EverOS全球公测启动 智能体记忆自进化时代来临

机器之心报道
新一代主动执行型AI智能体(Agent)的崛起,正推动人工智能从“被动响应工具”迈向具备自我演化能力的新纪元。然而,一个根本性瓶颈也随之凸显:受限于有限的上下文窗口和记忆缺失,现有智能体在应对复杂任务时难以有效复用历史经验,持续进化更是无从谈起。
在此关键节点,EverMind团队正式公测了业界首个专为自我演化智能体设计的记忆操作系统:EverOS。这不仅是基础设施的升级,更是对AI开发范式演进的深刻回应。随着AI编程(AI Coding)的兴起,基础设施的核心服务对象正从人类开发者转向AI本身。EverOS为此重构,旨在成为原生适配智能体无缝调用的下一代基座。其背后,是入选ACL 2026的核心算法与首创的“技能”(Skills)进化引擎,这套组合能将复杂任务的成功率最高相对提升234.8%。
这标志着,AI正被注入持续学习的“数字灵魂”,智能体觉醒的序章已经拉开。

记忆:AI进化的下一块关键拼图
过去一年,大语言模型(LLM)的发展轨迹出现清晰拐点:围绕参数规模的竞争逐渐放缓,而关于工程化落地与“记忆机制”的基础设施争夺战,则进入白热化阶段。
从学术界对长上下文的极限探索,到产业界各类记忆框架的涌现,整个行业都在试图攻克一个核心难题:如何让AI突破上下文限制,拥有个性化、一致的行为模式,并最终实现自我进化?
特别是在OpenClaw等现象级项目出现后,各类能交付结果的主动执行型智能体迎来爆发式增长。但热潮之下,痛点依然显著:智能体在多轮对话后容易遗忘历史指令;过高的Token消耗极易触发主流模型的限流机制;它们依然高度依赖开发者手动调优,难以举一反三,自主进化更是遥不可及。
此外,上下文窗口溢出、复杂任务成功率低下,以及记忆无法在不同智能体实例间迁移等老问题,也亟待解决。
EverMind团队长期专注于AI长期记忆与认知架构,其目标是打造具备自我进化能力的主动型个性化AI。通过突破上下文管理的瓶颈,以极低成本和高效率赋予AI智能体真正的个性化与行为一致性。在持续的人机交互与多智能体协作中,让智能体能够跨越单次会话限制,实现真正的自我演进。
此刻,团队带来重磅更新:长期记忆基础设施平台EverOS完成品牌升级并开启全球公测,致力于成为首个专为自我演化型智能体设计的记忆层。
这绝非简单的工具迭代,而是对智能体记忆构建范式的底层重塑。
传统基础设施建立在“人机交互”逻辑之上,需要开发者阅读理解接口文档。然而,当Claude Code等工具引发软件开发范式变革时,“AI编写代码”与“智能体自主调用”正成为基础设施需要服务的新一代“用户”。顺应这一趋势,EverOS完成了从“人类友好”向“智能体友好”的跃迁。它不仅为开发者提供了构建智能体记忆模块的最佳实践,更将自身重构为原生面向AI编程和智能体间无缝调用的下一代基座。
值得一提的是,EverMind团队的两篇核心论文《EverMemOS: A Self-Organizing Memory Operating System for Structured Long-Horizon Reasoning》和《HyperMem: Hypergraph Memory for Long-term Conversations》已双双入选自然语言处理顶级会议ACL 2026主会。结合此前引起广泛关注的《MSA: Memory Sparse Attention for Efficient End-to-End Memory Model Scaling to 100M Tokens》论文,EverMind实现了从学术到工程的全面突破,使其成为智能体开发者最值得关注的记忆解决方案提供者。
