明确指定gemma4:26b或gemma4:31b。下载完成后,可使用ollama list命令查看本地已有哪些模型。
方法二:LM Studio(有界面,零门槛)
适合人群:不习惯命令行,偏好可视化管理,喜欢内置的类ChatGPT对话界面。
如果看到命令行就感到头疼,LM Studio会是你的理想选择。它提供了漂亮的桌面图形界面,找模型、下载、对话,全部通过点击完成。
① 下载 LM Studio
访问官网lmstudio.ai,下载对应操作系统(Mac/Windows/Linux)的版本,安装后打开。
② 搜索并下载 Gemma 4
点击左侧的“发现”按钮,在搜索框输入gemma4,找到E4B的Q4量化版本点击下载。推荐选择Q4_K_M量化方式,它在体积和质量之间取得了良好平衡。
③ 加载并开始对话
下载完成后,点击左侧“对话”图标,在顶部下拉菜单中选择刚刚下载的Gemma 4模型,即可开始对话。体验与ChatGPT网页版几乎一致,区别在于它完全运行在你的本地机器上。
④(可选)开启本地 API 服务器
点击左侧“开发者”图标,启动本地服务器(默认端口1234)。之后,你就可以在自己的代码中通过兼容OpenAI格式的API来调用Gemma 4——调用方式与调用ChatGPT API完全相同,只需将base_url改为https://localhost:1234/v1即可。
Mac 用户专属:MLX 加速,速度暴涨
适合人群:使用Apple Silicon M系列芯片(M1/M2/M3/M4)的Mac用户。
如果你用的是M系列Mac,有一个专属工具能让推理速度飞起来——mlx-vlm。在Gemma 4发布当天,mlx-vlm v0.4.3版本就同步支持了全系列模型,社区在几小时内上传了125个量化版本。结合TurboQuant KV缓存压缩技术,KV缓存的内存占用从13.3GB压缩至4.9GB,减少了63%。实测速度可达84+ Tokens/s。
# 安装 mlx-vlm
pip install mlx-vlm
# 运行 Gemma 4 E4B(4-bit 量化版)
python -m mlx_vlm.generate \
--model mlx-community/gemma-4-e4b-it-4bit \
--prompt "帮我解释一下 Ja va 中 ThreadLocal 的内存模型"我的电脑能跑哪个版本
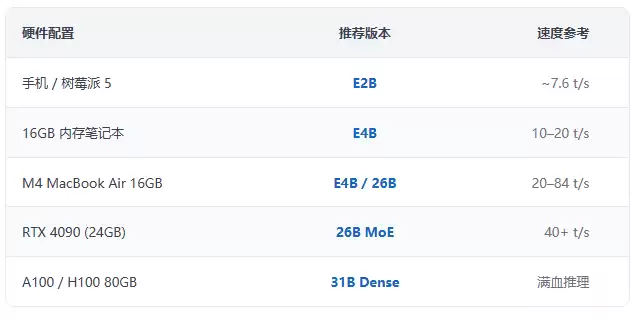
即便没有独立显卡也无需担心。CPU推理虽然速度较慢,但E2B或E4B的量化版本在拥有32GB内存的Mac上,速度完全在可接受范围内。值得注意的是,31B模型使用Q4_K_M量化后,在MMLU基准上的表现仅下降约1.5–2个百分点,日常问答几乎感知不到差异。
为什么这次和以前真的不一样
你可能经历过多次“谷歌发布开源模型”,但下载后却发现存在各种商业限制。这一次,情况截然不同。
? 以前(Gemma 1 / 2 / 3)
采用谷歌自定义许可协议,限制商业用途,禁止用于合成数据生成。谷歌可随时单方面修改条款,导致企业法务处理成本高昂。
? 现在(Gemma 4)
采用Apache 2.0协议,完全免费商用,允许修改和再分发,可用于微调和合成数据。谷歌不能单方面反悔,企业可以放心使用。
Apache 2.0是开源世界最宽松的协议之一。相比之下,Meta的LLaMA系列在月活用户超过7亿后,仍需向Meta申请额外授权——而Gemma 4则完全没有这个后顾之忧。Hugging Face的联合创始人兼CEO Clément Delangue在发布当天表示:
“这是一个巨大的里程碑。我们非常激动能在发布首日就在Hugging Face上支持Gemma 4家族。”
—— Clément Delangue,Hugging Face 联合创始人兼 CEO
热门专题







热门推荐

近日,国家能源局联合发改委、工信部、国家数据局正式印发《关于促进人工智能与能源双向赋能的行动方案》。这份重磅文件的核心思路非常清晰:一方面,以坚实的能源基础支撑人工智能(AI)的快速发展;另一方面,利用AI技术赋能能源行业转型升级。其核心目标是推动能源、算力、应用场景、数据与算法模型五大关键要素深度

在挑选文生视频工具时,若您正在智谱清影与Runway Gen-3之间权衡,那么了解两者在生成效果上的具体差异,将有助于您做出更明智的选择。本文将从画质清晰度、细节纹理、运动自然度与视频连贯性等核心维度,通过实测对比为您详细解析。 一、画质与分辨率表现 首先对比硬性指标。智谱清影基于CogVideoX

想用通义万相生成一张科技感十足的数据可视化背景,但出来的画面总觉得少了点“内味儿”?数字界面、粒子流、电路纹理这些关键元素一个不见,画面平平无奇?这通常不是工具的问题,而是提示词没有精准锚定科技可视化的核心要素,或者模型参数没调到最佳状态。别急,下面这几种方法,能帮你把想法精准地“翻译”成画面。 一

想要在Vidu生成的视频中实现流畅的慢动作或快进效果?虽然模型界面没有提供直接调整播放速度的滑块,但通过巧妙的提示词设计、利用内置功能,或结合后期处理工具,你完全可以精准掌控视频的节奏与时间感。本文将为你详细解析四种实用方法,从生成前到生成后,全方位满足你的创作需求。 一、通过精准提示词引导运动节奏

当您使用海螺AI生成的英文论文在提交查重时遭遇高重复率或AIGC检测异常,请不要急于归咎于工具本身。核心原因在于,尽管AI生成的文本格式标准、语法地道,但其语言模式和常见短语组合,并未针对知网、维普、万方等中文查重数据库的语义比对逻辑进行专门优化。换言之,机器认为流畅自然的表达,在查重系统的算法看来