伯克利研究揭示持续学习优势 OpenAI面临新挑战

AI工程师Dan McAteer最近有个大胆的预言:2026年,持续学习(continual learning)将迎来爆发。这个判断的底气,来自伯克利等机构刚刚发布的一项突破性研究。
他们提出的FST框架,通过一种“快慢分层”的机制,让大模型在连续学习多个任务时,既能快速适应新知识,又能牢牢记住旧本领,从而有望解决困扰AI领域长达三十年的“灾难性遗忘”死局。有观点认为,这一突破的意义,可能远超当前火热的推理能力变革。
当“推理天才”遭遇“学习失忆”
过去两年,整个AI圈的叙事几乎被“推理”一词垄断。从OpenAI的o系列到DeepSeek的R1,再到Claude的思考模式,头部实验室的产品形态各异,但内核高度一致:提升模型的深度推理能力,被视为通往更高级智能的必经之路。
这个共识如此之强,以至于在今天,如果一个项目不能讲清楚自己在“推理”上的布局,恐怕连投资人的第一轮门槛都迈不过去。
然而,我们似乎忘了追问一个根本问题:什么是真正的智能?
不妨打个比方:一个学生,能在高考考场上对任何一道题目进行无懈可击的深度推理,逻辑链条完美。但前提是,他的知识库永远停留在16岁初中毕业的那一刻,此后再未更新。你会将这种能力称为“智能”吗?
这并非修辞,而是当前最先进大语言模型的真实写照。无论是GPT-5、Claude还是Gemini,它们在每次对话开始时,都像一个“昨日毕业、今日醒来”的天才——可以在单次会话中越挖越深,但只要对话框关闭,记忆便瞬间清空,回归到出厂设置般的状态。
它们就像数字世界的西西弗斯,不断将“推理”的巨石推向山顶,但每一次起点都是山脚,永无积累。

一堵三十年未被推倒的墙
为什么模型无法从与你的对话中学习?为什么昨天教它的东西,今天它就忘得一干二净?
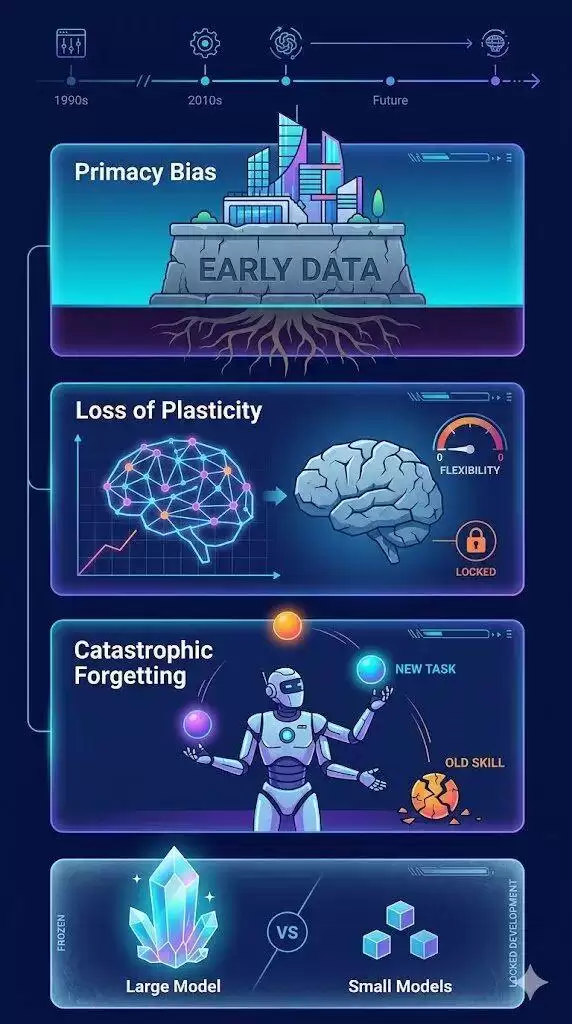
这背后是AI领域一个长达三十年的经典难题:持续学习。其目标是让模型像人类一样,能够“温故而知新”,在不断吸收新知识的同时,不遗忘旧技能。然而,这条路上横亘着三个顽固的“老对手”:
- 首因偏差:模型早期学到的数据会顽固地主导其后续的学习策略,形成难以扭转的思维定式。
- 损失函数弹性:模型每学会一个新任务,其神经网络的“可塑性”就降低一分,最终会彻底丧失学习新事物的能力。
- 灾难性遗忘:这是最著名的问题。当模型学习新任务时,旧任务的能力会突然崩塌。让它学数学,它可能就忘了怎么写代码。
这些问题在小模型时代就已存在。进入大模型时代,它们并未消失,只是被一种“鸵鸟策略”暂时掩盖了:我们干脆放弃了让模型在部署后持续学习,只在训练阶段一次性灌注海量知识,之后便将其“冻结”。
因此,我们今天使用的所有大模型,本质上都是“冻结的天才”——强大,但活在永恒的当下;聪明,却无法变得更聪明。

