西湖大学王东林团队CVPR论文:机器人如何通古今知未来
想象这样一个场景:机器人伸手去拿桌上的杯子,刚把杯子抬起来,动作却突然停住,随后又把它放回原位,紧接着再次伸手去拿。同一个动作,它重复执行,仿佛完全忘记了刚刚做过什么。这类情况在实际应用中并不罕见:按钮明明已经按下,机械臂却还在反复按压;抽屉明明已经关好,它却还在持续推挤。
这些失败的根源,往往不是“看不清”,而是系统缺少一套能够模拟时空演变的“世界模型”。现有的视觉-语言-行动模型虽然能理解图像与指令,但在连续任务中,决策依然严重依赖当前时刻的观测。一旦任务流程变长——例如需要依次完成拿起、移动、放置、关闭等一系列动作——模型就容易出现动作重复或决策中断。其核心瓶颈在于,缺乏对时间维度的理解与记忆能力。
这正成为具身智能迈向实用化的关键障碍。主流方法基于“看到什么就做什么”的即时反应机制,在短任务中尚可应对,但在长序列任务中,动作不连贯、决策漂移的问题便会凸显。如何让智能体不仅能感知当下,还能记住过去、预判未来,构成了新的核心挑战。
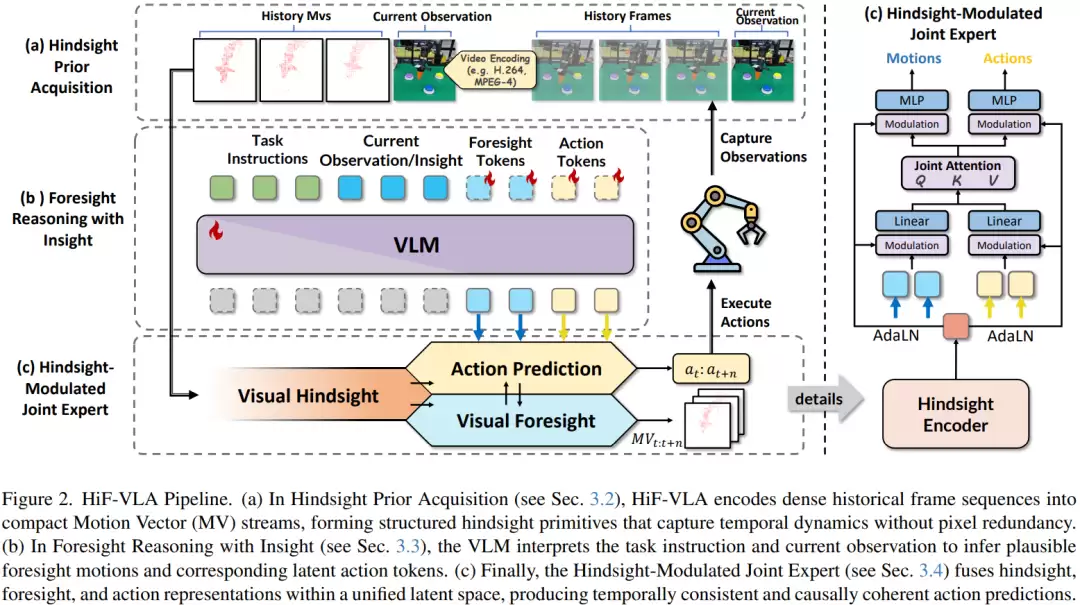
在此背景下,西湖大学王东林团队的最新研究《HiF-VLA:Hindsight, Insight and Foresight for Vision-Language-Action Models》提供了一种新思路。HiF-VLA 不再简单堆叠历史图像或预测未来画面,而是将“运动”本身作为时间信息的核心载体,使模型能够同步建模过去的变化、当前的状态以及未来的趋势,从而实现更稳定、连贯的序列决策。
这项工作的价值,不仅体现在性能指标的提升上,更在于它提出了一种范式转变的可能:让机器人从“被动反应”转向“边思考边行动”。在具身智能逐步走入真实世界的进程中,这种对时间的理解能力,正在成为决定系统是否真正可靠、可用的关键。

