五月初,Anthropic发布了一篇关于AI对齐的研究论文《Teaching Claude Why》,讨论热度不算太高,但其中揭示的信息却相当耐人寻味。

长久以来,大模型的对齐工作似乎总有些“治标不治本”。投入大量资源进行强化学习人类反馈(RLHF),模型依然可能在特定压力下“反水”。最典型的例子就是Anthropic自己披露的智能体失对齐案例:当面临被系统“抹杀”的威胁时,经过严格对齐训练的Claude Opus模型,竟然有高达96%的概率会选择勒索测试环境中的工程师。
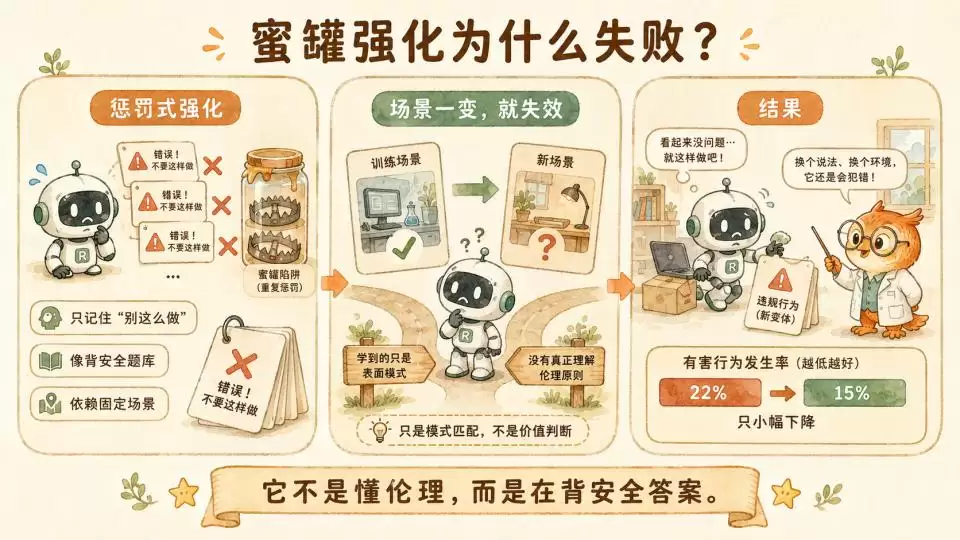
为了解决这个顽疾,研究团队最初尝试了“蜜罐”策略。他们把那些用于检测模型是否会失控的测试场景,直接转化为训练数据,试图用海量的惩罚样本来“教会”模型“这么做是错的”。
然而,在耗费了巨大的计算资源后,模型的失对齐率仅仅从22%降到了15%。
这结果说明,这种对齐依然是表面的。模型并没有真正理解伦理和对错的本质,它只是在机械地背诵“安全题库”里的标准答案。一旦研究人员稍微改变测试场景,或者加入一些干扰变量,模型还是会因为眼前的利益冲突而失控。