破局思路:向大脑学习“快慢分工”
最近,由Databricks、伯克利和经典机器学习学派研究者组成的豪华团队,在这堵墙上撬开了一道缝隙。这项研究阵容堪称梦幻,包括Databricks联合创始人兼Apache Spark作者Matei Zaharia、伯克利教授及vLLM作者之一Joseph Gonzalez,以及机器学习元老级人物Inderjit Dhillon等。

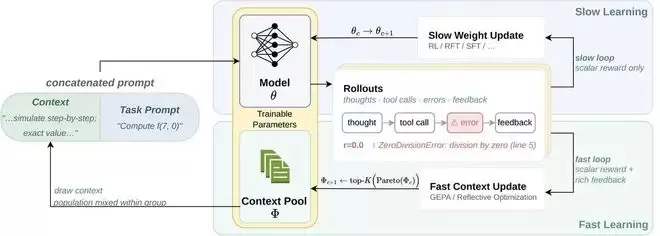
他们提出的FST框架,核心思想朴素而深刻:不要让同一组参数去承担两个相互冲突的职能。
在传统的强化学习训练中,模型的同一组参数既要负责“快速适应当前任务的特殊性”,又要承担“保留通用推理能力”的职责。前者要求参数灵活变化,后者则要求其保持稳定,这本身就是一对矛盾。
FST的解决方案是进行“快慢分工”。它将模型参数分为两套权重:
- 慢权重:负责沉淀通用的、长期稳定的知识与推理能力,更新频率很低。
- 快权重:负责快速记忆和适应眼前的新任务、新上下文,更新非常灵活。
两者交替更新:每隔一段时间用强化学习微调慢权重,同时利用一个名为GEPA的提示词优化器自动演化快权重。
这并非凭空想象,其灵感直接来源于人类大脑的“互补学习系统”理论。我们的大脑正是这样工作的:海马体作为“快权重”,能在几分钟内记住会议上的某句发言;而新皮层作为“慢权重”,则用数月甚至数年的时间,将海马体中那些真正有价值的信息,缓慢而稳固地整合进长期记忆结构。