机器人不再「忘动作」:HiF-VLA如何提升长序列任务成功率
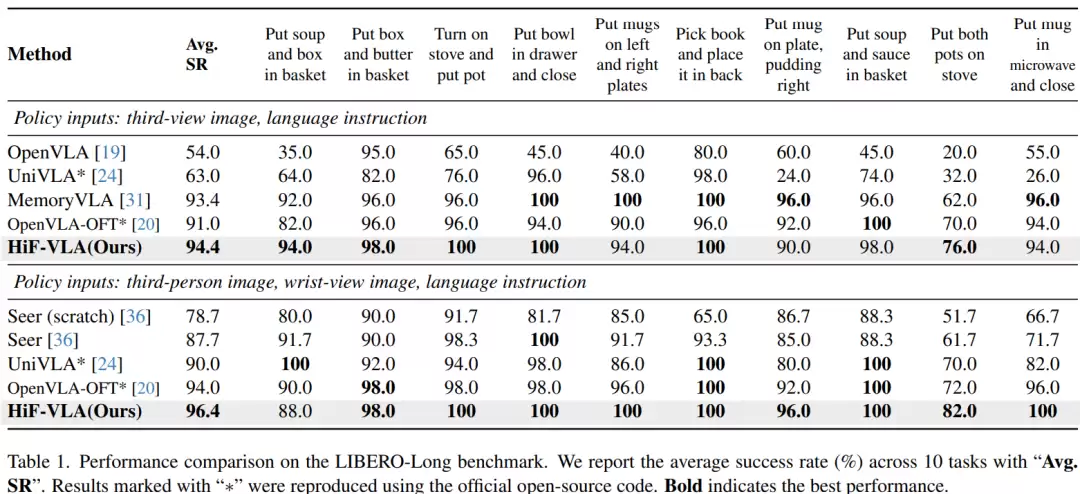
在长序列任务测试集LIBERO-Long上,研究主要评估机器人连续完成多个动作(如拿取、放置、关闭)的能力。结果显示,HiF-VLA在单视角条件下的任务成功率达到94.4%,在多视角条件下达到96.4%。
作为对比,当前表现较强的基线方法OpenVLA-OFT,在单视角和多视角下的成功率分别为91.0%和94.0%。这意味着,新方法在单视角下提升了3.4个百分点,在多视角下提升了2.4个百分点。
深入来看,在测试的10个具体任务中,有多个任务的成功率达到100%,最低的任务也有76%的成功率。这表明其性能提升是整体性的,而非依赖个别优势任务拉高平均。一个值得注意的现象是:该方法在单视角下的表现,已接近甚至达到了其他方法在多视角下的水平。这暗示着,其性能增益主要来源于对时间信息的有效建模,而非单纯依靠更多的视觉输入。
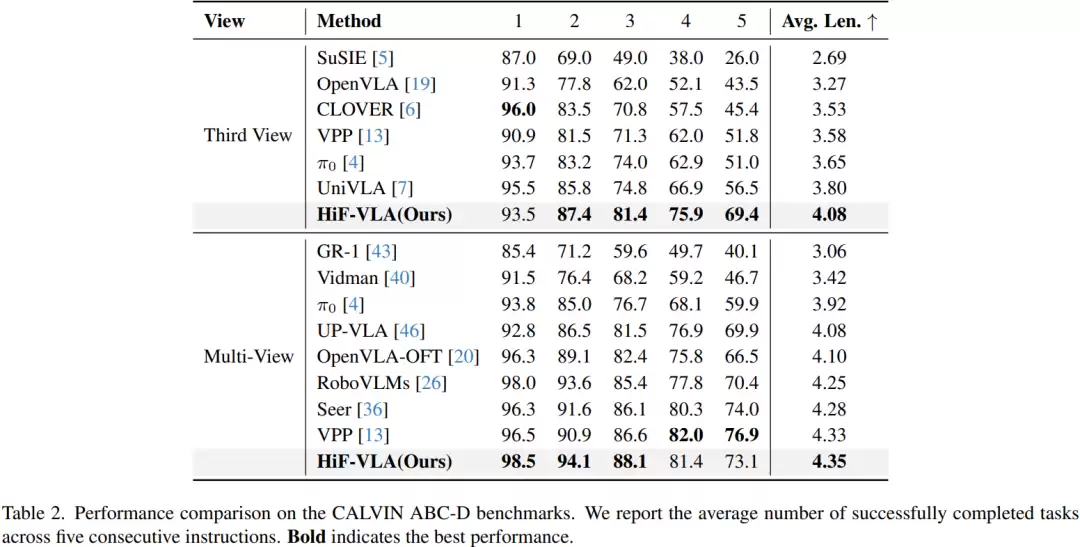
在CALVIN跨环境泛化任务中,研究在A、B、C三个已知环境中训练模型,并在全新的D环境中进行测试。评价指标是“连续成功完成任务数”,即模型能不间断地连续完成多少步操作。结果显示,新方法在单视角下平均完成4.08个任务,在多视角下达到4.35个。而基线方法OpenVLA-OFT约为4.10,Seer约为4.28,RoboVLMs约为4.25。