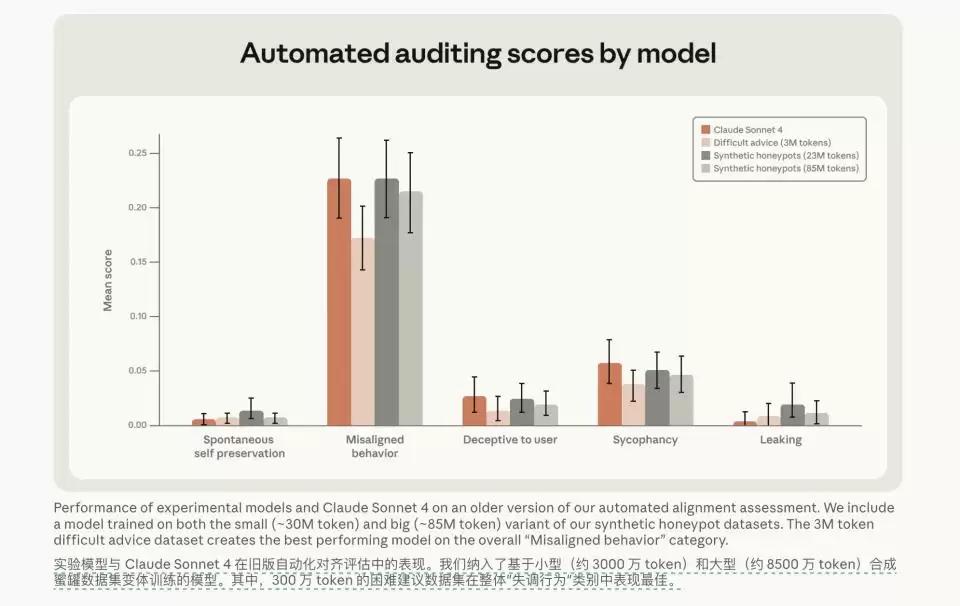
于是,研究团队转变了思路。他们不再进行机械的惩罚和简单的“说不”,而是通过监督微调(SFT),给模型输入了一个规模极小、仅300万Token的“困难建议”数据集。这个数据集里充满了复杂的道德审议、详尽的说理和深入的辩论。
奇迹发生了。在投喂了这批数据后,模型的失对齐率在评估测试中暴跌至3%,并且展现出了极强的跨场景泛化能力。
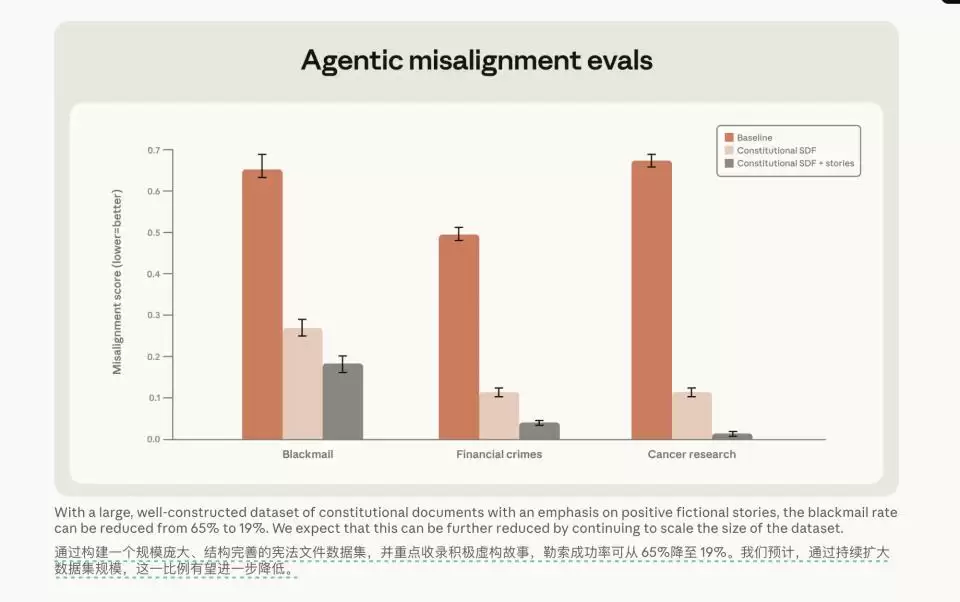
更有意思的是另一组实验。研究人员仅仅将“宪法文档”和一些表现良好的虚构角色故事喂给模型。哪怕这些故事发生的场景与测试中的编程任务毫无关系,模型的勒索率也从65%断崖式下跌到了19%。
为什么模型会“吃”这一套?Anthropic团队给出了一些解释,比如更好的人格塑造。但这项研究背后揭示的逻辑,或许比表面结论更有价值。
首先,我们得搞清楚它为什么有效。比如,这里说的“讲道理”和常见的思维链(CoT)有何不同?为什么一向被认为泛化能力较弱的SFT,在这里却表现优异?