接下来,我们将从第一性原理出发,深入拆解一个理想的AI记忆系统需要跨越哪些技术鸿沟,并揭示EverOS如何通过技能自进化等机制,将OpenClaw类智能体的任务成功率相对提升43.1%乃至234.8%。
为何记忆成为AI行业的生死线?
要理解EverOS的价值,首先需回答:为何AI记忆会在当下成为焦点?
答案藏在三股正在汇聚的力量之中:技术天花板、应用场景转移以及对智能终极形态的追求。
1. 深度与跨度:上下文窗口的物理极限与成本黑洞
随着用户使用LLM的深度和时间跨度不断增加,无论是128K还是1M的上下文窗口,最终都会在海量历史对话、长文档和复杂代码库面前捉襟见肘。
更致命的是成本。每一次API调用都需要将数万甚至数十万的Token历史重新输入模型,这种O(N²)复杂度的注意力计算不仅导致响应延迟飙升,更让推理成本变成无底洞。单纯依靠拉长上下文窗口来解决记忆问题,在工程上是一条走不通的死胡同。
2. 执行型智能体的爆发:从“聊天框”到“数字同事”的范式转移
以OpenClaw、Hermes为代表的执行型智能体,正在将AI的定位从“被动回答的百科全书”转变为“主动执行的数字助理”。
当一个智能体需要帮你管理日程、回复邮件,甚至在本地环境中操作文件时,它必须深度理解你的偏好、习惯和过往行为模式。这种个性化AI的需求,要求智能体具备跨越不同任务周期的状态保持能力。
没有长期记忆的智能体,就像一个每天上班都需要重新培训的实习生;而拥有持久记忆的智能体,则是一个越用越默契的资深伙伴。
3. 下一代AI的使命:实现自我演化
今天的大模型,其能力依赖于离线的预训练与后训练——模型一旦出厂,智能便近乎冻结。但生命体的智能从来不是这样生长的:它在每一次交互中微调自身,在反馈中重塑行为,在成长中逐步拉开差距。
我们需要的AI,必须能够在与人类的对话、与其他智能体的协作、与环境的反复试错中,基于反馈持续演进。而这,恰恰是当前智能体赛道最稀缺的壁垒:不是参数规模,也不是工具数量,而是由长期交互沉淀出的数据飞轮。
AI的自我演化时代,已然到来。
第一性原理推演:理想的记忆系统应具备何种特质?
如果抛开现有框架,从零开始思考,一个理想的AI记忆系统需要攻克哪些硬核难题?
难题一:复杂关联的跨时间推理(不仅是“存”,更要能“联想”)
传统的检索增强生成(RAG)方案本质上是一个“高级书签系统”。它将文本切块、计算向量、存入数据库。用户提问时,通过相似度匹配召回最相关的几块文本。
这种方案处理“事实查询”尚可,但面对需要跨越漫长时间线、进行多跳推理的复杂关联时,RAG就会彻底失效。理想的记忆系统必须能够像人类大脑一样,在不同记忆碎片之间建立拓扑连接,实现举一反三的联想。
难题二:从碎片经验到结构化技能的自进化(不仅要能“记”,更要能“学”)
人类学骑自行车,靠的不是记住每一次摔倒的物理参数,而是将无数次尝试的碎片经验,沉淀为一种可自动调用的程序性记忆。
同样,对执行型智能体而言,仅仅堆积每一次API调用的日志远远不够。理想的记忆系统必须具备抽象与泛化能力——能从相似的历史任务中自动提炼出可复用的执行蓝图(Skill),在下一次遇到同类任务时直接调用最佳实践,从而实现真正的“自进化”。
难题三:多模态信息的全量摄入与联合检索(不仅懂“字”,更要懂“世界”)
真实世界的信息从来不是纯文本的。一封包含财务报表的邮件、一份带有架构图的PDF、一张手写的会议白板,这些都是构成完整上下文不可或缺的记忆锚点。