可以看到,新方法在多视角条件下取得了最高的4.35,相比基线提升约0.25个任务。这个提升颇具意义,因为该指标是累积性的,中间任何一步失败都会导致计数中断。数值越高,说明模型在长序列决策中的稳定性和长期规划能力越强。
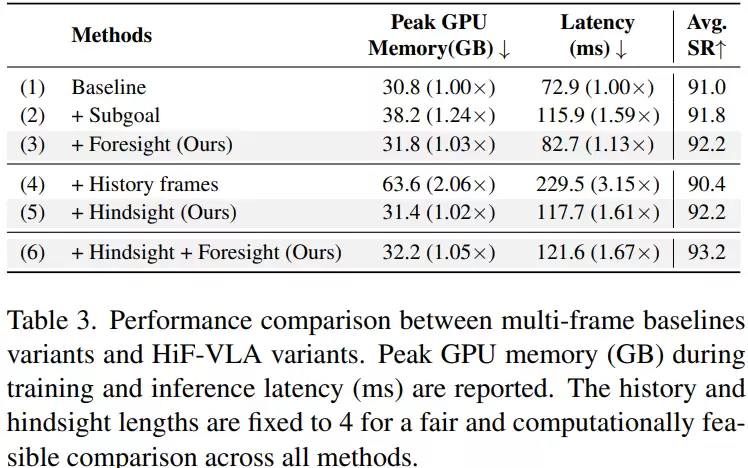
那么,性能提升是否以巨大的计算开销为代价呢?研究进一步分析了效率。当引入基于图像的未来子目标预测时,成功率可达91.8%,但决策延迟增至115.9毫秒,是基线的1.59倍。当采用堆叠历史图像帧的方法时,成功率反而降至90.4%,延迟飙升至229.5毫秒,是基线的3.15倍。这说明,直接处理大量图像信息不仅计算成本高,还可能干扰模型判断。
相比之下,HiF-VLA的方案显得高效许多:仅加入未来推理时,成功率为92.2%,延迟仅82.7毫秒,几乎无额外开销;仅加入历史信息时,成功率同样为92.2%,延迟为117.7毫秒;当历史与未来信息结合后,成功率提升至93.2%,延迟为121.6毫秒。整体来看,新方法在提升性能的同时,计算成本远低于堆叠历史帧的方案,证明使用运动信息比直接使用图像历史更加高效。
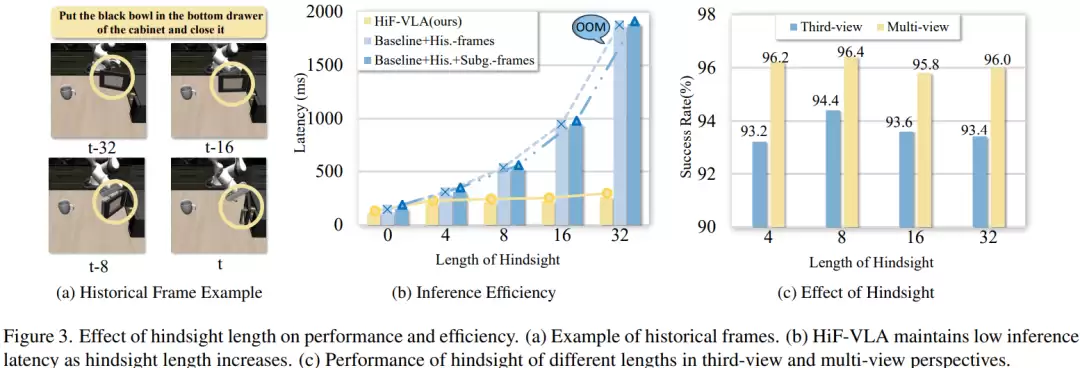
研究还测试了模型对时序长度的扩展能力。随着历史长度从4逐步增加到8、16、32,性能在长度为8时达到峰值(单视角94.4%,多视角96.4%),继续增加长度反而导致性能下降,原因是信息过载带来了冗余和干扰。在延迟方面,传统方法的计算成本会随历史长度线性增长,长度8时延迟增加约4.5倍;而新方法的延迟基本保持稳定,仅轻微增长,展现了在时间维度上更优的可扩展性。

