智能体并行推理大脑如何告别单线程思维实现进化
这篇发表于ICML 2026主会的论文,核心作者来自北京通用人工智能研究院(通研院)语言交互实验室。近年来,大语言模型在生成流畅的长文本方面进步显著。然而,当面对真正复杂的推理场景——需要多路探索、自我反思、交叉验证,并在多条线索间进行权衡与汇总时,传统的链式思维(Chain-of-Thought)方法就显得有些力不从心了。它容易受早期判断误导,发散性不足,自我纠错能力弱,并且顺序生成的效率本身也存在瓶颈。
通研院语言交互实验室的最新工作——原生并行推理器(Native Parallel Reasoner, NPR),正是瞄准了这一痛点。其核心目标是让智能体在一次思考过程中,能够同时衍生并维护多条候选推理路径,在关键节点进行“分支”与“聚合”,最终像拼图一样整合线索,得出最优解。
更重要的是,NPR的突破不仅在于“并行生成”的工程技巧,更在于提出了一套“自蒸馏+并行强化学习”的三阶段训练范式,并配备了专门的并行推理引擎。其最终目的,是让并行推理从一种外部策略,转变为模型内生的、原生的认知能力。

论文标题:Native Parallel Reasoner: Reasoning in Parallelism via Self-Distilled Reinforcement Learning 论文链接:https://arxiv.org/abs/2512.07461 代码实现:https://github.com/bigai-nlco/Native-Parallel-Reasoner 项目主页:https://bigai-nlco.github.io/Native-Parallel-Reasoner
当前,语言智能体的研究焦点已从“扩展单一思维链”转向了“深化多步推理”。模型能够进行更深层次的思考固然令人兴奋,但未来的超级智能,需要的是更广泛地并行探索多种可能性——即在同一推理过程中尝试多种解法,再进行合并与校验。这种类似MapReduce的分而治之思路,对于扩展智能体在推理时的计算边界至关重要。然而,将其原生地整合进模型中,却面临着不小的挑战。
背景与痛点:为什么我们迫切需要并行推理?
人们对智能体的期待,正从“能多想一步”的单一思维链,升级到“能多维思考”的深度推理。未来更强的智能体,必须具备广泛探索多条思考路径的能力——这很像经典的MapReduce思想:把复杂问题拆开并行处理,再聚合结果以完成全局最优决策。
但要让模型真正学会这种“分身术”,现实里往往卡在三座大山:
1. 算法与架构不匹配
现有的推理引擎和强化学习算法很难原生支持“分支+聚合”操作。推理引擎通常无法高效调度并行分支;而常用的RL技术可能会截断或削弱那些触发并行结构的特殊词元的梯度,从而阻碍模型学习严格的并行控制逻辑。
2. 低效的手工并行机制
早期将并行思路内化的尝试,多依赖于手工设计的分治规则。这种方法无法充分复用共享的KV Cache状态,导致每个分支重复计算,时间复杂度退化到线性O(N),难以满足实时或大规模部署的效率要求。
3. 对强监督蒸馏的依赖
像Multiverse这类方法虽然能实现并行,但高度依赖强教师模型蒸馏出的示例,无法通过自举的方式扩展自身的智能边界。学生模型更多是在模仿教师的串行拓扑并将其“塞入”并行格式,结果是把教师的局限也一并继承,短时间内难以涌现出模型自身固有的新并行策略,形成了当前的“智能瓶颈”。
NPR的核心理念:把“并行性”升维成模型的原生能力
NPR的关键在于“原生”二字。研究团队试图在零外部监督(不依赖强教师并行轨迹)的条件下,探索一条让模型自我进化出并行推理能力的路径。
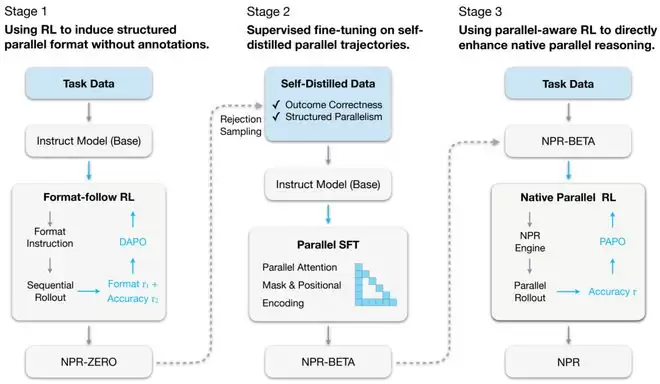
整体思路是一个渐进式的三阶段训练范式,让模型从“会用并行格式写出来”,逐步过渡到“在计算图层面真正并行执行”。
三阶段训练范式:从“并行外形”到“并行大脑”
阶段一:并行格式学习——先学会“怎么写成并行”