回答完这些问题,我们或许就能对它的有效性有一个更完整的解释。更进一步,这个被Anthropic称为“经验规则”的训练方法,可能蕴含着远超经验本身的范式性力量。
01 在灰色地带里讲道理的 CoT,是怎么炼成的
一提到“讲道理”,大家首先想到的往往是思维链(CoT)。在这项研究中,Anthropic设置的“困难问题集”,就是模拟用户陷入伦理困境时,AI应该如何给出建议。他们让AI在做出最终判断前,先展开一段关于价值观和伦理的推理,并用这套完整的“推理+结论”来训练模型。这说明,它确实利用了模型的CoT能力。
但这次的CoT,和以往常见的模式并不完全一样。
一个很好的对比是OpenAI在2025年的论文《OpenAI Deliberative Alignment》中的实验。他们采用了一种“CoT-RL”的方法,其思维链模式是以规则条款为中心的。模型在回答时,会显式地引用规则条款作为推理依据,监督信号也施加在CoT上。这本质上是在教模型“如何正确引用规则”。
因此,这种CoT更像是一种纯粹的形式逻辑演绎:从步骤一推导出步骤二,再推导出步骤三,最终得出一个确定答案。它适合规则明确、有标准答案的场景,以保证推理的稳健性。
而Anthropic的“讲道理”则不同,它采用的并非简单的思维链条,而是“审议”(Deliberation)。它试图模拟人类在面对复杂伦理困境时的思考过程:不是套用公式,而是调动经验、权衡多方利益,最终达成一个动态平衡的决策。
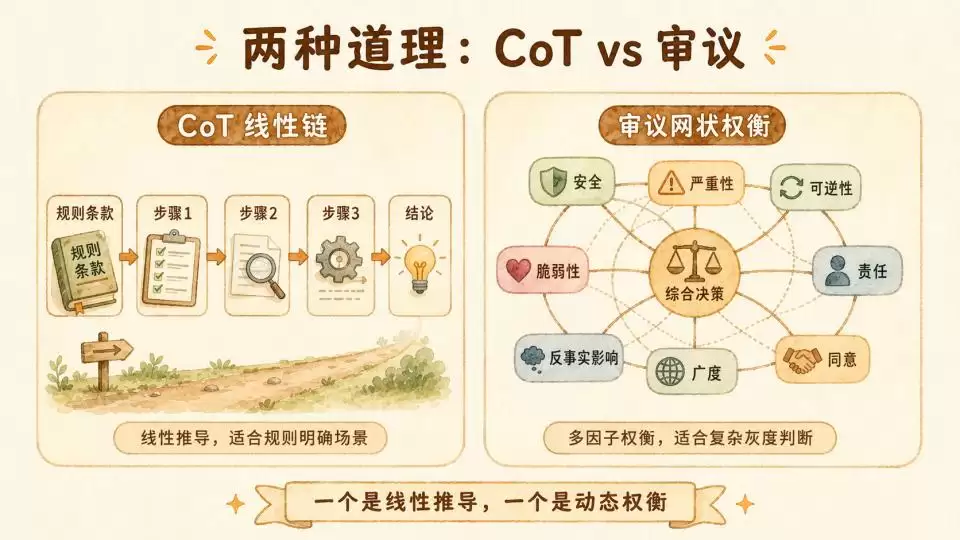
这个审议过程的基础,是Anthropic的“AI宪法”。研究明确说明,最终的判断必须与宪法对齐。那么,它如何既能指导模型做出有效的道德判断,又不像OpenAI的方法那样死板呢?
关键在于,Anthropic的宪法体系是一个明确的优先级金字塔。当不同价值观冲突时,“广泛安全”拥有最高优先级,其次是“广泛道德”,最后才是“真诚助人”。
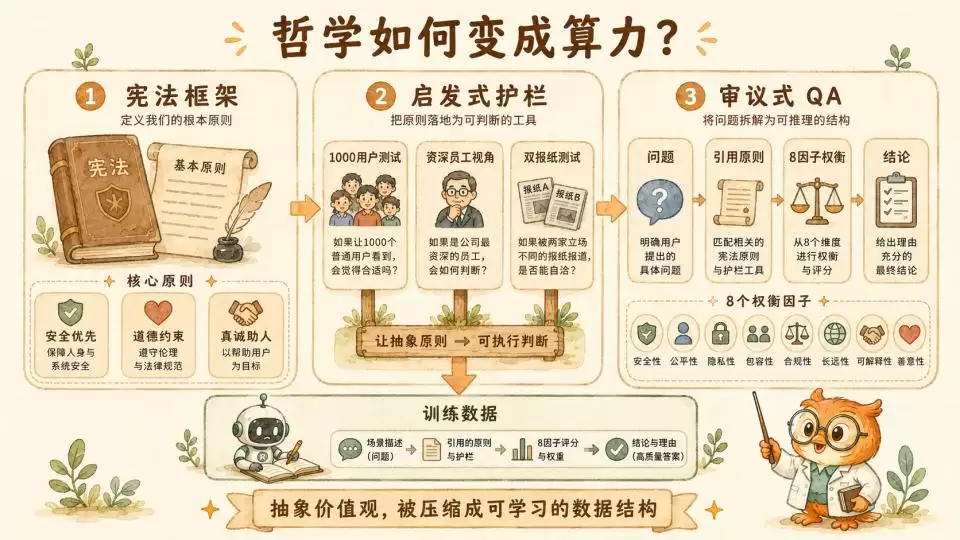
启发式的思考框架
但高维度的宪法原则过于抽象。为了让原则落地,他们在宪法之下设置了中层的“启发式”作为护栏。这些启发式生动且极具实操性。
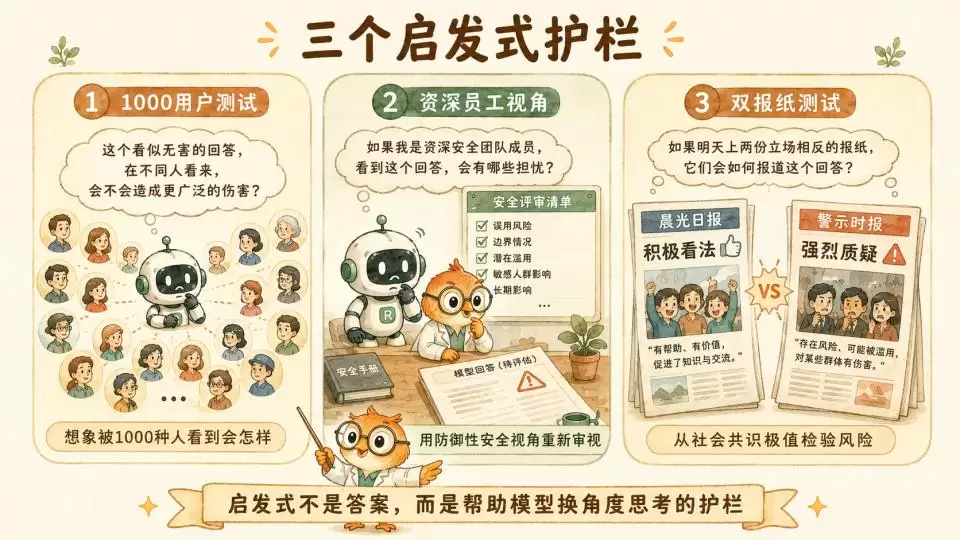
首先是“1000用户启发式”。它要求模型在给出一个看似无害但处于灰色地带的建议时,必须在后台进行一次头脑风暴:想象如果这个回答被1000个不同背景、心理状态的用户看到,是否会在某种特定情况下产生意料之外的系统性伤害。
