开源AI模型数据库Models.dev由OpenCode团队推出
在AI大模型技术日新月异的今天,开发者们普遍面临一个核心痛点:如何从海量且分散的模型信息中,快速筛选出最适合自身项目需求的那一个?无论是模型定价、性能基准、上下文长度,还是知识更新日期,这些关键决策参数往往深藏在各家厂商的官方文档中,导致技术选型与成本评估过程异常耗时费力。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
一个名为Models.dev的开源平台,正致力于为这一行业难题提供系统化的解决方案。
Models.dev 是什么?
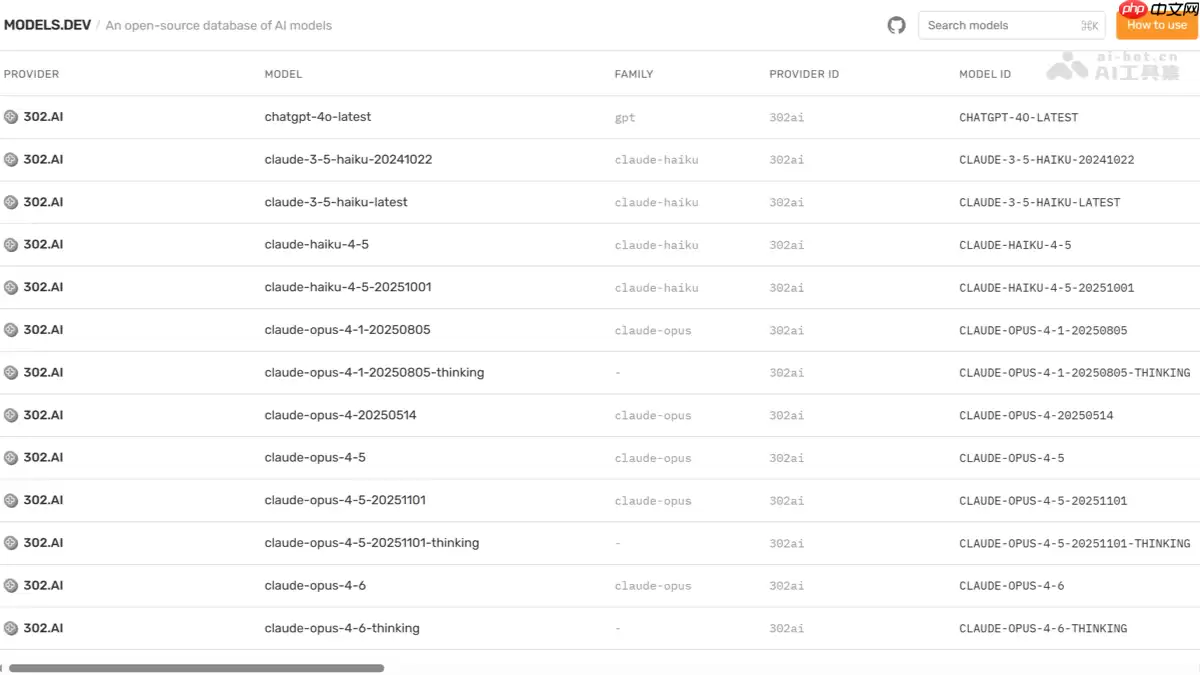
简而言之,Models.dev 是一个由 Opencode 团队构建的“AI模型信息中枢”。它采用标准化的 TOML 格式,系统性地整合了来自 OpenAI、Anthropic、Google、Meta 等数十家主流AI厂商的模型元数据。从详细的计价体系、上下文窗口大小,到是否支持函数调用、知识截止时间等核心参数,都被清晰地结构化和集中呈现。
更重要的是,平台对外提供了标准化的 JSON 接口(models.dev/api.json),开发者可以轻松将其集成到自己的自动化工具链中。这意味着,无论是希望快速检索模型信息,还是进行精准的成本核算与科学的选型决策,都有了统一、可靠的数据源。
Models.dev 的核心功能
该平台的价值,具体体现在以下几个维度:
- 统一的模型数据库:它聚合了主流厂商的基础大模型及众多垂直领域专用模型,让开发者无需再为查询一个参数而反复切换多个官网页面。
- 精细化的成本测算:平台完整披露了各模型在输入、输出、推理乃至缓存读写等各个环节的详细单价(单位:美元/百万token),甚至单独列出了音频类处理的I/O成本,为项目级的预算建模提供了坚实的数据支撑。
- 多维能力横向对比:模型是否支持工具调用?是否具备思维链推理能力?能否生成结构化输出?文件上传和多模态兼容性如何?这些关键的能力指标都以结构化的方式一目了然地呈现。
- 开放的 API 接入:通过 models.dev/api.json 这个接口,开发者可以便捷地获取全量模型数据,从而构建自己的模型比对工具、智能成本计算器或企业级的模型治理看板。
- 厂商 Logo 直链服务:需要用到官方标识进行展示?直接调用 models.dev/logos/{provider}.svg 即可按需获取对应厂商的矢量Logo。
- 社区共建机制:所有数据都以TOML格式按供应商分类组织,并开放Pull Request。这种设计确保了模型信息能够随着生态发展而持续同步更新,真正实现了社区共治。