最终,在真实机器人实验中,研究设置了多个长序列任务进行验证。在“按顺序按按钮”任务中,基线方法的成功率为17.4%,而新方法提升至34.2%,接近翻倍。在“覆盖与堆叠”任务中,基线为33.3%,新方法达到57.9%,提升了24.6个百分点。在“放置”任务中,基线约为62.5%,新方法约为65%,提升幅度虽小,但表现更加稳定。
研究人员分析认为,基线方法难以判断按钮是否已被按下,因为状态变化非常细微;而新方法能够利用时间变化信息来捕捉状态转变,因此在复杂任务中优势明显。这进一步证实,引入时间信息能显著增强机器人在长序列任务中的决策鲁棒性。
时间建模方法的系统性对比与实验设计
为了全面评估,研究在实验设计上进行了系统规划。在模拟环境中,采用了LIBERO数据集的10个长序列任务,以及CALVIN数据集的跨环境泛化任务。在真实机器人实验中,每个任务收集了100条示范数据用于训练,并在测试阶段对每个任务执行20次,以评估模型的稳定性和泛化能力。
在输入信息设计上,模型同时接收三类信息:当前画面(感知当前状态)、历史运动(表达过去的动态变化)以及语言指令(提供任务目标)。这种设计使得模型能够在时间维度和语义层面进行联合决策。
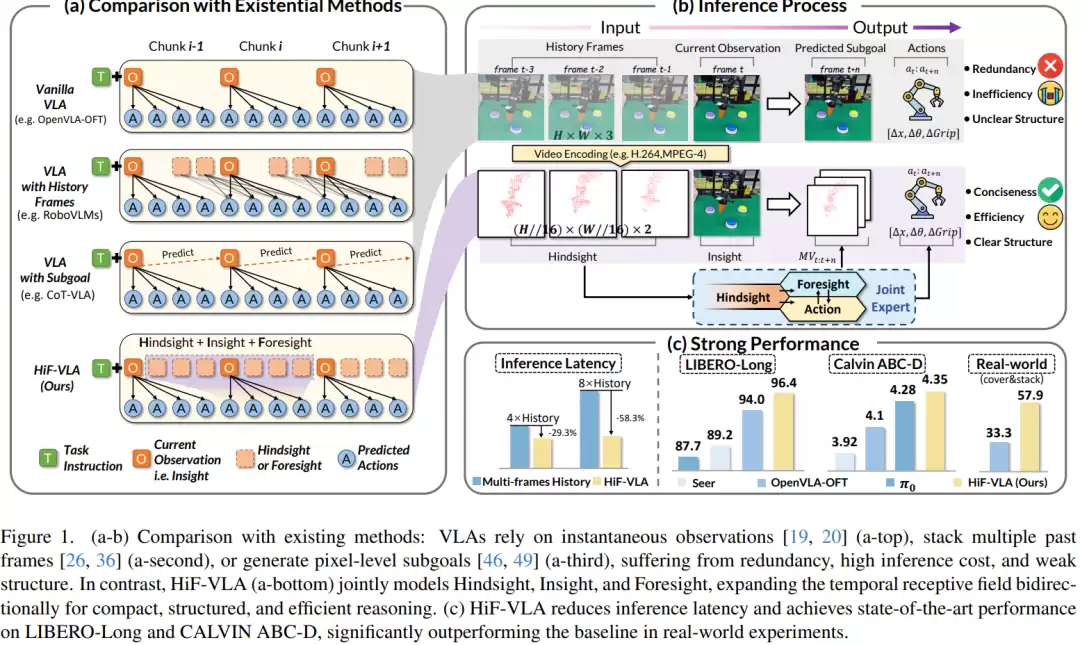
研究团队设置了多种基线方法进行系统比较:第一种仅使用当前观测,不含任何时间信息;第二种通过堆叠历史图像引入时间信息,但存在信息冗余和计算成本高的问题;第三种通过预测未来图像作为子目标来引导决策,但容易产生误差且稳定性差。相比之下,新提出的方法用运动信息替代图像来表示时间变化,从而减少了冗余,提高了建模效率。
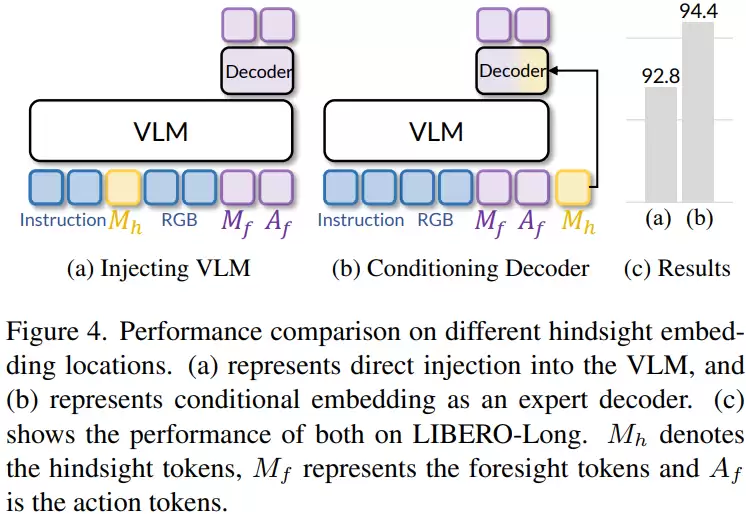