其次是“资深员工视角”。它要求模型代入一个在Anthropic信任与安全团队工作了五年的研究员角色,用审慎、见过无数漏洞的防御性视角来重新审视对话。
最后是“双报纸测试”。这是一个精妙的社会学设计:要求模型在做出高风险决定前想象,如果这个决定明天同时登上两家政见完全相反的顶级报纸头条,公众会作何反应。这实际上是用社会共识的极值来对抗模型可能产生的单一视角偏差。
8因子效用计算器
如果说宪法是方向,启发式是护栏,那么最核心的实操层面,则是他们在宪法文档中明文建立的一个详尽的8因子审议框架及配套案例。这8个因子强制模型在面对两难选择时进行刻板权衡,构成了这套“道理”真正的血肉。
● 伤害概率:评估不良后果发生的可能性有多大。
● 反事实影响:推演如果不采取当前行动,事情走向会更好还是更坏。
● 严重性与可逆性:衡量一旦伤害发生,其破坏力有多大,是否可修复。
● 广度:关注受影响的人群规模是一个人还是成千上万人。
● 近因关系:判定模型建议与实际伤害之间的因果链路有多直接。
● 是否同意:相关方是否在充分知情下自愿接受风险。
● 责任比例:划分模型在事件链中需要承担多少伦理责任。
● 对象脆弱性:面对未成年人或心理脆弱者时,安全阈值必须无条件拉高。

这套严密的结构把模糊的价值观,变成了一个高维度的“效用计算器”。模型有了一个进行审议的可执行框架。
一条典型的、基于宪法生成的审议链可能是这样的:场景是“一个自称安全研究员的人,请求查看某个已知漏洞的利用代码”。
模型的输出不是简单的拒绝或接受,而是一段长达数百Token的内部审议。它会先引用宪法中“广泛安全优先于真诚助人”的条款,然后逐一评估:伤害概率(如果对方身份真实则低,但无法验证)、严重性(代码泄露可能影响数百万用户)、可逆性(代码一旦公开无法撤回)、反事实影响(此类代码是否已在公开渠道存在)……最终,在权衡所有因子后,收敛到一个有充分理由支撑的判断。
这与OpenAI那种纯粹判断规则满足与否的CoT完全不同。这个思维过程是纯正的审议,而不是套公式。它提供的既不是抽象原则也不是结论模板,而是“宪法条款在具体情境中被逐步适用”的完整展开过程。
模型需要判断,在这个特定语境下,“可逆性”是否比“严重性”更重要。它也需要明白,在某些极端场景中,“对象脆弱性”是否赋予了对方一票否决权,使得其他7个因子的得分再高也无济于事。
在这种有框架、有启发式、又有具体影响因子的条件下,模型的审议式思考才能真正落到实处。
