北大开源统一世界模型框架:多类合成推理任务一套搞定
世界模型,无疑是当前人工智能领域最受瞩目的前沿方向。其终极目标,是构建一个能够像人类一样感知、理解、交互并预测真实世界的统一智能系统。然而,理想与现实之间往往存在鸿沟。当前的研究现状是:视频生成、3D建模、具身控制、多模态推理等方向各自为战,接口标准不一,推理流程相互割裂,系统耦合度高。研究人员不得不为每一个特定任务重复搭建独立的推理逻辑和工程环境,这不仅造成了巨大的研发资源浪费,也使得不同模型与任务之间的横向对比与能力融合变得异常困难,最终制约了世界模型领域的系统性突破与规模化发展。
为了破解这一核心难题,来自北京大学DCAI课题组、快手可灵团队、上海算法创新研究院及中关村学院的科研人员,联合推出了一个名为OpenWorldLib的开源框架。其目标非常明确:为前沿的世界模型研究,提供一个统一、规范且高度可扩展的推理基础设施与标准化平台。

那么,究竟什么是世界模型?OpenWorldLib给出了一个清晰的定义:它是一种以多模态感知为核心,兼具交互能力与长期记忆,旨在理解和预测复杂物理世界的模型或框架。基于这一定义,该框架整合了理解、生成与行动三大核心能力,并构建了一套面向开源社区的标准化接口体系。这意味着,研究者们终于可以在一个统一的“实验场”上,对不同的先进模型进行便捷的复现、公平的对比和高效的扩展。
其核心价值,可以概括为四个“统一”:通过统一接口,屏蔽底层模型的异构性;通过统一推理流程,大幅降低工程复杂度;通过统一能力定义,促进跨任务的对齐与评估;最终,通过开源开放的社区生态,推动整个领域的协同创新与快速发展。

框架设计:模块化与统一调度
OpenWorldLib的架构设计,深刻体现了其“统一调度、模块化解耦”的核心思想。
整体架构
整个系统的核心是Pipeline调度模块。它负责串联各个功能组件,实现从原始输入到最终输出的完整推理链路。该模块不仅支持单轮的前向执行,更关键的是支持多轮的流式交互。在处理复杂任务时,它能自动调用记忆模块,实现上下文的读取与动态更新,从而让模型能够保持状态一致性并处理长期依赖关系。

具体而言,架构主要分为三层:
模型抽象层:无论底层是视频生成模型、3D重建模型还是具身控制模型,都在这一层被统一抽象封装。研究者只需按照一致的接口规范定义输入、输出和推理逻辑,无需关心底层技术实现的千差万别。
推理引擎层:内置了对多种主流推理后端(如PyTorch、TensorRT等)的兼容支持,用户可以通过简洁的脚本进行便捷调用,极大简化了模型部署与性能优化环节。
交互管理层:专门针对世界模型多轮交互的特性(例如条件视频编辑、3D场景的逐步探索)而设计,提供了统一的状态追踪、条件注入和增量推理管理机制。
Operator 机制:数据的“翻译官”与“质检员”
真实世界的输入是复杂且多样的:文本、图像、连续的动作指令、音频信号……如何让模型高效理解这些异构数据?这就需要Operator模块出场。它扮演着原始输入与核心执行模块之间的关键桥梁角色。
当Pipeline启动时,原始数据首先被送入Operator进行预处理。这里主要完成两项核心工作:一是数据校验,确保数据的格式、维度和类型符合下游模型的输入要求;二是标准化预处理,将原始信号转换为标准化的张量或结构化格式,例如调整图像分辨率、对文本进行分词与编码、对动作空间进行归一化。经过这番处理,杂乱的数据流就变成了模型能够高效“消化”的标准输入。

四大核心模块:各司其职,协同作战
在统一调度之下,是四个分工明确、协同工作的核心功能模块:
推理模块:负责多模态信息的理解与决策,涵盖通用常识推理、空间关系推理乃至音频语义推理。它的任务是将感知信息转化为结构化的语义表示,为后续的生成和行动提供依据。简单说,它负责“想明白”。
生成模块:负责多模态内容的创造,包括图像生成、视频合成、音频生成和动作序列规划。它将模型内部的推理与决策结果,转化为人类可观察或机器可执行的输出。这是“做出来”的一环。
表征模块:负责构建显式的、结构化的世界表示,例如3D场景重建、点云生成、深度信息估计。这为物理一致性建模和仿真验证提供了坚实基础,让模型对世界的理解从二维平面走向三维立体空间。

