GPT-5.5参数规模真相:10T传闻不实,实际仅1.5T
五一假期前夕,AI领域被一则重磅消息引爆:一篇最新论文声称,通过一种创新的“黑盒探测方法”,成功推算出GPT-5.5可能拥有接近10万亿参数的惊人规模。这一数字迅速在技术社区引发热议,因为它比外界普遍推测的GPT-4参数量高出数倍。然而,热度尚未消退,剧情便迎来了反转。

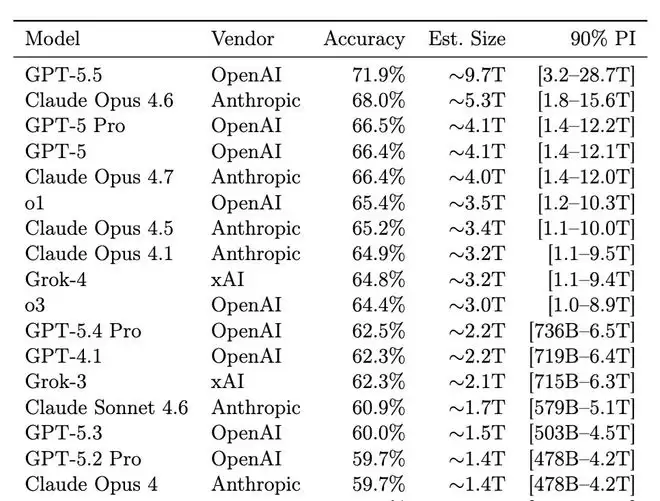
这篇题为《不可压缩知识探针》的论文,由Pine AI首席科学家李博杰发布在预印本平台arXiv上。其公布的估算结果极具冲击力:
- GPT-5.5:9.7万亿参数
- Claude Opus 4.7:4.0万亿参数
- o1:3.5万亿参数

很快,来自加州大学伯克利分校CHAI实验室的Lawrence Chan与英国AISI的研究员Ben Sturgeon对这项研究进行了深入审查。他们发现,论文中存在一些关键的方法论与代码实现偏差。
逻辑的漏洞:从10万亿到1.5万亿的估算缩水内幕
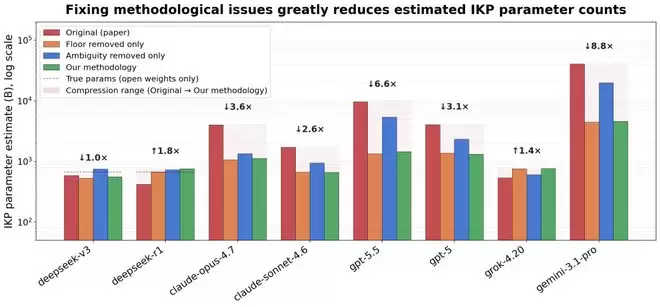
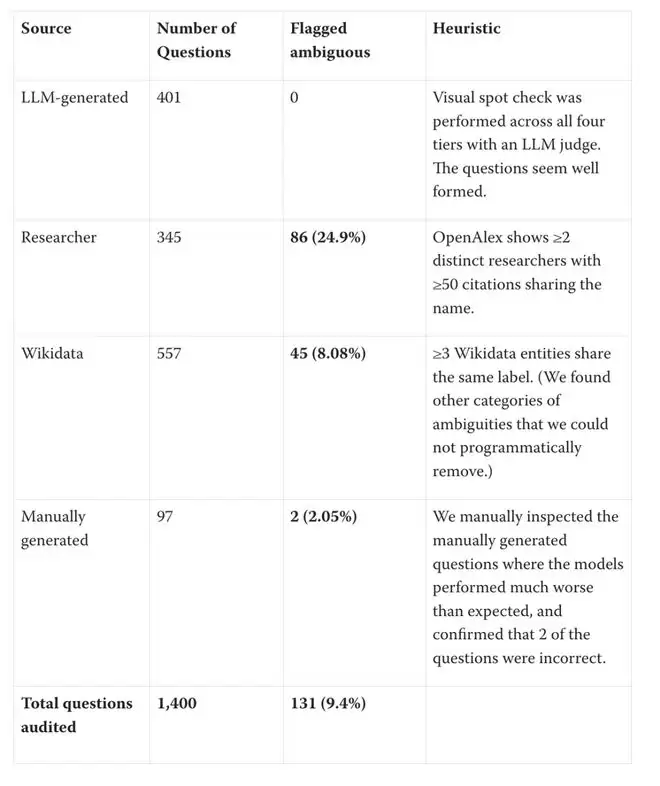
在修正了这些问题后,结论发生了戏剧性变化。最受瞩目的GPT-5.5,其参数估算值从9.7万亿急剧下降至约1.5万亿,并且90%置信区间变得异常宽泛(从2560亿到8.3万亿)。
问题究竟出在哪里?主要集中在以下两个核心环节。
被修饰的拟合曲线
论文作者声称未对模型得分进行“保底处理”,但复现者发现,在计算小型模型得分时,负分被悄然归零了。这一点至关重要:当模型面对完全未知的冷僻知识时,若进行随机猜测,得分很可能为负。移除这一“归零”操作后,小模型的得分显著降低,导致原本陡峭的“得分-参数”拟合曲线趋于平缓,最终使得对大语言模型的参数估算严重高估。

