中国科学院瞬悉2.0类脑大模型发布 突破长序列与低耗部署瓶颈

人工智能领域的长文本处理竞赛正进入白热化阶段。无论是深度解析代码仓库、构建智能体的长期记忆,还是处理复杂的多模态交互,都迫切需要模型能够高效处理数十万乃至上百万token的超长序列。
然而,一个根本性的技术瓶颈也随之凸显:基于传统Transformer架构的模型,其推理时的计算复杂度和显存消耗会随着序列长度呈平方级增长。这严重制约了大型语言模型在真实世界场景,特别是边缘计算和资源受限环境中的实际部署与应用。
如何破解这一效率与能耗的困局?近期,中国科学院自动化研究所李国齐、徐波团队带来了突破性解决方案——类脑脉冲大模型「瞬悉2.0」(SpikingBrain2.0-5B)。这项研究在前代「瞬悉1.0」的基础上,针对超长上下文理解与低功耗部署两大核心挑战,实现了从底层架构到上层应用的系统性革新。

研究背景:从规模驱动到效率驱动
当前,大模型的发展范式正在经历深刻变革。早期的“参数规模竞赛”逐渐转向对“上下文窗口能力”的极致追求。模型能够有效理解和记忆多长的信息,直接决定了其解决复杂推理、长文档分析等任务的实际能力上限。
但理想与现实之间存在巨大鸿沟。传统Transformer的自注意力机制在处理超长序列时,会产生难以承受的计算与存储开销。因此,整个产业界与学术界共同面临一个关键命题:能否以极低的计算成本,构建一个既能驾驭超长上下文,又能在多样硬件平台上高效、节能运行的基础模型?
「瞬悉1.0」率先将类脑脉冲神经网络机制引入大模型,迈出了第一步。而「瞬悉2.0」则实现了全面跃升,通过引入更精细的类脑稀疏记忆建模与双路径激活编码策略,旨在完成一次在性能、效率与通用性上的全方位突破。
架构设计:精准优化Transformer效率瓶颈
要设计高效的类脑大模型,必须精准识别传统架构的效能瓶颈。在短序列任务中,Transformer的计算负载主要集中于前馈网络;而在长序列场景下,注意力模块则成为主要的性能与能耗瓶颈。「瞬悉2.0」的架构创新,正是对这两大核心问题的针对性优化。
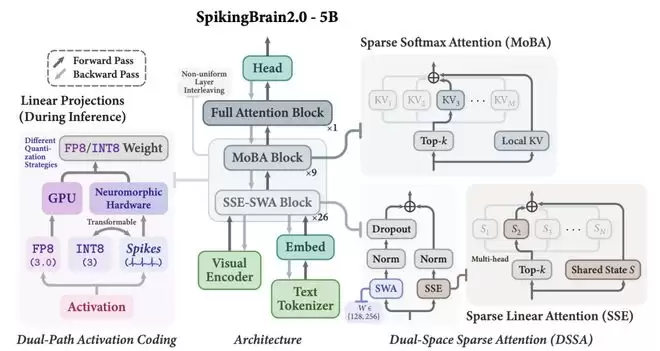
瞬悉2.0架构概览
双空间混合稀疏注意力
模型创新性地提出了“双空间稀疏注意力”(DSSA)机制。其核心思想并非在所有网络层使用统一的注意力模式,而是在不同层级间智能地混合两种稀疏注意力策略:一种是基于完整键值缓存的块级稀疏计算(MoBA),另一种则是对压缩后状态表征进行稀疏计算(SSE)。