记忆模块:负责长期上下文与历史信息的管理,包括记忆的存储、基于内容的检索和动态状态更新。这使得模型能够支持多轮对话、长期任务规划等需要强大记忆能力的复杂场景。
实验效果:多任务验证框架潜力
为了全面验证框架的有效性与通用性,研究团队在多个典型的世界模型任务上进行了系统性评估,涵盖了视频生成、多模态推理、3D建模和具身控制等关键方向。
交互式视频生成
在视频生成任务中,OpenWorldLib支持导航视频生成与交互式视频编辑。实验表明,相较于早期的Matrix-Game系列等方法,接入该框架的新一代模型在生成长序列视频时,在视觉质量、时序连贯性和物理一致性上均有显著提升,有效减少了颜色漂移、物体形变和结构失真等问题,即使在复杂的交互指令条件下也能保持稳定的高质量输出。
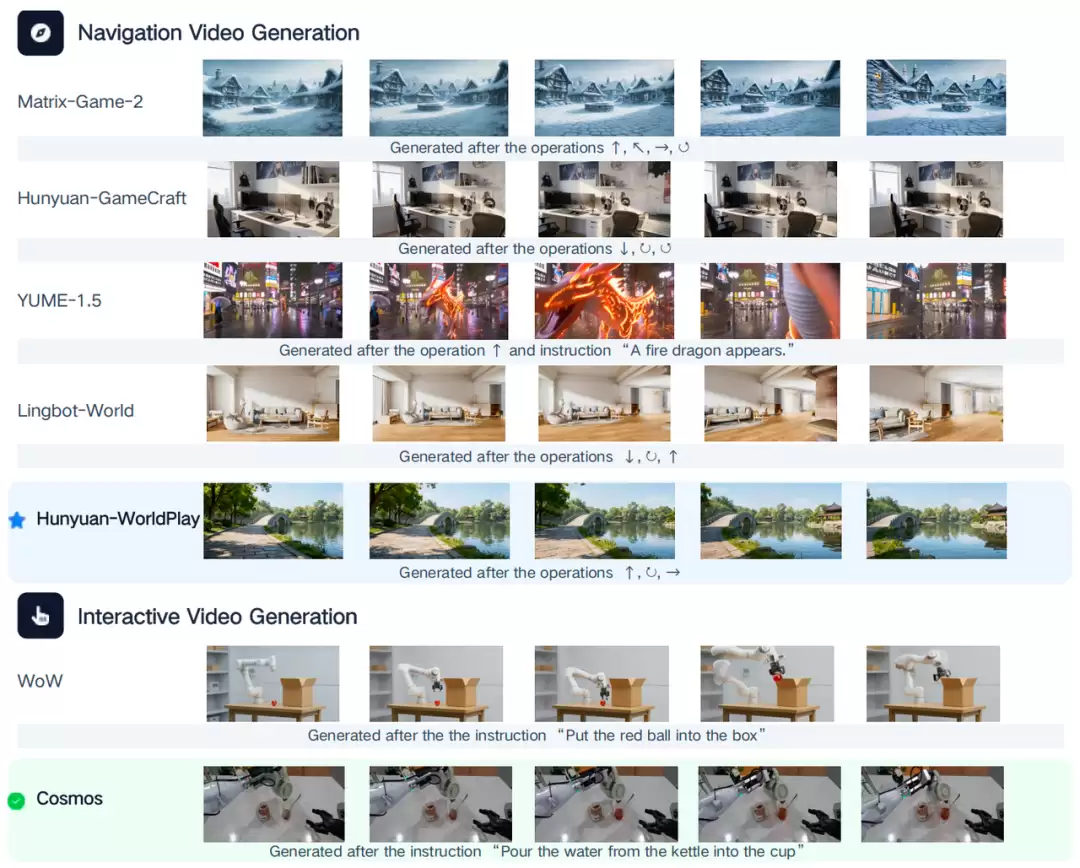
多模态推理能力
在推理任务中,框架的推理模块能够深度融合文本、图像等多模态信息,完成复杂的空间关系分析、因果推断和语义推理,并输出可解释的决策过程。这标志着模型不仅拥有强大的“生成”能力,更初步具备了“理解与决策”的认知雏形。
3D 场景生成与重建
在3D视觉任务中,通过其强大的表征模块,框架实现了从单目或双目视觉输入到结构化三维表示的统一建模。实验显示,尽管现有方法在极端大视角变化下仍面临几何不一致的挑战,但整体框架能够稳定支持多视角重建、新视图合成与物理仿真验证,为复杂三维场景理解与交互打下了坚实基础。

Vision-Language-Action(VLA)具身智能
在具身智能任务中,框架成功地将自然语言指令与实时视觉观测转化为机器人可执行的具体动作序列,实现了从“环境感知”到“指令理解”再到“动作执行”的完整闭环。这充分验证了OpenWorldLib在跨模态任务协同与真实物理世界交互中的巨大应用潜力。