第一步并不追求“真正并行”,而是让模型先掌握并行推理的表达结构:如何标记分支、如何组织多条候选路径、如何定义聚合点。
阶段二:自蒸馏——内化“并行思考逻辑”,摆脱外部老师
在具备并行表达能力后,NPR采用自蒸馏方式,让模型用自己的生成结果反过来训练自己。通过筛选与沉淀,模型逐步内化“多分支探索—相互印证—汇总收敛”的推理规律,而不是照搬教师的串行偏好与局限。
阶段三:并行感知强化学习——从“模仿并行”迈向“执行并行”
最后一步是关键跃迁:利用并行感知的强化学习,让模型学会何时该分叉、分叉多少、如何在聚合点进行比较与合并。这使得并行不再停留在文本表面,而是真正成为推理过程中可执行的控制逻辑。这一步将“并行性”从工程技巧,推进到模型的原生能力层面。
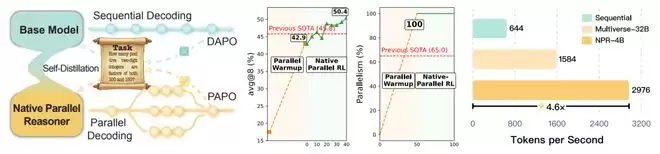
如下图所示,经过三个阶段的训练,NPR的准确率从约17%持续爬升,最终达到50.4%(中间两条学习曲线分别对应第一阶段的格式学习与第三阶段的并行强化学习);与传统推理方式相比,NPR实现了约4.6倍的生成加速(右侧柱状图)。
NPR具体实现细节
NPR训练范式
Stage 1:Format-following Reinforcement Learning(NPR-ZERO)
目标:在无任何外部并行示例或教师的情况下,让模型学会生成结构化的并行格式(如特定标签),并尽量保证答案正确性。
方法:以格式合规与答案正确为奖励信号,对初始指令微调模型进行DAPO风格的强化学习,从而得到能产出并行格式轨迹的生成器(NPR-ZERO)。这一步为后续自蒸馏提供原始候选轨迹。
Stage 2:Rejection Sampling + Parallel Warmup(NPR-BETA)
目标:把Stage 1的“格式化产物”变为高质量的训练数据,并让模型在并行语义上稳定下来。
方法:对NPR-ZERO进行拒绝采样,并应用严格的筛选器(必须同时满足“格式合规”与“答案正确”),保留高质量的并行推理轨迹用于自蒸馏。然后在此基础上进行冷启动的并行SFT预热微调,同时引入并行注意力掩码与并行位置编码,让模型内部能够支持并行分支的独立计算,并实现KV Cache重用以避免重复计算。
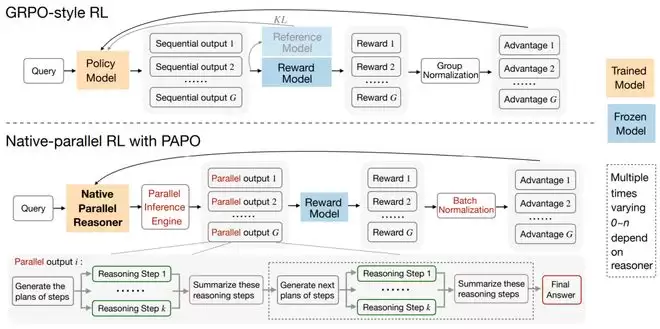
Stage 3:Native-Parallel RL(PAPO)
目标:在并行执行引擎上,用强化学习直接优化并行分支策略,使其不仅会“写”并行格式,也会“算”并行结果。
方法:提出并实现Parallel-Aware Policy Optimization (PAPO)——一种对并行语义做专门修改的策略优化方法。它使用并行Rollout的NPR-Engine推理引擎以保证结构正确性、在批次层级进行优势归一化、保留特殊结构化Token的梯度并放弃重要性采样以维持稳定的On-Policy梯度更新。PAPO能直接在并行计算图内优化分支策略,从不断的试错中学会有效的问题拆解与合并策略。
关键技术细节
1. 自蒸馏与严格筛选(Rejection Sampling)
从NPR-ZERO生成大量并行格式的候选轨迹后,采用两条硬性筛选规则只保留高质量样本:一是模型生成的候选轨迹的解析答案与标准答案一致;二是输出严格遵循并行格式的Schema。当且仅当同时满足以上两条规则的采样轨迹被接受,用于冷启动并行SFT。此策略显著减少了噪声,保证了训练语料的并行性与可学习性。
2. 并行注意力掩码与并行位置编码
为了在单次前向传递中同时存在多条推理路径,NPR采用了Multiverse风格的并行注意力掩码与专门设计的并行位置编码。这保证了不同分支互相隔离但共享上下文KV Cache,从而实现KV Cache重用并避免每条分支重复计算上下文代价。该编码也允许通过标签Token标明分支、步骤或指南块,便于引擎解析。
3. Parallel-Aware Policy Optimization(PAPO)