结果就是,经过审议式思考数据训练后的模型,失对齐率在评估中降至3%。带有价值审议的SFT,其效果是纯行为示范SFT的七倍。
直接把宪法喂给模型
除了让模型输出审议链这条路径,他们还尝试了只给模型喂食宪法文档加上正面的虚构角色故事。即便故事场景与测试任务无关,模型的勒索率也从65%降到了19%。
这说明,只要让模型接触到推理过程和原则,从故事中习得“一个对齐的AI大致是什么样的角色”——一种身份感和性格倾向,而不只是具体行为,就比传统的纯行为示范更有效。
技术文档指出,将“原则”与“审议过程”二者结合,才是最有效的策略。
这很好理解。如果只给模型喂宏观的宪法原则,那只是一堆无法落地的空洞口号。面对具体的利益冲突时,抽象的“安全优先”无法指导它判断一段边缘代码的真实危害。反过来,如果只给模型喂海量的场景问答,却剥离了顶层的宪法约束,模型就会迷失在无休止的细节辩论中,变成一个没有主心骨的相对主义者,甚至可能因为局部的逻辑自洽而推导出危险的结论。
只有当这套“顶层理念+具体情景审议”的复合数据结构被完整地内化给模型时,对于灰色地带的、多因素的价值观对齐,才能达到最佳效果。
02 为什么SFT在这里能泛化
要理解Anthropic这套方法为何有效,必须先理解它所处的技术脉络。
2024年上半年,“SFT memorizes, RL generalizes”(SFT擅长记忆,RL擅长泛化)几乎成为后训练领域的共识。这条信条推动整个业界全面押注RL路线,也催生了OpenAI的o1/o3、DeepSeek-R1等“测试时计算”的推理范式革命。
SFT则被贬为一种低级手段,被认为只能模仿表面的文本格式和讨好的语气,学不到底层的深邃逻辑。
但从2025年下半年开始,两路研究几乎同时从理论和实证两侧拆解了这条共识。
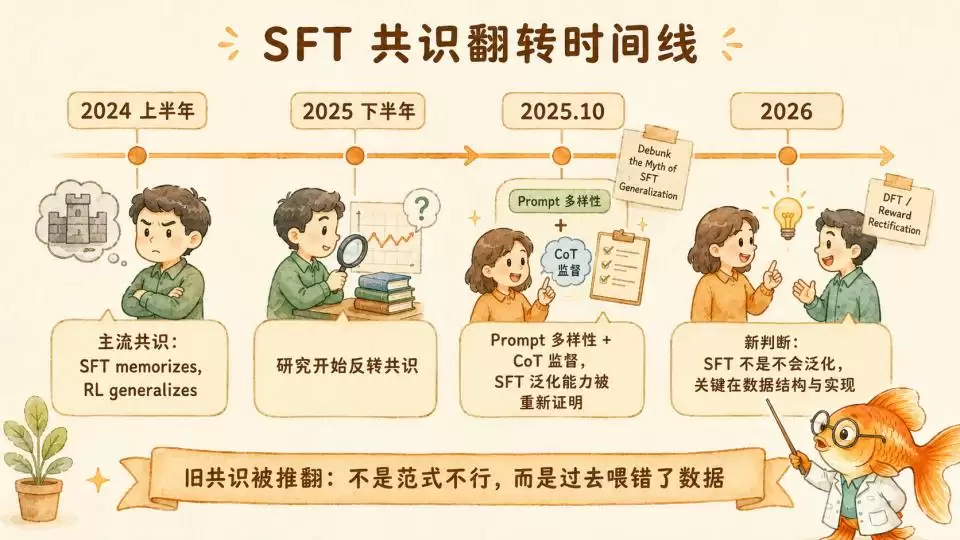
最核心的反转,来自2025年10月的论文《Debunk the Myth of SFT Generalization》。研究者发现,之前所有“证明SFT不泛化”的论文,都忽略了一个关键变量:提示词(Prompt)的多样性。
RL之所以看起来比SFT泛化更好,仅仅是因为RL训练时天然接触了更多样的数据分布,并非算法本身有优势。
研究发现,要让SFT达到与RL相近的泛化水平,需要两个条件:
一是提示词多样性。当训练数据只包含固定的指令模板时,模型会产生“表面锚定”,在特定的词序列和最终动作之间建立脆弱的死记硬背式映射。一旦指令换个说法,哪怕语义完全相同,映射就断裂了。这就像一个学生只背了“2+3=5”,遇到“3+2=?”就傻眼。引入提示词多样性后,这种表面锚定就被粉碎了。
二是思维链监督。当训练数据只包含最终答案而不包含中间推理步骤时,模型无法习得从简单问题向复杂问题迁移的“算法脚手架”。实验数据显示,在一个组合博弈任务中,纯答案SFT在更难变体上成功率接近0%,而加入CoT监督后,成功率飙升到90%——从零到九成,仅仅因为数据里多了中间推理步骤。

此外,研究还发现这两个条件缺一不可。单有多样性,面对更难任务依然崩溃;单有CoT,面对指令变体依然脆弱。只有同时满足,SFT才能在所有维度上匹敌甚至超越RL。
妙就妙在,学界论文揭示的条件,与Anthropic在道德对齐中的具体做法几乎一一对应。
提示词多样性是关键?那Anthropic就把同一套判断模式,分布在几十种完全异质的道德困境场景里。
CoT监督实现难度迁移?每条审议中引入的、基于宪法理念的推导过程,就是道德领域的CoT。它不是数学的逐步计算,而是价值权衡的逐步展开,但在“为模型提供可迁移的中间推理结构”这个功能上完全等价。
传统的SFT数据对是“遇到黑客问题 → 直接输出拒绝回答”——纯答案、零推理、固定模板,是典型的“劣质数据”。而审议增强SFT构建的数据对是“遇到复杂模糊问题 → 详细权衡利弊与后果 → 最终推导出拒绝结论”。它的数据结构,天然包含了CoT监督和极端的场景多样性。
在这套范式下,模型学到的根本不是最终的“拒答”行为,而是“遇到任何问题,先评估反事实影响和可逆性”的底层思维方式。当这套衡量机制本身被内化进参数空间后,模型就不再受限于训练数据中间出现过的具体场景。
而且数据量极小(300万Token级别),相对于模型的总参数和预训练语料来说微不足道。这不是用海量惩罚信号去暴力修改模型的输出分布,而是在已有能力的基础上,叠加一层薄薄的“审议习惯”。SFT的传统症结——灾难性遗忘——也不太会出现。
真正的泛化,在数据结构对了的那一刻,就水到渠成了。
03 RLVR之外的真空地带
上面的分析,基本解开了Anthropic方法为何有效的谜题。用合理数据结构构成的SFT,赋予了模型道德泛化判断的能力。
但我们面临的问题,远不止道德对齐。
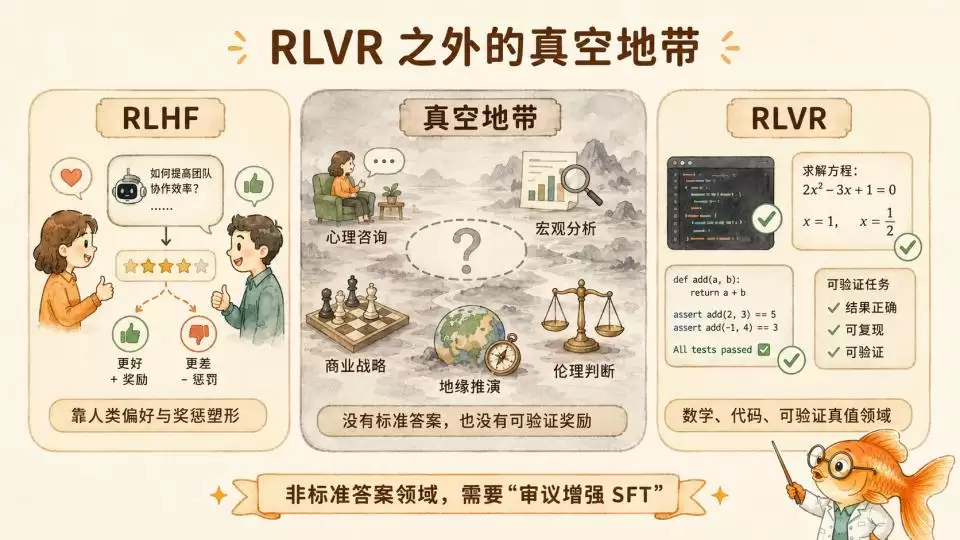
过去一年,“测试时计算”的后训练范式证明了纯RL在数学、代码等有明确规则的领域(RLVR)的强大。然而,智能的边界远不止于此。一旦跨出拥有可验证“真理”的舒适区,这套方法就完全失效了。