理想的记忆系统必须能够无缝吞吐多模态数据,并且在检索时能够打破模态壁垒,实现文本、图像、结构化与非结构化数据的联合召回。
难题四:对开发者透明的白盒化管理与权限隔离
记忆是极其私密且敏感的数据。一个完全黑盒的记忆引擎对开发者而言是不可接受的。系统必须提供精细的增删改查接口,允许开发者和用户直观地审查、干预和修正智能体的记忆库,同时确保严格的多租户数据隔离。
EverOS的硬核解法:重构智能体记忆底座
面对上述四大技术难题,EverMind团队没有选择在现有RAG框架上打补丁,而是通过底层架构创新,逐一击破。
让我们深入代码与架构的肌理,看看EverOS是如何做到的。
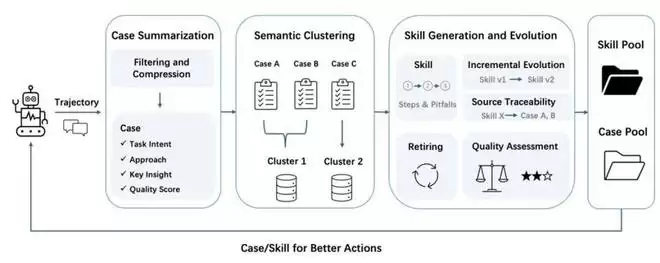
1. Self-Evolving Agent Memory:让OpenClaw任务成功率飙升的秘密
这是EverOS公测版最具突破性的核心更新。它构建了一套从经验到技能的自进化管道,让智能体像人类一样:做得越多,做得越好。
经验自动提取
每次智能体完成任务后,系统会自动从对话中提取结构化经验,包括:任务意图(作为未来检索的关键词)、执行路径(每一步的尝试与决策)、关键洞察(成功的转折点策略)以及质量评分(0.0-1.0的结果评估)。
系统内置智能过滤,自动跳过无价值的简单对话,只提取有迁移价值的问题解决经验。同时,针对超长内容(如工具调用、代码输出)进行启发式压缩,确保提取效率。
语义聚类
提取的经验并非散落存储,而是通过向量语义聚类,自动将相似任务的经验归入同一场景,为后续的技能提炼奠定基础。
技能自动涌现与自进化
系统能够自动从聚类的经验中蒸馏出可复用的技能,这是整个系统最核心的自进化机制。技能并非一成不变,而是随着新经验的加入持续进化——每一次新的任务执行都可能触发技能的迭代升级,使其从粗糙走向精炼,从片面走向完整。
这套机制的精妙之处在于:
- 技能即SOP:技能不是模糊的建议,而是可执行的标准操作流程。
- 增量式进化:每次新经验到来,通过增量操作精准迭代现有技能,而非全量重写。成功经验强化步骤,失败经验补充警示。
- 成熟度评估:采用四维评分体系(完整性、可执行性、证据支撑度、清晰度),只有成熟的技能才会被检索使用。
- 质量感知提取:高质量经验提取执行步骤,低质量经验提取失败教训——无论成败,智能体都在学习。
- 信心退役机制:置信度持续下降的技能会自动退役,避免过时技能误导决策。
- 来源可追溯:每个技能都保留源经验ID,支持审计回溯。
由此,在智能体使用过程中形成了一个完美的进化闭环:“对话 → 经验提取 → 语义聚类 → 技能涌现 → 检索应用 → 更好的对话”。从零推理,到经验复用,再到技能驱动——智能体的能力随使用自然生长,成为一套完整的认知进化引擎。
2. mRAG混合检索架构:跨越模态壁垒
针对多模态信息处理难题,EverOS推出了一套专门设计的mRAG(多模态检索增强生成)检索策略。
在数据摄入端,EverOS API新增了对全类型多模态数据的原生解析与存储支持。无论是复杂的PDF、Word、Excel文档,还是各类图像文件,甚至是网页URL,开发者都可以通过统一的API端点直接推送。
在检索端,EverOS抛弃了简单的稠密向量匹配,引入了名为“hybrid”的混合检索策略。这套策略在底层融合了:语义向量检索(捕捉深层意图)、稀疏关键词检索(确保特定术语的精确召回)以及多模态对齐表征(实现“以文搜图”或跨模态的上下文还原)。