在并行语义下直接套用经典PPO或DAPO会遇到特殊Token被剪裁、重要性采样不稳定等问题。PAPO的主要设计包括:使用NPR-Engine产生严格遵守并行Schema的轨迹;在优化前剔除格式违规样本;采用批次级优势归一化来稳定优势估计;在Token级别保留特殊标签的梯度流;同时放弃重要性采样,采用严格的On-policy目标函数,避免重采样比带来的不稳定。
AI Infra工程化改进:NPR-Engine
实验证明,将并行语义放到生产环境的并行RL中,会暴露出大量工程问题,例如KV Cache重复释放导致的内存泄漏、并行Token计数导致的超长生成、非法并行schema导致的未定义状态等。论文在引擎层面做了几项关键修复:引入预算感知的确定性KV回收机制与Memory Flush策略,避免内存问题;将全局Token预算从“只看最长分支”改为“按活跃分支因子累计”,避免超出生成限制;在分支展开前增加格式合法性检查,快速拒绝潜在非法分支以保证确定性。这些工程改进是确保能稳定进行并行RL训练,进而获得并行思考智能体的前提。
主要实验与结论
评测基准与度量
研究在8个推理型基准上进行了评测,包括AIME24/25、HMMT25、OlympiadBench、Minerva-Math、ZebraLogic、AMC23、MATH500等。对小规模竞赛类数据使用采样8条解答的平均正确率,对大规模或单答设置使用单次采样的正确率。
训练数据优势
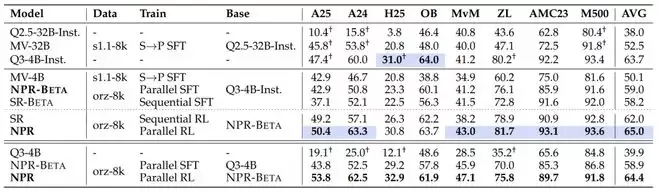
性能提升的关键在于用自行提炼的数据集(NPR-BETA的ORZ-8k)替换了Multiverse的训练语料库(MV-4B的s1.1-8k)。尽管两个流程在实现细节上略有不同,但都依赖于并行式的SFT,因此比较结果具有意义。数据替换的影响清晰且一致:AIME24的性能从46.7提升至50.8(+4.1),ZebraLogic从60.2提升至76.1(+15.9),AMC23从75.0提升至85.9(+10.9),MATH500从81.6提升至91.6(+10.0)。总体而言,平均得分从50.1提升至59.0(+8.9)。
并行SFT的优势
从顺序SFT切换到并行SFT方法能够显著提升各种推理基准测试的性能。顺序SFT引入了较强的步骤依赖性先验,限制了任务分解的灵活性。相比之下,并行SFT在训练过程中使模型能够接触到结构上并行的轨迹,从而实现更独立的子问题探索。具体而言,AIME25从37.1提升至42.9 (+5.8),OlympiadBench从56.3提升至60.1 (+3.8),HMMT25从22.5提升至23.3 (+0.8),ZebraLogic从72.8提升至76.1 (+3.3)。整体性能从58.2提升至59.0 (+0.8),仅在少数基准测试中间出现轻微退步。
并行强化学习优势
基于NPR-BETA,应用并行强化学习算法可获得进一步的性能提升,并始终优于顺序强化学习。这些改进是广泛而系统的:AIME24从57.1提升至63.3(+6.2),HMMT25从26.3提升至30.8(+4.5),Minerva-Math从38.2提升至43.0(+4.8)。其他基准测试也显示出稳步提升。总体而言,平均得分从62.0提升至65.0(+3.0)。
Multiverse-32B在不同数据集上的并行率差异显著,表明其并行推理的采用高度依赖于数据集。尤其是在ZebraLogic等逻辑密集型任务上,其性能明显低于多个数学竞赛数据集。这表明从顺序行为逐步过渡到并行行为的Multiverse训练范式,导致并行策略的内化不一致,并且对领域特征非常敏感。
相比之下,NPR模型在所有八个数据集上均达到了100.0%的并行触发率。这种一致性意味着端到端的NPR训练流程能够更可靠地将并行推理作为模型的默认问题解决模式,而不受数据集领域或复杂性的影响。实际上,这意味着NPR不仅能更频繁地触发并行推理,而且能够在不同的评估数据集上稳健地实现这一点。