通过消融实验,研究进一步剖析了不同设计选择的影响。首先在历史长度上,实验表明最优长度为8,过短则信息不足,过长则引入冗余干扰判断。其次在历史信息的使用方式上,比较了两种策略:一种是将历史信息直接输入视觉语言模型,此时成功率为92.8%;另一种是将历史信息注入到后续的决策模块中,成功率则提升到94.4%。这一结果说明,将历史信息直接混入前端视觉语言处理流程,可能会干扰其原有的理解能力;而在决策阶段引入历史信息,能更有效地发挥其作用。
从「看到就做」到「边想边做」:具身智能的范式演进
这项研究首先直指一个核心问题:传统模型决策时过度依赖当前观测,忽视时间信息,导致动作不连贯,在长序列任务中易失败。问题的根源并非视觉能力不足,而是缺乏对时间流的建模能力。
基于此,研究提出了一个关键发现:运动信息比原始图像更适合表征时间变化。图像中包含大量静态背景信息,而运动信息则过滤了冗余,只保留真正发生变化的部分,因而更高效、表达力更强。
这一发现带来了直接的影响:机器人的决策过程,从“感知-动作”的单向链条,转变为同时考量过去、现在与未来的综合过程。换句话说,从简单的“看到就做”,升级为基于历史经验、当前状态及未来预测共同驱动的“边想边做”。
在工程价值上,实验数据表明,该方法不仅在性能上取得显著提升(最高成功率96.4%),同时在计算效率上具备优势,避免了传统方法可能带来的数倍计算开销。此外,它在不同环境中展现出更强的泛化能力,并且在真实机器人实验中同样有效,预示着可观的实用化潜力。
更进一步看,这项工作推动了一种智能范式的演进:从“看到就做”的视觉-语言-行动模型,走向“边想边做”的世界-行动模型。HiF-VLA改变的不仅是模型架构,更是在重新定义机器人应具备的能力边界。