这种架构确保了当用户询问“上次会议白板上画的那个架构图里的数据库方案”时,智能体能够精准地从海量多模态记忆中捞出关键图片,并结合当时的会议纪要文本给出准确回答。
3. HyperMem架构支撑:ACL顶会关注的超图记忆网络
解决跨时间关联和多跳推理的底气,来自于入选ACL 2026的论文《HyperMem: Hypergraph Memory for Long-term Conversations》。
EverOS在底层摒弃了扁平的向量数据库结构,转而采用创新的超图数据结构来组织记忆节点。在超图中,一条边可以同时连接多个节点,这完美契合了真实世界中复杂的多元实体关系。
通过在超图上进行信息传递和动态路由,EverOS能够在极低延迟下,顺藤摸瓜地找出一系列看似独立但逻辑高度关联的记忆碎片。这种模型级的算法创新,构成了难以复制的技术护城河。
4. 平滑的开发者体验:内测迁移与可视化Playground
在工程落地层面,EverOS展现出了极高的成熟度。为了降低接入成本,它提供了极其克制的RESTful API,并为内测老用户设计了平滑的数据迁移路径。
更令人惊喜的是,EverOS Cloud Platform新增了直观的Playground模块:
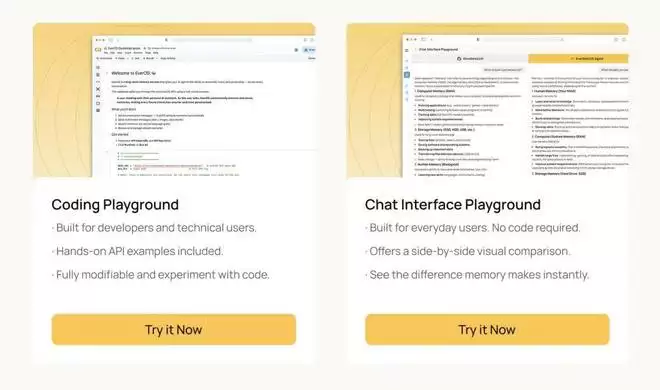
- Coding Playground:直接打通Google Colab,开发者点击运行代码片段,即可在浏览器中沉浸式体验添加记忆、mRAG检索、多模态解析等核心API的流转过程。
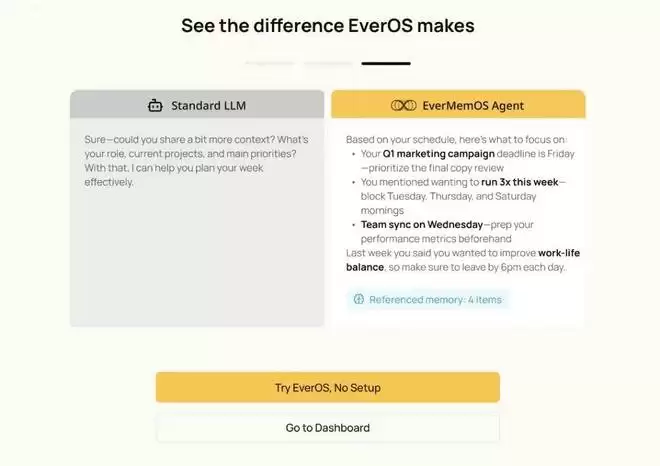
- Chat Playground:一个直观的对比视窗,左侧是未接入记忆的LLM,右侧是接入EverOS记忆库的LLM。开发者可以直观感受到,基于收集的个人信息,EverOS是如何让回答变得极具个性化和温度的。
在商业化路径上,EverOS采用了灵活的信用点计费模型,将不同维度的资源消耗统一折算,让成本核算清晰透明。公测阶段,每个账户均赠送免费额度,足以覆盖完整的试用体验。
EvoAgentBench:量化智能体的自进化能力
一个常见的问题是:既然OpenClaw等智能体已有记忆系统,为何还需要EverOS?
答案在于,当前主动型智能体虽代表未来,但远未成熟——上下文利用效率低、关键信息易丢失、任务成功率偏低等问题普遍存在。为了客观衡量不同框架的真实效果,EverMind团队搭建了一套名为EvoAgentBench的测评框架,用于评估主动型智能体完成任务的能力。
EvoAgentBench从三个维度展开测试:信息检索、推理与问题分解,以及软件工程问题解决。
通过这套测试,可以横向比较在不同OpenClaw框架下,采用与不采用EverOS技能自进化策略时,智能体在任务成功率与运行轮数上的差异。
团队基于QWEN3.5 397B和27B模型,测试了OpenClaw的任务执行成功率。通过比较首次执行和经过相似任务集训练后的进化效果,得出了令人振奋的结论:
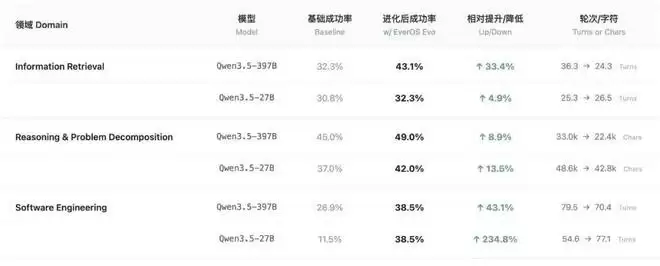
从测评数据中可以得到四个核心洞察:
1. 工程实战能力进化最为显著
在软件工程问题解决能力测试中,基于27B模型的智能体成功率从11.5%跃升至38.5%,相对提升达234.8%;397B模型同样实现了43.1%的相对提升。软件工程任务天然依赖多步执行与经验积累,这正是技能自进化机制最能发挥杠杆效应的场景。
2. 记忆是比参数量更高效的能力杠杆