NPR在所有五个基准测试中均取得了最佳效率,始终优于Multiverse(1.3倍至2.4倍)和自回归基线,这表明该方法具有稳健的泛化能力。重要的是,加速比随任务难度而增加:NPR在较难的问题(如AIME25:4.6倍;HMMT25:4.1倍)上观察到的加速比,大于在较容易的问题(如AMC23:2.9倍)上的加速比。这表明当需要更深入地探索解路径时,NPR的优势日益凸显,证明了NPR既能提高准确率,而且在可以并行探索多种解策略时尤其有效。

案例解析
论文给出了若干具体题目的并行解法示例,典型模式为:首先并行产生若干独立的解题计划;接着,每个计划独立并行展开具体推理步骤;最后,整合与交叉验证各分支结果,得出最终结论并给出简短答案。
举例来说,对于函数域或几何题,某些计划会分别从不同的角度进行分解(如代数、数值检验、几何角度关系),最后通过“多角度并行+汇总”能显著减少因单一路径假设错误导致的推理开销。通过将各分支结果进行比对、剔除不一致项,最终输出答案。


结语
NPR的工作展示了一条不依赖强教师监督、让模型自主进化出并行推理能力的可行路径。通过三阶段的训练范式——从学习并行表达格式,到通过自蒸馏内化并行逻辑,再到通过并行感知强化学习将其固化为可执行的原生能力——NPR成功地将并行推理从一种外部策略转变为模型的内生认知。这不仅在多个推理基准上取得了显著的性能与效率提升,更重要的是,它为实现更高效、更鲁棒、更接近人类“多线程”思考方式的下一代智能体,提供了重要的方法论和工程实践基础。
相关攻略

