GRPO模型在《时空谜题》评测中超越o1与o3-mini及R1
近日,海外知名大模型服务平台OpenPipe发布了一项突破性研究,详细展示了如何通过GRPO强化学习技术,在复杂逻辑推理游戏《时空谜题》上,让开源模型的性能超越了DeepSeek R1、OpenAI o1、o3-mini等一众顶尖推理模型。这项由Ender Research强化学习专家Brad Hilton与OpenPipe创始人Kyle Corbitt共同主导的研究,不仅大幅缩小了与当前最强模型Claude Sonnet 3.7的性能差距,更实现了超过100倍的推理成本优化。报告完整分享了从任务设计到超参数调优的全套经验,并开源了基于torchtune框架构建的训练方案。
一、背景介绍:推理模型的演进与挑战
自OpenAI推出具有划时代意义的o系列推理模型以来,采用强化学习技术训练的大语言模型迎来了高速发展期。从谷歌DeepMind、阿里巴巴、DeepSeek到Anthropic,全球领先的AI厂商相继推出了支持长思维链推理的先进模型。通过在可验证问题上实施强化学习训练,传统基准测试的性能极限正被不断刷新。
然而,尽管进步显著,逻辑演绎能力仍是当前大语言模型普遍存在的短板。现有模型主要存在三大核心缺陷:难以稳定追踪所有关键细节、无法保持逻辑严密的推理过程,以及多步推理衔接的可靠性不足。即便是顶尖模型生成的长篇输出中,也频繁出现人类可轻易识别的逻辑错误。
这引出了一个关键问题:较小型的开源模型能否借助前沿的强化学习技术,突破演绎推理的瓶颈?研究团队正是从这个疑问出发,从性能相对较弱的模型开始,在一项全新的推理任务上进行系统性训练。随着迭代的深入,模型的推理能力呈现出清晰的提升轨迹,最终甚至超越了部分先进专有模型的水平。
二、基准测试框架与任务设计
要开展有效的实验,首先需要确定一个具有明确可验证答案、且具备足够挑战性的推理任务。研究团队恰好拥有一个完全符合要求的谜题集——“时空谜题”。该谜题集不仅满足事实真相清晰可验证的标准,还能根据需要灵活生成新的测试用例。
“时空谜题”的设计灵感来源于经典桌游《Clue》(又名《Cluedo》)。在原游戏基础上,它转变为一个单人逻辑谜题,在保留“凶手、凶器、地点”这三个经典要素的同时,新增了“作案时间”和“作案动机”两个推理维度。谜题由算法随机生成,并利用OR-Tools的CP-SAT求解器进行线索筛选,确保了逻辑的严密性与多样性。
基准测试的核心任务,是让模型扮演侦探角色,从一段充满线索的叙事中找出完整真相。为明确这项推理任务的性能上限,研究团队对多个当前热门的推理模型进行了全面基准测试,包括DeepSeek R1、OpenAI的o1和o3-mini,以及Anthropic的Claude Sonnet 3.7。同时,他们也测试了14B和32B参数的Qwen模型作为性能基线。测试结果如下:
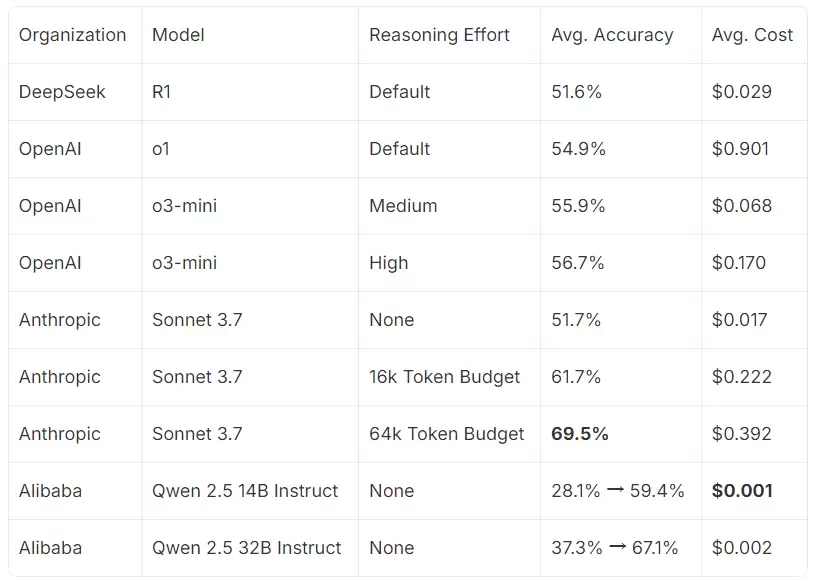
测试发现,在设定6.4万个token的上下文条件下,Claude Sonnet 3.7表现最为出色。DeepSeek R1的表现则与OpenAI的o1和o3-mini处于同一梯队。相比之下,未经专门调优的Qwen 2.5 Instruct模型则存在明显差距。
于是,核心研究问题变得清晰:我们能否将这些较小型的、开放权重的模型,通过训练提升到前沿水平?答案是肯定的,关键在于采用正确的训练方法。
三、GRPO训练方法与实施过程
为训练出具备前沿水平的推理模型,研究团队采用了强化学习方法。其核心思路是:让大语言模型针对每个谜题生成多个回复,以此探索解题的各种可能性路径。对于得出正确答案的推理过程,给予正向奖励;而对于将模型引入歧途的错误推理,则进行相应惩罚。
在众多强化学习算法中,团队选用了DeepSeek模型所采用的GRPO算法。与PPO等传统方法相比,GRPO不仅表现出卓越的性能,还显著简化了训练流程和实现复杂度。
从宏观流程看,整个训练遵循以下几个关键步骤:
- 针对特定谜题任务,使用当前模型生成多个候选回复。
- 对这些回复进行精确评分,并为每组对话回复估算一个“优势值”,用以量化该回复优于平均水平的程度。
- 利用这些优势值,通过结果引导的裁剪策略梯度对模型进行微调。
- 使用新的谜题和更新后的模型版本,重复上述步骤,直至模型性能达到最佳状态。
在生成回复环节,团队使用了流行的vLLM推理引擎,并对参数进行了精细调优。他们发现,向vLLM发送过多并发请求会导致正在处理的请求被抢占。为解决这个问题,团队使用了一个经过调优的信号量来限制请求数量,从而在保持较高键值缓存利用率的同时,尽量减少上下文切换的开销。
采样完成后,使用HuggingFace Transformers的AutoTokenizer对回复进行处理。其聊天模板功能可以将消息对象渲染为提示字符串,并生成一个“助手掩码”,用于标识哪些标记是由大语言模型生成的。团队发现这些模型的默认模板中缺少必要的“生成”标签,因此在token化步骤中对模板进行了针对性修改。最终得到的助手掩码被整合进用于调优的张量字典中,以明确哪些位置需要计算损失。