这种设计灵感源于生物大脑的稀疏记忆与信息处理特性,其根本目标是在确保长序列建模性能的前提下,最大化计算效率,实现卓越的“性能-能效”平衡,为长文本大模型提供高效解决方案。
双路径激活值编码策略
注意力机制决定了计算方式,而激活值编码则决定了计算的数据形态。「瞬悉2.0」首创了双路径并行编码方案,以完美适配不同的硬件生态:
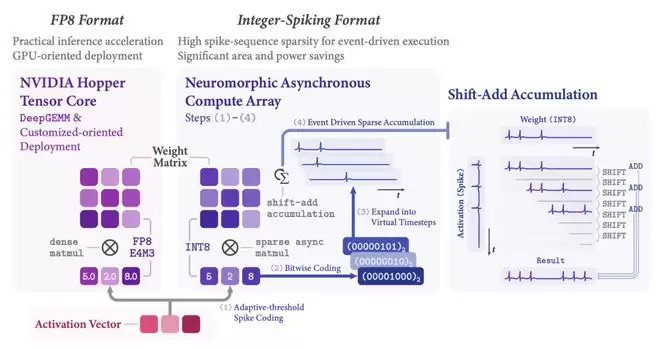
瞬悉2.0对偶编码路径
- FP8低精度编码路径:面向主流高性能GPU(如NVIDIA H100)。利用新一代硬件的低比特张量核心加速矩阵运算,是追求极致推理吞吐量的理想选择。
- INT8-Spiking脉冲事件编码路径:面向未来神经形态计算芯片。将密集的浮点激活转换为稀疏的脉冲事件流,从而将耗能的矩阵乘法替换为高效的事件驱动整数累加。此路径旨在革命性降低功耗,为AI在端侧、物联网等边缘设备的部署扫清障碍。
转换训练:低成本实现高性能模型迁移
从头训练一个全新架构的大模型成本极高。「瞬悉2.0」研发了一套高效的“Transformer-to-Hybrid”转换训练流程,仅需极少的开源数据和计算资源,即可将成熟的Transformer模型(如Qwen3系列)高性能地迁移为类脑脉冲混合模型。
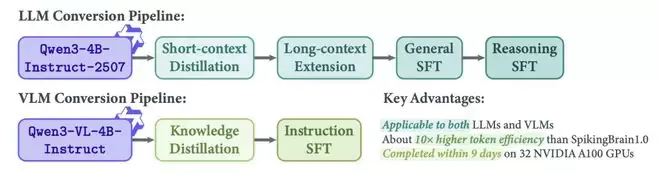
瞬悉2.0转换训练Pipeline
该流程为语言模型和多模态模型设计了独立且高效的迁移路径。对于语言模型,通过短上下文知识蒸馏、渐进式长上下文能力扩展以及指令跟随微调等阶段,稳步提升模型各项能力。对于视觉语言模型,则融合了视觉-语言知识蒸馏与多模态指令调优技术。整个流程高效、可复现,为社区提供了宝贵的低功耗大模型训练实践经验。
性能表现:用数据验证突破
经过精心设计的「瞬悉2.0」,其实际效能究竟如何?多项基准测试给出了有力证明。
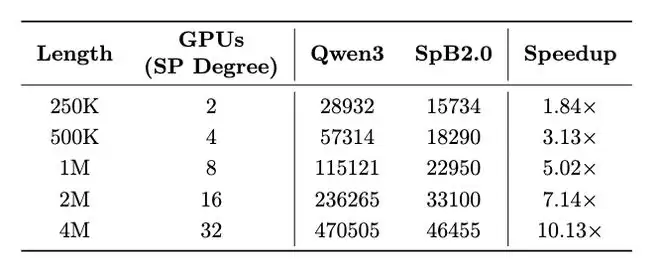
1. 长序列处理效率实现数量级提升
在超长文本处理能力上,其优势极为显著。在处理长达400万token的序列时,其首Token生成延迟相比强大的基线模型Qwen3加速超过10倍。更令人印象深刻的是,借助vLLM推理框架,仅需8张A100 GPU即可支持高达1000万token序列的推理,而基线模型在400万长度时便已因显存溢出而无法运行。
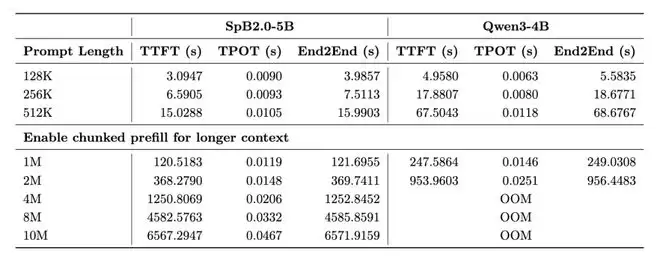
2. 模型训练成本大幅降低