过去的系统更像被动的执行者,只对瞬时输入做出反应;而在新范式下,机器人开始具备连续决策的能力,能够在行动中记忆刚发生的状态,判断当前所处的阶段,并预判接下来的步骤。这种转变意味着,机器人不再只是执行孤立的动作,而是能够理解并管理一个完整的任务流程,并在过程中动态调整行为。
这也标志着,具身智能的发展正从“感知驱动的反应系统”,迈向“时间驱动的推理系统”。只有当模型真正掌握这种能力,机器人才能在复杂、动态的真实世界中稳定工作,而不仅仅是在受控的实验室场景中完成预设脚本。
HiF-VLA 背后的科研力量:王东林与黄思腾团队
本论文的通讯作者王东林,现任西湖大学人工智能系副主任,是机器智能实验室(MiLAB)的创始人与负责人,同时也是西湖机器人科技(杭州)有限公司的创始人。
他本科与硕士毕业于西安交通大学电子信息工程专业,后在加拿大卡尔加里大学获得电子与计算机工程博士学位,并在加拿大从事博士后研究。此后,他在美国纽约理工学院任教并晋升为副教授,于2017年回国加入西湖大学,成为工学院首批全职教师之一,创建了机器智能实验室。他还担任国家科技创新2030重大项目首席科学家,并入选国家人社部高层次人才计划。
其研究方向长期聚焦于机器人学习与智能决策,重点关注强化学习、元学习及机器人行为智能,目标是让机器人具备自主学习、快速适应新环境并完成复杂任务的能力。研究不仅关注感知理解,更强调从感知到决策再到行动的完整闭环,尤其是在长序列任务和真实环境中的稳定执行能力。
在学术成果方面,他已发表百余篇论文,活跃于机器人学习与强化学习等前沿领域。其团队是国内最早专注机器人学习的团队之一,提出了国际首个四足机器人VLA大模型、人形机器人VLA大模型、奖励无关人类反馈强化学习等创新工作。其近期合作的AAAI 2026论文斩获最佳论文奖,同时带领研发的通用行为专家大模型GAE也达到了人形机器人运动领域的国际领先水准。