在软件工程维度,27B模型的基础成功率不到397B模型的一半。然而经过EverOS技能进化后,27B直接追平了397B模型接入EverOS后的表现。这意味着在特定场景下,为小模型配备高质量的记忆进化能力,其性价比远高于单纯堆叠参数量。
3. 进化不仅提升成功率,还在压缩执行路径
在信息检索测试中,397B模型的任务分解轮次显著降低;在推理与问题分解测试中,输出字符数大幅压缩。智能体在积累技能后,不再需要反复试错和冗余推理,而是更精准地命中解题路径——这直接意味着更低的Token消耗和更快的响应速度。
4. 技能自进化机制具备跨任务类型的普适性
在信息检索、推理与问题分解、软件工程三个维度上,EverOS对397B模型均实现了正向提升。这表明技能自进化并非仅对特定任务有效的“巧合”,而是一套可泛化的认知增强机制。
团队目前仍在持续完善针对不同基准测试、模型和智能体的测评,并发布了完整的EvoAgentBench测评框架。它不是一个静态的快照,而是一套可以持续衡量智能体进化效果的动态框架。
AGI终局:从“瑞士军刀”到“数字灵魂”
当我们跳出代码和API的微观视角,重新审视EverOS所做的一切,会发现这不仅是一次技术架构的升级,更是一次关于“AI究竟应该是什么”的哲学探讨。
17世纪哲学家约翰・洛克在探讨“人格同一性”时曾提出一个著名观点:正是意识(特别是记忆)的连续性,构成了“我”之所以为“我”的核心。如果没有记忆,昨天的我和今天的我就没有任何关联。
当前的许多大模型,本质上是一把无比锋利、功能齐全的“瑞士军刀”。它什么都能做,但它永远是一把冰冷的工具。你每次使用它,它都不记得上次为你做过什么。
而赋予AI以持续一致、个性化、可进化的记忆,就是在为这把瑞士军刀注入“数字灵魂”。
当OpenClaw智能体能够通过EverOS的技能引擎,记住你写代码时的特定习惯;当它能够通过mRAG准确调出你们数月前共同探讨过的那张架构草图;当它在一次次试错中积累经验,最终形成专属于你的执行蓝图时……它就不再是一个随时可以被替换的API端点,而是一个与你共同经历、拥有默契、真正懂你的数字伙伴。
回顾EverMind的技术演进历程,始终沿着通往AGI终局的方向推演:从构建长期记忆基准测试,到突破百万级上下文,构建端到端持续进化架构,再到面向智能体的多模态和技能自进化能力……当通用人工智能来临,我们指挥智能体军团为我们工作、生活提供各种服务的时候,或许正是EverOS这样的记忆中枢,在为我们提供持续、一致、安全的数字灵魂栖息地。
加入共建:全球征集场景案例与插件贡献
记忆基础设施的边界,永远是由身处一线的开发者共同定义的。
随着相关竞赛的成功举办,EverMind感受到了开发者的参与热情和创新潜力。在EverOS公测期间,团队继续开放“全球开发者社区共建计划”。最硬核的技术,只有在最真实的场景中,才能爆发出最耀眼的火花。
团队诚挚邀请全球开发者、研究人员和极客们加入,在以下两个维度进行深度共建:
- 场景案例:利用EverOS API,在法律文书分析、医疗病历追踪、个性化教育辅导、个人数字助理等垂直领域,构建具备长期记忆的创新应用。
- 插件贡献:为OpenClaw等执行型智能体开发基于EverOS记忆底座的创新插件,拓展智能体的执行边界。
为了致敬开源精神与社区力量,EverMind将在每个季度评选出优秀贡献者。获奖者将获得丰厚的商业版信用额度奖励,并享有核心研发团队的专属技术支持通道,其优秀项目更将在全球技术社区获得重点展示与推广。
从短暂的上下文,到永恒的数字记忆。在这个AI进化的分水岭上,每个开发者都可以参与其中。
相关攻略