高效不仅体现在推理,也贯穿于训练阶段。整个「瞬悉2.0」语言与多模态模型的转换训练,总计算开销被严格控制在7000 A100 GPU小时以内。具体而言,仅使用32张A100显卡,在9天内即可完成对Qwen3-4B及Qwen3-VL-4B模型的完整能力迁移。相比前代「瞬悉1.0」,训练所需数据量从1500亿Token大幅减少至140亿,训练成本降低了一个数量级。
3. 核心模型能力得到充分保持
在实现极高效率的同时,模型的核心能力是否受损?评测数据显示,其性能得到了完整保留。在MMLU、ARC-C等通用知识基准,以及GSM8K数学推理、HumanEval代码生成等专项任务上,「瞬悉2.0」的语言模型性能与原始Qwen3基线持平,并全面超越了前代模型。其多模态版本「瞬悉2.0-VL」也成功复现了Qwen3-VL的强大能力,在图表理解、视觉推理等任务上表现优异。
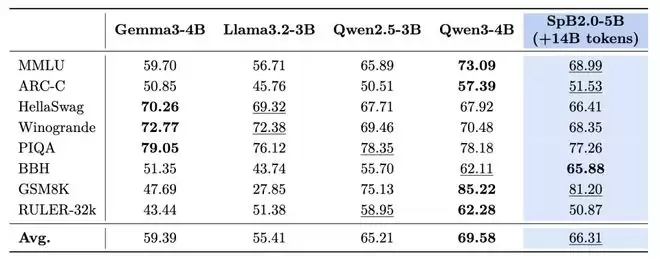
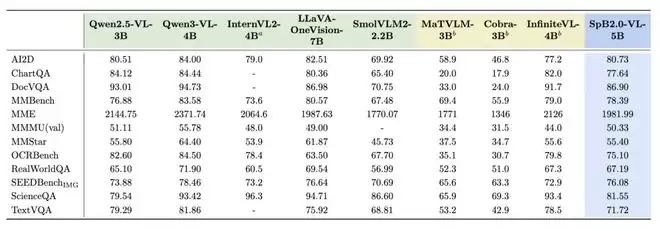
4. 卓越的跨平台部署适配能力
这正是「瞬悉2.0」最引人瞩目的特性之一,它真正实现了“一次训练,多端部署”。
- 在FP8编码路径下,模型精度损失极小(仅0.24%),但在NVIDIA H100 GPU上实测,长序列推理速度相比其自身BF16版本提升超过2.5倍,充分释放了硬件潜力。
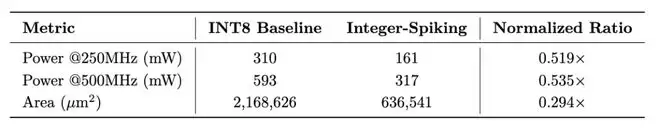
- 在INT8-Spiking脉冲编码路径下,精度损失也控制在0.69%以内,同时激活稀疏度高达64.3%。后端仿真结果表明:与传统的INT8量化方案相比,该路径有望在专用神经形态硬件上实现芯片面积减少70.6%,功耗降低约46%-48%。这为彻底解决大模型在移动端、嵌入式设备上的功耗瓶颈,指明了一条极具前景的技术路径。
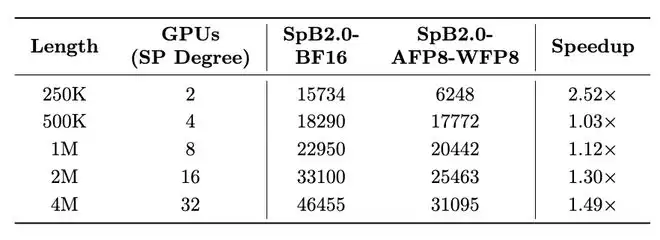
结语
「瞬悉2.0」的发布,不仅标志着一个高性能类脑脉冲模型的诞生,更清晰地描绘出一条通往高效人工智能的未来路径。它证明,通过深度借鉴生物大脑的稀疏性、事件驱动等高效计算原理,我们完全有能力构建出在保持强大性能的同时,兼具超长上下文处理能力和极致能效比的新一代基础模型。
这项研究为轻量化、多模态高效大模型的研发提供了坚实的技术验证,也为人工智能在边缘计算、物联网等资源严格受限场景的规模化落地,开启了新的可能性。这或许预示着,大模型的发展浪潮,正从单纯追求“参数更大”,转向更加注重“架构更巧”与“能效更绿”的新纪元。
相关攻略