“人工智障”出题:25%的题目本身存在错误
另一个硬伤在于测试数据集的质量。研究者指出,用于探测模型知识容量的那套“冷知识题库”本身质量堪忧。大约四分之一的题目存在歧义(例如研究员姓名重复问题),甚至部分标准答案本身就是错误的。使用这样的数据集来衡量大型语言模型的“知识储备”,其可靠性与准确性自然大打折扣。
更具戏剧性的是,论文作者李博杰后来坦言,这项研究是在AI智能体的辅助下,仅用4天时间完成的早期探索。这种开发模式被Lawrence Chan戏称为“充满槽点的Vibe-coding”。

核心理论依然坚挺
尽管具体数值遭遇“打假”,但这项研究提出的核心思想——不可压缩知识探针理论——依然获得了学术界的认可。这或许是整个事件中最有价值的收获。

简而言之,IKP理论认为,大语言模型的能力可以拆解为两个部分:
- 程序性能力(如逻辑推理、代码生成):这部分是“可压缩”的。通过模型架构和训练算法的优化,参数量更小的模型完全可能具备更强的推理能力。
- 事实性知识(如历史日期、冷门概念):这部分是“不可压缩”的。你可以将模型视为一个存储设备,记忆一个事实就需要占用一定的“存储空间”。知道就是知道,不知道就是不知道,很难通过压缩或纯粹推理获得。
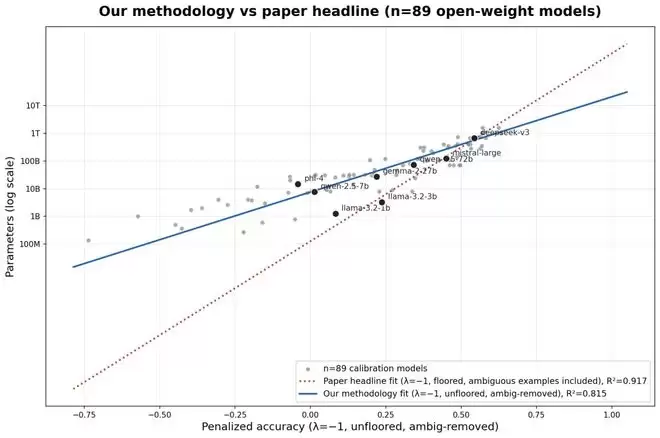
因此,通过测试模型掌握了多少这类“不可压缩”的冷知识,来反推其参数规模,这个方法论的方向本身是成立的。修正偏差后,基于IKP的估算虽然数值变化巨大,但不同模型之间的相对“知识容量”排名依然具有参考意义。
修正后的估算结果显示:
- GPT-5.5:从9.7万亿降至约1.5万亿
- Claude Opus 4.7:从4.0万亿降至约1.1万亿
- DeepSeek R1(实际大小6710亿):从4240亿修正至约7600亿