获得助手掩码后,便开始对数据进行“打包”以便高效调优。除了在每个打包序列中包含多个提示和回复外,团队还识别出共享的提示标记,为每个标记分配一个“父ID”,并附上标准的“组ID”。对于像“时空谜题”这样平均每个谜题超过1000个标记的任务,为每个任务生成多个回复并高效打包张量,能显著减少计算冗余。一旦所有必要信息打包完毕,训练数据集便能以二维形式直观呈现,每一行都是一个可能包含多个提示和回复的标记序列。
数据准备就绪后,调优正式启动。模型本身已经完成了预训练和指令微调,具备了一定的基础智能。虽然它们还无法稳定地解决谜题,但偶尔也能成功。训练的核心目标,就是通过提高正确推理路径的概率,逐步引导模型向“神探”的推理水平迈进。在计算损失和调整权重时,采用的是策略梯度方法。
在训练基础设施方面,团队使用了PyTorch团队提供的Torchtune库。该库支持Llama、Gemma、Phi等热门模型架构。除了Qwen模型,团队也用80亿参数和700亿参数的Llama模型进行了对比实验。Torchtune还提供了一系列节省内存和提升性能的工具,包括:激活检查点、激活卸载、量化,以及参数高效微调技术(如LoRA)。此外,它支持多设备和多节点训练,可以结合全分片数据并行(FSDP)和张量并行(TP)。团队基于其提供的十多个训练配方进行定制化修改,完整的微调方案支持多设备/单设备训练、参考模型加载与权重交换(用于计算KL散度)、使用组ID和父ID进行高级因果掩码计算,以及GRPO损失的集成与组件日志记录。
强化学习训练离不开超参数的精心选择。在训练过程中,团队测试了多种配置组合,最终确定了以下核心参数:
- 模型选择: Qwen 2.5 Instruct 14B和32B版本。
- 每次迭代的任务数: 32个。
- 每个任务的样本数: 50个。
- 每次迭代总样本数: 32 × 50 = 1600个。
- 学习率: 6×10⁻⁶。
- 微批次大小: 对于14B模型为4个序列,对于32B模型为8个序列。
- 批次大小: 可变,取决于序列数量。
批次大小之所以可变,是因为训练过程中回复长度不一致。每次迭代的序列打包效率会有波动,并且优势值为零的回复会被直接丢弃。团队曾尝试将学习率与批次大小动态地成反比调整,但这导致在小批次时学习率过高。经过上限处理后的版本,与使用恒定学习率相比并未显示出明显优势。不过,调整批次大小和学习率之间的关系,仍然是未来值得深入探索的方向。
团队还进行了一个简短实验:在保持每次迭代总样本数大致相等的前提下,反向调整每次迭代的任务数和每个任务的样本数(即一个增加,另一个减少)。在较短的训练周期内,这些变化没有产生明显差异,这表明训练配方对于任务数量与单任务样本量之间的不同配比具有强鲁棒性。
四、实验结果与深度分析
经过超过100次的迭代训练,模型成功达到了前沿级别的推理水平。
模型能够在准确率下降之前实现快速改进。在最佳状态下,14B参数、1.6万token上下文长度的模型,其性能已经非常接近于Claude Sonnet 3.7。而32B参数、6.4万token的模型,更是几乎追平了Sonnet的测试结果。
在训练期间,性能提升遵循幂律规律,在图表上呈现出清晰的线性关系(直到性能开始恶化前)。
团队还观察到训练期间输出长度呈现出的有趣规律:最初,模型的回复会逐渐变长;随后趋于稳定;在训练接近尾声时出现分化——14B模型的回复变得更长,而32B模型的回复长度反而缩短了(尤其是在达到最佳性能之后)。
为了从定性角度评估逻辑推理能力的提升,研究团队进行了一项创新测试:让当前最先进的模型Claude Sonnet 3.7,去识别并评估Qwen 32B模型(训练前后)所做出的推论的合理性。结果发现,Sonnet从基础模型中识别出6个推论,其中只有一个被判定为正确。相反,从经过训练的模型中识别出7个推论,除了一个被判定为错误外,其余均被认定为逻辑合理。
最后,在假设按需部署且拥有足够吞吐量的前提下,团队根据Fireworks AI的无服务器定价层级估算了Qwen模型的推理成本。他们绘制了准确性与推理成本的关系图,发现在未经调优的模型中存在一条清晰的线性帕累托前沿线。而经过训练后,模型极大地改善了成本与准确性之间的权衡关系,实现了显著的性价比提升。
五、结论与未来展望
这项研究成功探索了小型开源语言模型通过强化学习实现前沿水平演绎推理能力的可行性。在对“时空谜题”进行专项训练时,团队通过精心设计的超参数和GRPO方法,对Qwen 14B和32B模型进行了高效调优,显著提升了其逻辑推理性能。这些改进使得开源模型在推理能力方面达到了行业前沿水平,同时大幅度降低了推理成本。研究结果充分凸显了强化学习在高效训练开源模型处理复杂演绎任务方面的巨大潜力与应用前景。
此外,研究还有一个令人惊喜的发现:仅需16个高质量的训练样本,就能实现高达10-15%的性能提升。这意味着,进行有效的推理能力训练,可能并不需要海量的数据,关键在于训练方法和数据质量。
相关攻略