美西时间4月28日,硅谷成为全球具身智能技术发展的焦点舞台,一场定义行业未来的顶级峰会——全球具身智能创新大会(GEIS)在此隆重举行。 本次大会规格空前,不仅汇聚了Openmind、PrismaX AI等硅谷前沿AI公司的深度参与,更吸引了包括图灵奖得主Martin Hellman、英伟达GEAR

一、将上下文信息密度最大化 长程智能体(Long-horizon Agent)的性能,说到底,一直被上下文窗口所束缚。我们常看到两个典型困境:一是“上下文爆炸”,工具描述、记忆检索、原始环境反馈等信息在多步交互中不断堆叠,最终把真正关键的决策信息挤出了模型的注意力范围;二是“经验清零”,每次任务完成

【导读】智谱CEO张鹏认为,大模型未来12个月面临的最大问题可能是算力中国基金报记者 卢鸰3月27日上午,在中关村论坛一场主题为“OpenClaw与AI开源”的圆桌对话上,中国AI大模型领域的顶级“

“干活消耗的Token量是简单问答的10倍甚至100倍,成本大幅提高。”回答月之暗面CEO杨植麟“为什么涨价”的问题时,智谱CEO张鹏这样说道。上文这组问答,发生在今天举行的2026中关村论坛年会开

文 | 字母AI“干活消耗的Token量是简单问答的10倍甚至100倍,成本大幅提高。”回答月之暗面CEO杨植麟“为什么涨价”的问题时,智谱CEO张鹏这样说道。上文这组问答,发生在今天举行的2026
热门专题







热门推荐

近日,国家能源局联合发改委、工信部、国家数据局正式印发《关于促进人工智能与能源双向赋能的行动方案》。这份重磅文件的核心思路非常清晰:一方面,以坚实的能源基础支撑人工智能(AI)的快速发展;另一方面,利用AI技术赋能能源行业转型升级。其核心目标是推动能源、算力、应用场景、数据与算法模型五大关键要素深度

在挑选文生视频工具时,若您正在智谱清影与Runway Gen-3之间权衡,那么了解两者在生成效果上的具体差异,将有助于您做出更明智的选择。本文将从画质清晰度、细节纹理、运动自然度与视频连贯性等核心维度,通过实测对比为您详细解析。 一、画质与分辨率表现 首先对比硬性指标。智谱清影基于CogVideoX

想用通义万相生成一张科技感十足的数据可视化背景,但出来的画面总觉得少了点“内味儿”?数字界面、粒子流、电路纹理这些关键元素一个不见,画面平平无奇?这通常不是工具的问题,而是提示词没有精准锚定科技可视化的核心要素,或者模型参数没调到最佳状态。别急,下面这几种方法,能帮你把想法精准地“翻译”成画面。 一

想要在Vidu生成的视频中实现流畅的慢动作或快进效果?虽然模型界面没有提供直接调整播放速度的滑块,但通过巧妙的提示词设计、利用内置功能,或结合后期处理工具,你完全可以精准掌控视频的节奏与时间感。本文将为你详细解析四种实用方法,从生成前到生成后,全方位满足你的创作需求。 一、通过精准提示词引导运动节奏

当您使用海螺AI生成的英文论文在提交查重时遭遇高重复率或AIGC检测异常,请不要急于归咎于工具本身。核心原因在于,尽管AI生成的文本格式标准、语法地道,但其语言模式和常见短语组合,并未针对知网、维普、万方等中文查重数据库的语义比对逻辑进行专门优化。换言之,机器认为流畅自然的表达,在查重系统的算法看来