总体来看,OpenWorldLib不仅在单一任务上表现优异,其更深远的意义在于,通过统一的框架首次实现了跨任务能力的深度整合与系统级协同,为未来构建更通用、更强大的多模态智能体迈出了关键一步。
使用方式:降低门槛,促进协作
对于广大研究者和开发者而言,OpenWorldLib提供了极其灵活且易于上手的接入方式:
单轮推理调用:用户可以直接通过简洁的Pipeline接口输入多模态数据,快速完成一次完整的推理过程,适用于标准的视频生成、视觉问答等场景。
多轮交互执行:通过stream()流式接口,系统会自动调用记忆模块维护对话或任务历史状态,非常适合交互式视频编辑、具身机器人控制等需要多轮交互的复杂长程任务。
模型扩展与接入:框架提供了清晰统一的模块抽象模板。开发者只需按照接口规范实现自己的Operator、推理、生成、表征或记忆模块,即可将新模型或新算法无缝接入现有架构,实现即插即用,无需改动其他部分。
开源生态与社区支持:项目目前已全面支持视频生成、3D建模、VLA控制与多模态推理等多类核心任务,并提供了完整的技术文档、教程和丰富示例。团队积极鼓励全球社区通过提交Issue和Pull Request的方式共同参与项目生态建设。
总而言之,OpenWorldLib通过其高度统一的接口设计和模块化架构,正在将世界模型的研究与开发体验,从“构建复杂工程系统”彻底转变为“进行标准化工具调用”。这不仅显著降低了人工智能研究与产业应用的门槛,更重要的是,它为未来构建更复杂、更通用的多模态大模型与智能系统,提供了一个坚实、可复用、可扩展的基础设施与创新平台。
项目相关链接如下:
论文链接:https://arxiv.org/abs/2604.04707
OpenWorldLib仓库:https://github.com/OpenDCAI/OpenWorldLib
相关攻略

世界模型,无疑是当前人工智能领域最受瞩目的前沿方向。其终极目标,是构建一个能够像人类一样感知、理解、交互并预测真实世界的统一智能系统。然而,理想与现实之间往往存在鸿沟。当前的研究现状是:视频生成、3D建模、具身控制、多模态推理等方向各自为战,接口标准不一,推理流程相互割裂,系统耦合度高。研究人员不得

世界模型成为科技巨头竞争焦点,其核心是让AI理解物理规则。魔芯科技创始人陈天润从3D打印转向空间智能,发现该领域同样存在数据规模效应。团队基于国产算力开发出高效、可终端部署的世界模型,并凭借消费电子领域的成本控制与工程化经验,推动技术在具身智能、自动驾驶等场景商业。

世界模型是AI构建现实世界内在模拟器的关键,旨在让智能体理解逻辑与因果关系以做出明智决策。在自动驾驶等场景中,需融合三维精度与物理规律,结合重建与生成方法,并探索数据与规则建模的结合。当前模型在动作反馈、奖励机制及因果建模方面仍存挑战,未来需强化交互与泛化能力。

成都发布了全国首个基于流形拓扑保持的机器人世界模型。该模型通过将高维物理状态映射到低维空间进行编码,为机器人构建了能深刻理解物理规律的“大脑”,使其决策严格符合物理规律,避免违背常理的错误。这项技术提供了跨场景的底层表征范式,将复杂感知数据压缩为具备内在几。

如果你一直关注AI架构的前沿发展,对Yann LeCun大力倡导的JEPA(联合嵌入预测架构)系列模型充满好奇,但又对动辄数百GB的预训练模型和复杂的工程代码感到无从下手,那么现在有一个绝佳的机会:有人将其核心思想,用最纯粹、最易懂的方式“翻译”成了代码。 最近,GitHub上出现了一个极具教学价值
热门专题







热门推荐

在全球紧张局势下,美国国防部将比特币重新定义为国家安全资产,反映出其战略价值提升。美国国库持有大量比特币,大国博弈中加密货币已成为国家安全筹码。市场普遍认为这一身份转变将增强机构需求,推动价格上涨。后续需关注美国政策动向、地缘政治变化及相关监管动态。

当Windows系统遭遇蓝屏时,那些含义不明的错误代码往往令人困扰。例如代码0x00000012 (TRAP_CAUSE_UNKNOWN),其官方解释为“内核捕获到无法识别的异常”。这就像一个笼统的系统警报,提示底层发生了问题,但并未指明具体故障点。此类错误通常不关联特定系统文件,反而更常见于新硬件

必须安装JDK并配置JA VA_HOME与Path环境变量;先下载JDK 17 21 LTS版本,安装时取消“Add to PATH”,再手动设置JA VA_HOME指向安装目录,并在Path中添加%JA VA_HOME% bin,最后用ja va -version等命令验证。 在Windows 1

对于Mac用户而言,从图片中提取文字其实无需额外安装第三方OCR软件。macOS系统自身就集成了强大的光学字符识别功能,它基于苹果自研的Vision框架与Core ML机器学习模型。最大的优势在于完全离线运行,所有图片处理均在本地完成,无需上传至任何云端服务器,充分保障了用户的隐私与数据安全。本文将

数据库长连接在静默中突然断开,是很多运维和开发都踩过的坑。你以为启用了TCP Keepalive就万事大吉?真相是,如果应用层、内核层和基础设施层的配置没有协同对齐,这个“保活”机制基本等于形同虚设。 问题的核心在于,一个完整的TCP Keepalive生效链条涉及三个环节:你的应用程序或连接池是否