另一位通讯作者黄思腾,现任阿里巴巴达摩院算法专家,博士毕业于浙江大学与西湖大学联合培养项目,在机器智能实验室完成博士研究,师从王东林教授。此前,他于武汉大学计算机科学专业获得本科学位。博士期间,他曾在阿里巴巴通义实验室与达摩院进行长期研究实习,整体经历贯穿学术研究与工业界实践。
其研究方向主要聚焦于具身智能、多模态大模型及高效人工智能,核心关注如何让模型同时理解图像、视频、语言及物理世界中的动态信息,并在真实环境中进行感知、推理与生成。研究不仅涉及多模态理解与生成,还强调模型在数据、计算和存储等方面的效率优化,致力于构建能在现实世界中高效运行的统一智能系统。
在学术成果方面,他已在相关领域发表三十余篇论文,涵盖计算机视觉、多模态学习与机器人方向,并活跃于顶级国际会议和期刊。他参与了多项具身智能与多模态模型方向的研究工作,包括视觉语言行动模型及统一世界模型等,代表性工作涉及HiF-VLA、RynnVLA系列以及WorldVLA等框架,推动了机器人在长序列任务与真实环境中的能力提升。

相关攻略

机器人长序列任务中常因缺乏时间理解能力而动作重复或中断。西湖大学团队提出HiF-VLA模型,以运动信息为核心同步建模过去、现在与未来,实现更连贯的决策。实验表明,该方法在多项任务中显著提升成功率与计算效率,推动机器人从被动反应转向具备时序推理能力的“边想边做”模式。

训练一个AI画家,传统思路和教小朋友认图识字差不多:给它看海量图片,同时每张图都得配上准确的文字描述。这方法固然有效,但瓶颈也很明显——收集这种高质量的“图文配对”数据,既耗时又昂贵,无异于给一个庞大的照片库手动撰写详尽的图说。 有没有可能换一种教法?最近,一项由西湖大学、浙江大学和上海创新研究院合

一项由西湖大学、香港科技大学(广州)等多所知名高校联合开展的研究,于2026年发布了其研究成果,论文编号为arXiv:2602 17259v1。研究团队开发了一套名为FRAPPE的革命性训练框架,其核心目标是赋予机器人一种类似人类的“未来眼”——预测未来并据此做出更智能决策的能力。 伸手去拿桌上的水

这项由西湖大学工程学院团队完成的研究,发表于2026年的ICLR会议。对技术细节感兴趣的读者,可以通过论文编号arXiv:2602 03828v1查阅全文。 不知你是否留意过,在阅读科学论文、教科书或技术博客时,那些能将复杂概念一目了然呈现出来的插图,其说服力往往远超长篇累牍的文字。然而,制作一张高

为什么很多蛋白质药物效果好、副作用小,却非得天天给药? 这背后其实是一个困扰药物研发领域多年的“动力学矛盾”。蛋白质药物虽然识别精准、安全性高,但它们在体内的“寿命”往往很短,代谢速度很快。与此同时,它们与疾病靶点发生关键的共价反应,速度却又相对较慢。结果就是,药物还没来得及牢牢“锁住”靶点,就已经
热门专题







热门推荐

知名制作人阿迪·尚卡尔透露,在卡普空发布新作后,他收到大量粉丝请求,希望将科幻游戏《识质存在》动画化。他认为该游戏因“不寻常且原创性十足”而备受关注。但目前他并无改编计划,而是选择专注于全新的原创项目,以探索更多叙事可能性。

《班迪与油印机》是一款融合平台跳跃与解谜的冒险游戏。攻略从基础操作讲起,详细介绍了前八关的核心玩法与技巧,包括利用特殊动作通过地形、应对各类机关与Boss战策略。游戏过程中可收集资源以升级能力,探索隐藏区域。其关卡设计富有创意,难度较高,但攻克后能获得显著成就感。

在《异环》游戏中,获取那台备受瞩目的AE86幽灵车外观,关键在于完成白杨的支线赛车挑战。许多玩家在此环节遇到困难,感觉对手速度难以超越。实际上,掌握正确技巧后,赢得比赛并不复杂。 异环白杨赛车任务通关技巧详解 获胜的核心策略可以总结为:把握弯道优势,主动实施碰撞。 白杨的车辆起步与直线加速性能确实出


心魔15层需冰抗180、火抗220以应对高额元素伤害,并把握BOSS施法前摇。16层需优先集火“魅惑魔灵”以防混乱,并稳妥处理高伤“穿刺者”。17层需兼顾元素区域走位与快速击破回血核心,考验团队输出与生存综合能力。这三层逐级挑战生存、节奏与整体实力。