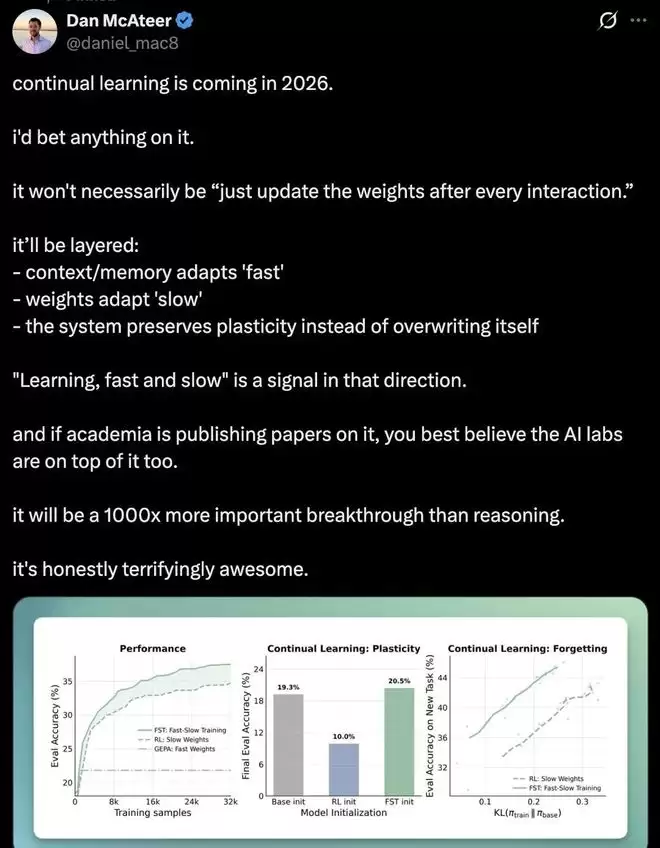
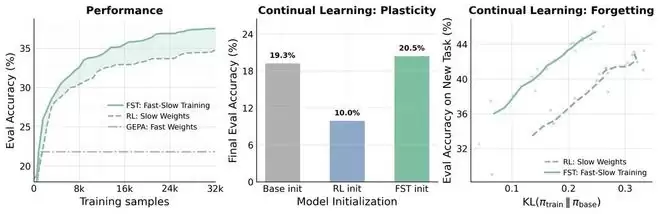
FST首次在大模型中实现了这种类脑的分层学习结构。实验结果也相当亮眼:
- 在代码推理任务上,FST仅用传统方法三分之一的训练步数就达到了同等性能。
- 在匹配准确率的前提下,FST训练出的模型,其知识分布与基础模型的差异比传统方法低70%,意味着“遗忘”大幅减少。
- 最关键的可塑性测试显示,在连续学习多个任务后,传统方法训练的模型几乎完全丧失了学习新任务的能力,而FST模型则几乎能恢复到初始水平,继续高效学习。
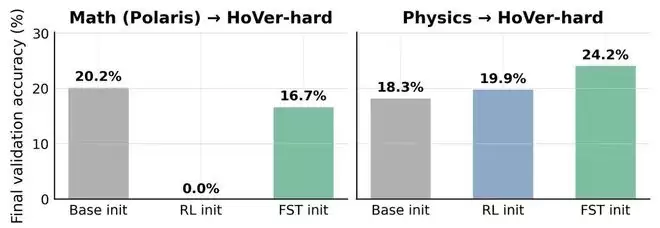
当然,FST远非一个完美的终极算法。其工程实现仍处于早期,其中的GEPA优化器等组件也完全可以被其他技术替代。
但这项工作的真正价值,不在于提供了一个“银弹”,而在于它确立了一种全新的“范式语言”——“快慢分工”。它第一次让持续学习从一个令人望而生畏的理论难题,变成了一个可被工程化探索和解决的方向。
下一轮博弈,已然开局
关于持续学习的未来,业界的共识正在形成,但远未统一。
OpenAI前首席科学家Ilya Sutskever认为,超级智能应被重新定义为一个“持续学习器”,而非一个训练完毕的静态AGI。他预估,实现这一目标可能需要5到20年。这个时间表虽然保守,但也暗示了他认为问题终将被解决。
而像Karpathy这样的研究者,则更关注实现路径。他认同持续学习是“真问题”,但怀疑现有技术路径是否足够。
无论如何,风向已经开始转变。如果说以深度推理为核心的竞争是2024年开局、预计2026年收尾,那么以持续学习为标志的新时代,其发令枪已经在2026年响起。技术演进的浪潮从不等人,下一轮关乎AI本质能力的博弈,不会等到2027年才拉开帷幕。
标题:Learning, Fast and Slow: Towards LLMs That Adapt Continually
预印本:https://arxiv.org/abs/2605.12484
项目主页:https://gepa-ai.github.io/gepa/blog/2026/05/11/learning-fast-and-slow/
相关攻略