人工智能领域的长文本处理竞赛正进入白热化阶段。无论是深度解析代码仓库、构建智能体的长期记忆,还是处理复杂的多模态交互,都迫切需要模型能够高效处理数十万乃至上百万token的超长序列。 然而,一个根本性的技术瓶颈也随之凸显:基于传统Transformer架构的模型,其推理时的计算复杂度和显存消耗会随着

这项研究由中国科学院大学、中国科学院自动化研究所新型模式识别实验室、多模态人工智能系统国家重点实验室、香港科创研究院以及香港理工大学联合开展,论文于2026年4月发表,论文编号为arXiv:2604 24441v1。 一、这件事为什么值得普通人关注 你有没有试过把一项繁琐的电脑操作交给AI来完成?比

我国科学家在人工细胞研究领域取得重大突破。中国科学院化学研究所乔燕、王树团队联合国际科研力量,首次实现了人工细胞在形态和功能上的不对称分裂,相关成果于5月13日发表于《自然》期刊。这项研究填补了化学、材料与合成生物学交叉领域的技术空白,为未来设计功能化人造细胞系统及生物技术应用提供了全新的思路与模型

百万级国产豪华汽车市场再迎重磅车主,行业影响力持续攀升。 近日,中国科学院院士、深圳国际量子研究院院长俞大鹏正式成为比亚迪旗下高端品牌仰望U8的车主。在隆重的交付仪式上,比亚迪集团总裁王传福亲自将车钥匙递交到俞院士手中,彰显了品牌对顶尖科技人才的崇高礼遇。仰望汽车总经理胡晓庆现场表示,诚挚感谢俞院士

如果你曾让AI助手处理过一份几万字的合同,或者要求它读完一份百页报告后回答问题,那你一定经历过那种等待——在AI吐出第一个字之前,那段似乎格外漫长的沉默。这种等待,在技术术语里被称为“首字延迟”(Time-To-First-Token, TTFT),它直接取决于AI需要消化多少输入内容。输入越长,等
热门专题







热门推荐

如果你发现阿里系AI应用近期密集上线、品牌标识迅速统一、生态能力集中释放,这并非偶然——背后是一场精心布局的战略升级。阿里正在全面重构其AI时代的流量入口体系,具体正沿着以下几条关键路径加速推进。 一、品牌体系收束:从多头并进到千问单极 过去,阿里在AI产品线上采取分散布局:夸克侧重智能搜索,灵光聚

2023年初,一家欧洲奢侈品牌的中国区数字化负责人,收到了一份令人尴尬的年度审计报告。在“业务流程自动化覆盖率”这项关键指标上,中国区在全球各分公司的排名中,位列倒数第三。总部力推的UiPath平台,在中国团队的实际使用率竟不足30%。报告一针见血地指出,问题并非出在态度上,而是源于“工具与土壤的错

在Excel数据分析与报表制作中,跨工作表提取整行信息是一项常见且关键的操作。无论是进行多表数据整合、制作动态查询看板,还是完成日常数据核对,掌握高效的跨表提取技巧都能显著提升工作效率。本文将系统介绍六种实用方法,涵盖从基础函数到自动化工具的多种场景,帮助您根据数据结构和任务复杂度灵活选择最佳方案。

在小红书运营和内容创作中,分析爆款笔记、借鉴优质同行文案是提升账号表现的关键。然而,手动逐个点开笔记查看不仅耗时耗力,效率也难以保证。市面上虽然存在不少数据采集工具,但许多都需要付费订阅。实际上,也有免费且功能强大的替代方案,例如“实在Agent”平台推出的小红书采集智能体。它集成了热门笔记采集分析

在探讨实在智能RPA财务机器人的市场价格时,许多企业会发现其报价并非固定数值,而是呈现出从数千元到数十万元不等的宽幅区间。这种价格差异的背后,实际上是品牌实力、功能配置、性能水平、服务支持以及企业具体需求等多重因素共同作用的结果。 要清晰理解实在智能RPA财务机器人的定价逻辑,我们可以从以下几个核心