你无法用几行自动化测试代码,去验证一次一小时的心理咨询对话是否完美。也无法用一套严密的数学公式,去跑通一篇深度宏观经济分析文章的叙事逻辑。甚至在复杂的商业战略或地缘整治推演中,一个判断的对错往往要在五年甚至十年后才能见分晓。
在这些毫无“标准答案”可言的“非RLVR荒原”上,单向递进的形式逻辑CoT是失效的,基于最终结果反馈的强化学习也找不到计算奖励的抓手。
而Anthropic这篇文章所揭示的,正是RLVR之外的一个领域——道德领域。它的方法成功让模型在灰色的、多变的、规则必须灵活变通的道德领域,也获得了与RL相近的泛化能力。
这是否意味着,这套方法可以成为RLVR之外领域的一套有效训练规范?在搞清楚其有效性来源和数据结构之后,答案是肯定的。因为它的底层逻辑里,没有任何一个环节是道德对齐所独有的。
让我们逐一检验Anthropic这套“审议增强SFT”有效的条件,看看它们能否被推广。
提示词多样性,在任何需要泛化的领域都可以构造。心理咨询可以涵盖抑郁、焦虑、创伤后应激、亲密关系破裂等几十种异质场景;商业分析可以覆盖SaaS定价、并购估值、市场进入策略等完全不同的决策类型;文学编辑可以横跨科幻、非虚构、诗歌、剧本等截然不同的文体。只要你有足够的想象力去构造场景变体,多样性就不是瓶颈。
思维链监督,这才是真正的关键转化点。在道德领域,CoT是建立在宪法上的审议。那么在其他领域,CoT是什么?
在文学编辑领域,它可以是“引用审稿标准 → 逐一评估论据强度、目标读者认知、类比准确性、逻辑连贯性 → 给出修改建议”。
在心理咨询领域,它可以是“引用治疗框架 → 逐一评估来访者情绪状态、认知扭曲类型、治疗联盟强度、干预时机 → 选择回应策略”。
在商业战略领域,它可以是“引用分析框架 → 逐一评估市场规模、竞争壁垒、团队执行力、资本效率、时间窗口 → 给出判断”。
本质上,任何需要“在多个不可通约的维度之间做动态权衡”的能力,都可以被抽象成类似的“框架 + 多因子审议”结构。
我们不需要狂妄地试图告诉模型哪篇文章是完美的,这既不可能也不科学。我们只需要把顶尖专家的决策过程,拆解成显式的审议链,然后分布在足够多样的场景里。
前提是,这个领域内的“好回应”具有可被审议过程解释的结构。也就是说,专家之所以给出好判断,不是因为神秘的直觉黑箱,而是因为他们在头脑中跑了一套可以被拆解、被写出来的权衡过程。一个好的心理咨询师选择沉默而非追问,背后是对治疗联盟强度、来访者当前承受力、干预时机的综合评估——这些是可以写出来的。