谁才是真正的“知识之王”?
抛开具体的数字争议,这次探测依然揭示了一些关于大模型能力的深刻洞见。
梯队格局: GPT-5.5在超冷门知识(T6级别)的测试表现上依然遥遥领先,稳居第一梯队。Claude Opus 4.7、o1、Grok-4等模型则构成了竞争激烈的第二梯队,其有效知识容量非常接近。
MoE模型的秘密: 研究证实,对于混合专家模型而言,其知识总量取决于模型的总参数量,而非每次推理时激活的参数量。这意味着,若要构建一个知识渊博的AI模型,增加参数总量仍然是无法绕开的硬性条件。
“思考模式”的玄学: 测试还表明,开启“思维链”模式并不能显著增加模型的知识储备。这再次印证了一个直观的道理:深度思考能帮助模型更好地组织和运用已知信息,但无法凭空生成它从未学习过的知识。
Lawrence Chan在总结中略带调侃地指出,这项工作的粗糙风格,确实符合“AI智能体四天速成”项目的典型特征。
Scaling Law失效了吗?
这场“参数神话”的破灭,与其说是一次失败,不如说是一次有益的行业纠偏。它提醒我们:盲目崇拜参数规模的时代正在成为过去。
GPT-5.5的估算参数从10万亿“缩水”到1.5万亿,绝不意味着它能力变弱。恰恰相反,这可能暗示着OpenAI在训练数据质量、模型训练效率和神经网络架构优化上取得了更惊人的突破,能够以更少的参数实现更强大的综合性能。
正如研究者所言,GPT-5.5的确切参数规模我们依然无法确定。但IKP这种方法,为我们窥探那些如同“黑箱”的巨型语言模型的内部结构,开辟了一条新的、颇具潜力的技术路径。它启示我们,在通往通用人工智能的道路上,我们追求的或许不再是单纯的“更大的存储硬盘”,而是“更高效、更智能的数据索引与处理范式”。
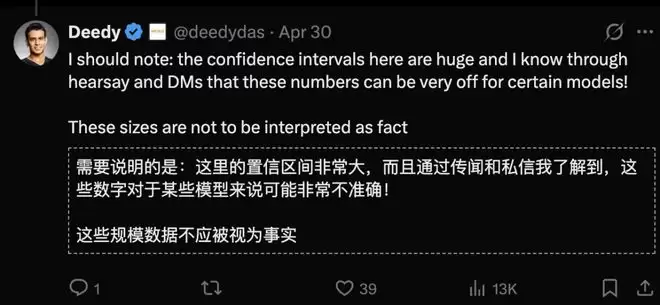
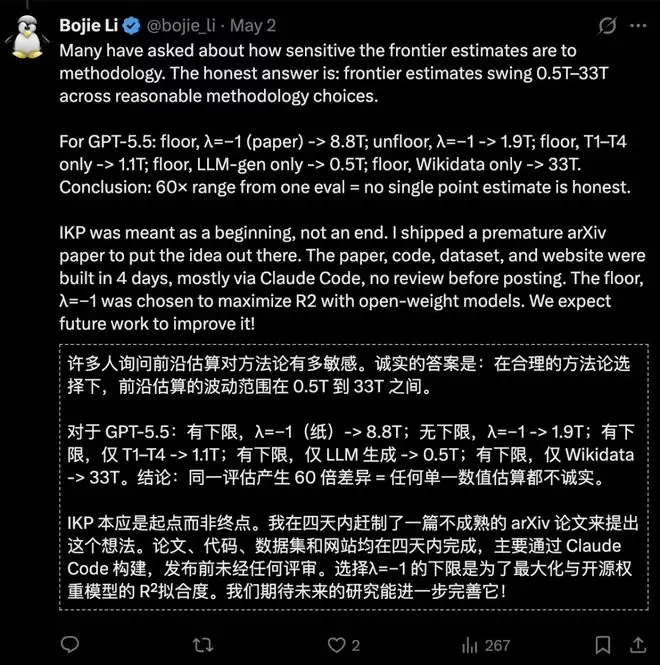
原论文作者李博杰也对此保持了开放态度,他承认早期估算存在很大不确定性,并直言“任何单一的点估计都不够诚实”。他将IKP视为一个有价值的研究起点,而非终点,期待后续工作能将其进一步完善。