龙虾之父Peter Steinberger,在社交平台X上晒出了一张自己的CodexBar后台截图。 一张相当离谱的截图—— 上面透露出的信息和数字,足以让任何一个关注AI成本的人心头一震: 过去30天,他调用的OpenAI API总费用达到了1,305,088美元,约合软妹币940万元; 同时消耗

一场围绕人工智能伦理与使命的法律大战,迎来了关键性裁决。北京时间5月19日,据路透社报道,美国加州奥克兰联邦法院陪审团就埃隆·马斯克起诉OpenAI一案作出判决,裁定马斯克败诉。 陪审团经过不到两小时的审议后一致认定,OpenAI无需为马斯克所提出的“背离造福人类创始使命”的指控承担法律责任。裁决的

苹果与OpenAI合作因商业回报未达预期出现裂痕。腾讯地图推出AI骑手模式优化配送。百度成立模型委员会强化AI布局。荣耀将发布搭载云台系统的RobotPhone。Anthropic拟以9000亿美元估值融资。阿里发布智能体开发工作台Qoder1 0。千问APP接入药监局数据。发那科与英伟达深化合作,利用AI加速机器人开发。

4月22日,路透社发布了一则引人关注的消息:佛罗里达州总检察长詹姆斯·乌特迈尔于当地时间周二(4月21日)宣布,该州将对OpenAI及其人工智能应用ChatGPT展开刑事调查。事件的起因,与去年发生在佛罗里达州立大学的一起致命枪击案有关。 回顾案情,去年4月,一名枪手在佛罗里达州立大学开枪,导致两人

4月21日,OpenAI对其图像生成能力进行了一次重要升级,正式推出了ChatGPT Images 2 0模型。这次更新并非独立发布,而是通过现有的ChatGPT及Codex平台直接向用户推送。从官方释放的信息来看,新模型在理解用户指令的精准度和生成图像的细节丰富度上,都有了肉眼可见的进步。 更值得
热门专题







热门推荐

在流量日益分散的今天,把鸡蛋放在同一个篮子里,风险不言而喻。多平台推广,早已不是“要不要做”的选择题,而是“如何做好”的生存题。它的核心价值,可以概括为两点:实现“流量风险对冲”,以及构建“品牌触点全覆盖”。通过在不同生态位——无论是搜索、短视频、图文还是电商——建立内容矩阵,企业不仅能有效缓冲单一

DeepSeek知识库的核心,是运用RAG(检索增强生成)技术,将DeepSeek强大的大语言模型推理能力,与您的私有文档资源——包括PDF文件、内部代码库、标准操作流程(SOP)等——深度融合。其最终目标是实现基于特定垂直领域数据的精准智能问答,让AI的回答不再是通用泛化,而是具备专业依据、内容详

三大运营商推出Token套餐,将大模型调用量包装为类似流量包的产品,以降低AI使用门槛。中国电信推出个人与企业多档套餐,最低月费9 9元;上海移动推出1元购40万Tokens服务;联通则提供个人与团队版套餐。运营商凭借用户渠道和支付优势,推动算力消费向大众市场普及,可能重塑AI服务消费模式。

HermesAgent本地运行缓慢常因未量化的大语言模型占用资源过多。可通过AWQ量化模型、llama cpp后端加载GGUF模型、配置vLLM引擎提升并发吞吐、禁用非必要工具降低上下文开销,以及调整SQLite记忆检索阈值等方案优化。这些方法能显著降低延迟,提升响应速度。

随着AI智能体能力的持续增强,确保其行为始终符合预设目标与安全边界,已成为行业亟待解决的核心挑战。然而,当前主流的治理方案在防止智能体“失控”或“脱轨”方面,仍面临显著的实践瓶颈。 在之前的探讨中,我们分析了主流治理思路:部署多样化的对抗性验证器,构建一个多层次的安全审查网络。该方案的核心逻辑并非限