在数据价值日益凸显的今天,如何在利用数据训练智能模型的同时,牢牢守住隐私安全的底线,成了横亘在许多行业面前的一道难题。传统的集中式训练需要汇聚各方数据,隐私泄露风险如影随形;而各自为政的孤立训练,又难以获得高质量的全局模型。有没有一种两全其美的方案?联邦学习(Federated Learning, FL)的提出,正是为了回应这一挑战。
简单来说,联邦学习是一种创新的分布式机器学习框架。它的核心魅力在于,能够在多个参与方不共享原始数据的前提下,协同训练出一个强大的共享模型。这就像一群厨师共同研发一道新菜谱,但各自秘方绝不外泄,只交流烹饪的心得与火候的调整,最终却能合力做出一道绝世佳肴。那么,它是如何做到既保护隐私又完成训练的呢?
一、联邦学习的主要特点
首先,隐私保护是其立身之本。各参与方只在本地用自己的数据训练模型,之后仅将模型参数的更新(比如梯度信息)上传给中央服务器进行聚合。原始数据始终留在本地,从源头上切断了数据泄露的路径。
其次,安全性通过技术手段得到了加固。整个过程中,模型参数的交互通常都会借助安全多方计算、同态加密等技术进行加密处理,确保即便传输链路被窥探,敏感信息也不会暴露。
再者,它追求高效且无损的模型效果。联邦学习旨在整合分散的计算资源和数据价值,其最终训练出的全局模型,在性能上往往不逊于甚至优于在中心化数据上训练的模型,避免了“数据孤岛”带来的模型局限性。
最后,它的架构设计非常灵活。针对数据样本重叠但特征不同,或特征重叠但样本不同的场景,衍生出了横向联邦学习、纵向联邦学习以及联邦迁移学习等不同的技术分支,以适应多样化的业务需求。
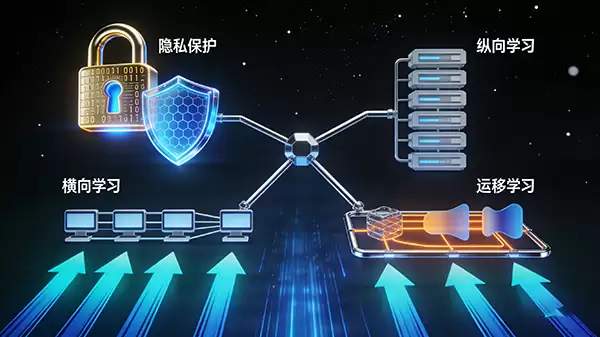
二、联邦学习在保护隐私的同时实现模型训练的方式
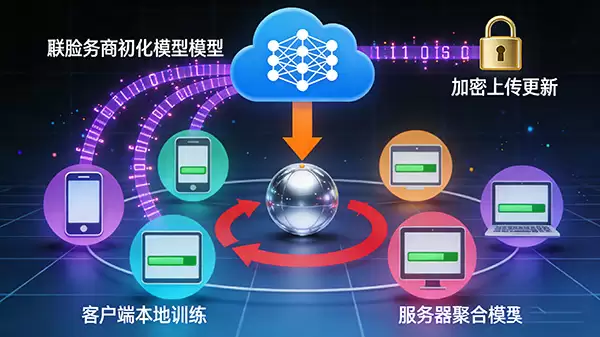
联邦学习的训练过程可以看作一个有序的协作循环,具体包含以下几个关键步骤:
1. 初始化模型:整个过程由中央服务器发起,它首先初始化一个全局模型,并将这个模型的初始参数分发给所有参与训练的客户端。
2. 本地训练:每个客户端在收到全局模型参数后,就在自己的本地数据集上独立进行训练。这里的关键是,训练完全基于客户端自身的私有数据,原始数据无需离开本地设备。
3. 上传更新:本地训练完成后,客户端会将计算得到的模型更新(例如梯度或权重变化)进行加密,然后发送回中央服务器。这些更新蕴含了本地数据分布的特征信息,但本身并非原始数据。
4. 聚合模型:中央服务器收集到所有客户端的加密更新后,会执行聚合操作,比如采用经典的“联邦平均”算法,将各方的更新融合起来,生成一个更新版的全局模型。
5. 重复迭代:这个“分发-本地训练-上传-聚合”的循环会不断重复,直到模型性能收敛或达到预设的训练轮数。每一轮迭代,客户端都在最新的全局模型基础上继续优化,推动模型持续进化。
三、联邦学习中的隐私保护技术
基础的联邦学习框架已经提供了相当程度的隐私保障,但为了应对更复杂的隐私威胁模型,研究人员引入了更多前沿的密码学和隐私计算技术,为数据安全上了“多重保险”。
差分隐私:这项技术通过在数据或模型更新中添加精心设计的随机噪声,来模糊单个数据点的贡献。在联邦学习中,对客户端上传的梯度添加差分隐私噪声,可以确保在聚合结果中无法推断出任何特定参与者的敏感信息,从而提供严格的数学隐私保证。
同态加密:它允许直接对加密状态下的数据进行计算,而无需解密。在联邦场景下,客户端可以用同态加密技术加密其模型更新后再上传。服务器能够在不解密的情况下,直接对这些加密的更新进行聚合操作,从根本上防止了传输和聚合过程中的数据泄露。
安全多方计算:MPC使得多个参与方能够共同执行一个计算函数,而各方的输入数据始终保持保密。在联邦学习的模型聚合阶段,可以利用MPC协议,让多个服务器或客户端协同完成聚合计算,确保没有任何一方能够单独窥见其他方的原始更新信息,有效防止合谋攻击。

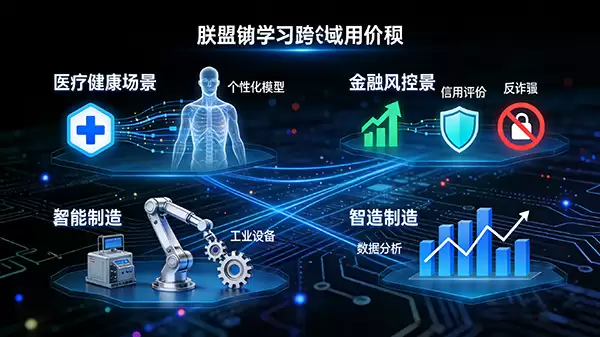
四、应用场景
凭借其独特的优势,联邦学习正在多个对数据隐私极为敏感的领域开花结果。
在医疗健康领域,不同医院可以利用联邦学习协作训练疾病诊断或新药研发模型,既能利用多中心的医疗数据提升模型精度,又完全避免了患者隐私数据的跨机构流转,为个性化医疗提供了可能。
在金融风控领域,多家银&行可以联合构建反欺诈或信用评估模型。每家银&行都贡献自己客户的行为特征,但无需共享具体的交易明细和客户身份信息,从而在合规的前提下大幅提升了风险识别的准确性和覆盖范围。
此外,在智能制造、智慧城市、移动终端用户体验优化等领域,联邦学习也展现出巨大的潜力,使得“数据可用不可见”的协作模式成为现实。
总结
总而言之,联邦学习通过巧妙的分布式架构和强大的隐私保护技术,在数据隐私与价值利用之间找到了一个宝贵的平衡点。它使得跨组织、跨设备的大规模协同智能训练成为可能,而无需以牺牲数据安全为代价。随着数据法规日趋严格和人工智能应用不断深化,联邦学习无疑将成为推动下一代可信AI发展的关键基石,在更广阔的舞台上发挥其不可替代的作用。