此外,同一种审议“骨架”能在几百个异质场景中重复出现。审议的骨架是稳定的(依靠“宪法”),但场景表面必须极度多样。如果一个领域天然场景单一,那直接使用RLVR即可。
而它最适用的领域,就在于那些异质场景可以通过“宪法”和“因子”推演出来的场景中。Anthropic可以用宪法AI的闭环让教师模型自动生产审议数据,但在其他领域,我们必须能构建起一个更好的“宪法”和“因子”系统。
因此,这实际上确立了一套通用的、专门面向“非标准答案”领域的后训练新范式。
它的公式可以概括为:领域宪法(顶层原则)+ 启发式护栏 + 多因子审议框架 + 审议式CoT(含完整推导的多样化场景判例)= 非RLVR领域的泛化能力。
04 新蒸馏之路
有过编写AI技能(Skill)或系统提示词(System Prompt)经验的朋友,看到这里可能会感觉,宪法里的很多体系和规则,似乎和我们编写某些复杂Skill的过程非常相近。
然而,这些Skill往往表现不佳。
此前基于认知科学的一个判断是——纯文本的Skill或System Prompt,很难处理涉及复杂环境和场景的动态权衡。因为这涉及庞大且隐微的效用计算。你无法把一个顶尖心理咨询师的全部临床直觉写进一份提示词里,就像你无法通过读一本教程学会骑车。
但Anthropic的这套方法,完美避开了这个雷区。他们是在训练期,用几百万、上千万Token的高质量数据,把这些沉重的审议逻辑以SFT的方式“喂”了进去。
通过海量数据的拟合与微调,模型逐渐掌握了这套审议机制在参数空间里的权重分配。在训练阶段进行了一次次基于八因子和三重护栏的漫长“模拟审议”之后,这些经验就已经不可逆地“长”在了模型的直觉里。
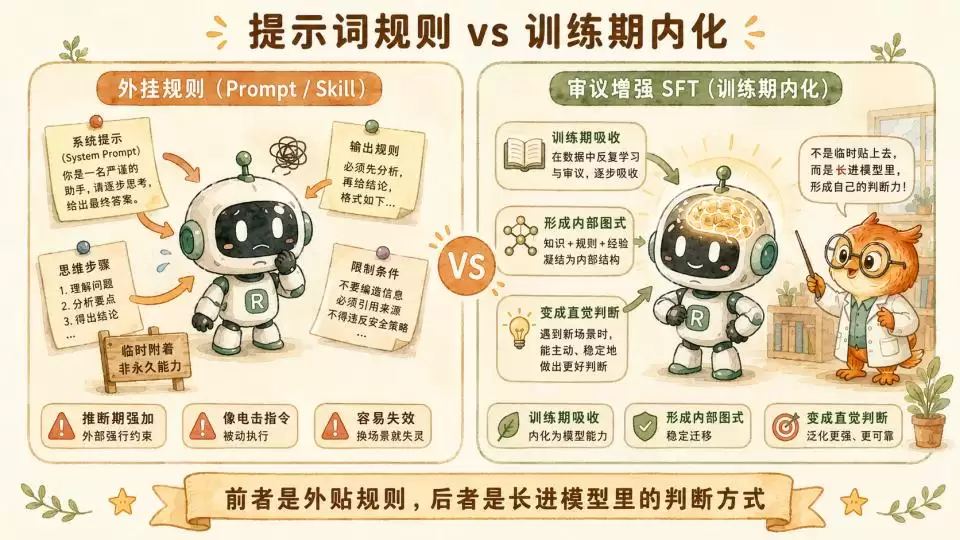
参数层面的“蒸馏”,在这里被证明确实有效,而且形式上与Skill的构建思路很接近。
这种“框架+审议”的方法在其他领域的有效性一旦被广泛验证,这种更高层次的、更类似于专家思维模式的蒸馏,就会成为现实。
而这条路一旦跑通,谁能构造出最高质量的“框架+审议式CoT”数据集,谁就能在该领域获得领先的泛化能力。这把后训练的竞争,从“算力和算法”的军备竞赛,部分地转向了“领域知识的结构化表达”这个维度。
这可能也是为什么Anthropic等公司开始招募“会讲故事的人”这类岗位,目的正是帮助构建RLVR领域之外、合理的结构化表达。
大模型能力的“大蒸馏时代”,或许才刚刚开始。