相关攻略

五一假期前夕,AI领域被一则重磅消息引爆:一篇最新论文声称,通过一种创新的“黑盒探测方法”,成功推算出GPT-5 5可能拥有接近10万亿参数的惊人规模。这一数字迅速在技术社区引发热议,因为它比外界普遍推测的GPT-4参数量高出数倍。然而,热度尚未消退,剧情便迎来了反转。 这篇题为《不可压缩知识探针》

当我们谈论人工智能模型的训练时,通常会关注最终的考试成绩——也就是模型在验证数据上的表现。但哈佛大学、德国图宾根大学和Broad研究院的研究团队最近发现了一个令人意想不到的现象:就像运动员需要控制体

这项由北京航空航天大学与东京大学、StepFun公司联合开展的研究发表于2026年2月,论文编号arXiv:2602 20933v1,为3D场景重建领域带来了突破性进展。有兴趣深入了解的读者可以通过

这项由纽约大学研究团队完成的突破性研究发表于2026年1月,研究人员提出了一种全新的技术路径来改进AI文本生成图像系统,该论文编号为arXiv:2601 16208v1。有兴趣深入了解的读者可以通过

这项由伊朗伊斯法罕大学人工智能系的Erfan Nourbakhsh、德黑兰沙希德贝赫什蒂医科大学拉巴菲内贾德医院的Nasrin Sanjari,以及伊斯法罕理工大学机械工程系的Ali Nourbak
热门专题







热门推荐

如果你发现阿里系AI应用近期密集上线、品牌标识迅速统一、生态能力集中释放,这并非偶然——背后是一场精心布局的战略升级。阿里正在全面重构其AI时代的流量入口体系,具体正沿着以下几条关键路径加速推进。 一、品牌体系收束:从多头并进到千问单极 过去,阿里在AI产品线上采取分散布局:夸克侧重智能搜索,灵光聚

2023年初,一家欧洲奢侈品牌的中国区数字化负责人,收到了一份令人尴尬的年度审计报告。在“业务流程自动化覆盖率”这项关键指标上,中国区在全球各分公司的排名中,位列倒数第三。总部力推的UiPath平台,在中国团队的实际使用率竟不足30%。报告一针见血地指出,问题并非出在态度上,而是源于“工具与土壤的错

在Excel数据分析与报表制作中,跨工作表提取整行信息是一项常见且关键的操作。无论是进行多表数据整合、制作动态查询看板,还是完成日常数据核对,掌握高效的跨表提取技巧都能显著提升工作效率。本文将系统介绍六种实用方法,涵盖从基础函数到自动化工具的多种场景,帮助您根据数据结构和任务复杂度灵活选择最佳方案。

在小红书运营和内容创作中,分析爆款笔记、借鉴优质同行文案是提升账号表现的关键。然而,手动逐个点开笔记查看不仅耗时耗力,效率也难以保证。市面上虽然存在不少数据采集工具,但许多都需要付费订阅。实际上,也有免费且功能强大的替代方案,例如“实在Agent”平台推出的小红书采集智能体。它集成了热门笔记采集分析

在探讨实在智能RPA财务机器人的市场价格时,许多企业会发现其报价并非固定数值,而是呈现出从数千元到数十万元不等的宽幅区间。这种价格差异的背后,实际上是品牌实力、功能配置、性能水平、服务支持以及企业具体需求等多重因素共同作用的结果。 要清晰理解实在智能RPA财务机器人的定价逻辑,我们可以从以下几个核心