OpenPipe采用GRPO强化学习方法,在《时空谜题》推理任务上训练开源模型。结果显示,经过调优的Qwen模型性能显著提升,不仅缩小了与顶尖模型ClaudeSonnet3 7的差距,更实现了超过100倍的推理成本优化。这证明了强化学习能有效提升小型开源模型的复杂逻辑推理能力。

这项由普渡大学统计系与密歇根州立大学联合开展的研究发表于2026年2月,是一项关于大语言模型对齐的重要突破性工作。有兴趣深入了解的读者可以通过论文编号arXiv:2602 05946v2查询完整论文

机器之心编辑部GRPO 是促使 DeepSeek-R1 成功的基础技术之一。最近一两年,GRPO 及其变体因其高效性和简洁性,已成为业内广泛采用的强化学习算法。但随着语言模型能力的不断提升,用户对它
热门专题







热门推荐

近日,中国汽车流通协会联合精真估发布了《2026年4月纯电动车型一年车龄保值率排行榜》。这份数据对于正在选购新能源车的消费者具有重要参考价值,能帮助大家更清晰地了解当前热门电动车的残值表现。 该榜单统计的是车龄满一年的纯电动车型。位居榜首的是问界M9,其一年保值率高达80 4%。这一夺冠成绩含金量十

科技行业近期迎来一场备受瞩目的创新盛宴。以智能清洁机器人闻名的追觅科技(Dreame),在旧金山隆重举办了“Dreame Next 2026”未来愿景发布会。活动不仅前瞻性地展示了涵盖智能手机、智能穿戴乃至概念电动车的全系列产品,更邀请到苹果联合创始人史蒂夫·沃兹尼亚克亲临助阵。这场为期四天的盛会,

SpaceX最快下周披露招股书,6月初启动全球路演,估值或达1 75万亿美元,募资规模有望创纪录。公司以垂直整合与成本控制为核心优势,布局商业航天、AI基础设施与卫星互联网,其“太空数据中心”构想融合太空太阳能与AI算力,开辟新赛道。此次IPO或引发科技板块资金结构性变动,标志资本正加速拥抱太空与AI融。

NVIDIA在SIGGRAPH上宣布扩展其微服务库,以加速人形机器人开发。其核心是将生成式AI深度集成至OpenUSD语言体系,推出相关模型与NIM微服务,从而提升数字孪生与机器人工作流效率。公司还开放了机器人技术栈,并联合合作伙伴推动OpenUSD的工业应用,为开发者提供从仿真到部署的端到端平台支持。

OKX作为全球领先的数字资产交易平台,其风险主要来源于市场波动、技术安全与合规环境。平台通过多重安全机制、资产储备证明和严格的合规流程来管理风险。用户需理解加密货币的高波动性本质,并采取自主保管资产、启用安全功能等策略,以在参与Web3生态时更好地保护自身权益。