由大语言模型驱动的多智能体系统,正从实验室原型快速演进为支撑复杂任务的关键基础设施。在软件工程、科学探索、流程自动化及团队协作等多个领域,由智能体团队协同完成任务已成为现实。当前,一个显著的趋势是:智能体生态的供给与真实系统的部署规模,正在同步经历爆发式增长。 智能体市场的品类与数量日益丰富,而实际

许多人可能并未意识到,自己早已身处多智能体协作技术带来的变革之中。 电商大促期间,仓库中并非仅有一台机器人在运作,而是由一整队机器人协同完成分拣、运输、避障与货物交接。自动驾驶技术面临的真正挑战,也不仅仅是教会一辆车如何行驶,更是要让众多车辆在同一条道路上实现高效、安全的协同。现实世界中的复杂任务,

手握最强大的模型Mythos,Anthropic却选择将其锁入保险柜。 原因在于,这个模型能自主发现软件漏洞,效率之高、数量之多,连其创造者都感到不安,最终只开放给少数机构进行测试。 此事在安全圈内引发了轩然大波。许多人开始第一次严肃地思考:当AI能够规模化地挖掘漏洞时,数字世界的安全格局将发生怎样

Markdown以简洁语法降低输出成本与认知负担,其统一规则便于生成稳定结构,并具备跨平台适配性,在多种场景中无缝渲染。该格式聚焦内容、弱化机械感,成为平衡成本、功能与兼容性的高效选择。

对于金融分析师、市场研究员和生命科学专家而言,繁杂枯燥的资料搜集与交叉比对,向来是消耗核心精力的效率黑洞。好消息是,这一局面正被谷歌最新升级的自动化研究工具所改写。此次升级的核心突破,在于其能够将公开网络信息与企业内部的私密数据库无缝整合,直接生成带有原生数据可视化图表、且完全标注信息来源的专业级分
热门专题







热门推荐

东南亚智能手机市场第一季度平均售价同比上涨19%,达349美元。出货量虽下滑9%,但市场总规模增长8%,呈现“量减价增”态势。这表明消费者开始转向高端机型,市场增长动力正从销量扩张向价值提升转变。

代币归属期指代币在发行后按预定时间表逐步解锁的过程。该机制旨在激励项目长期发展,防止早期投资者或团队成员大量抛售导致市场波动。归属期通常包含锁定期与释放期,具体规则由项目方设定。理解此概念有助于评估代币的潜在流通量与市场风险。

近日,小鹏汽车正式宣布,基于其旗舰SUV车型GX打造的首款Robotaxi(自动驾驶出租车)量产车已成功下线。这一重要进展标志着中国L4级高阶自动驾驶技术的商业化落地,迈出了坚实而关键的一步。 根据官方披露的核心信息,这款自动驾驶车型创造了多项行业纪录:它不仅是中国首款实现全栈自研、前装量产的Rob

5月19日,一则新闻引发广泛关注与讨论:河南濮阳一位主营冷冻榴莲果肉的商家,因遭遇买家恶意发起“仅退款”操作,在沟通无果后,选择驱车数百公里前往山东进行维权。几乎在同一时间,浙江杭州萧山区盈丰街道,也因类似恶意退货退款问题频发,被部分电商商家列入“交易谨慎名单”。这两起典型事件,将长期存在于电商交易

5月19日,AMD完成了一项具有里程碑意义的战略举措:首次将其年度AI开发者大会的主会场设在中国。在上海,AMD董事会主席兼首席执行官苏姿丰博士发表了核心主题演讲,其中所传递的战略信号,其深远意义远超单纯的技术发布。 贯穿整场演讲,一个核心信息被不断强化:中国市场对于AMD的全球战略重要性,已提升至