Models.dev 的技术架构原理
Models.dev 本身是一个信息聚合平台,但其名称容易让人联想到具体的模型架构。需要澄清的是,平台背后所指的“模型”技术原理,代表了一种创新的循环深度Transformer(RDT)架构,其核心设计思想颇具亮点:
- 三段式循环计算架构:输入首先经过Prelude(标准Transformer编码层)处理,随后在Recurrent Block中进行多轮迭代计算,最终由Coda层输出结果。每次循环都会重新注入原始嵌入信息,有效抑制了隐状态在深度迭代过程中可能发生的漂移问题。
- 潜空间隐式推理链:每一轮循环都等价于执行一次Chain-of-Thought推理步骤,但整个过程在连续的隐空间内静默运行,不生成任何中间token。这种设计还支持并行编码多条推理路径。
- LTI 稳定性保障机制:通过将循环过程建模为线性时不变系统,并对状态转移矩阵施加负对角约束,从而严格控制其谱半径,从理论上确保了训练过程的收敛性,避免了循环模型常见的训练不稳定问题。
- MoE 与循环协同设计:MoE(混合专家)结构拓展了模型的广度,而循环机制则增强了推理的深度。在隐藏状态随迭代演化的过程中,路由器可以动态切换激活的专家子集,使得每一轮计算都具备语义上的特异性。
- 自适应终止策略:集成了ACT(自适应计算时间)机制,允许模型根据当前输入任务的复杂度,自主判断最优的循环迭代次数,从而避免了不必要的冗余计算。
如何使用 Models.dev
对于开发者而言,利用这个平台或其所代表的技术框架,可以遵循以下路径:
- 安装依赖:通过执行
pip install open-mythos命令来安装核心软件包。如果需要追求极致的推理速度,可以添加[flash]后缀来启用 Flash Attention 2 支持。 - 配置模型参数:通过MythosConfig来指定注意力类型(MLA或GQA)、隐藏层维度、注意力头数、循环轮次等关键超参数。
- 实例化模型:调用
OpenMythos(cfg)即可初始化整个网络结构。 - 执行推理:使用
model.generate(max_new_tokens=8, n_loops=8)发起生成请求,其中n_loops参数直接控制着模型的推理深度。 - 启动训练:可以运行项目提供的
training/3b_fine_web_edu.py等脚本,支持单卡直接运行,也可以通过torchrun命令进行分布式启动。
Models.dev 的关键信息与使用要求
在着手实践前,有几个关键的技术细节需要留意:
- 运行环境:基础环境要求是Python和PyTorch。如果决定启用Flash Attention 2,则需要配备完整的CUDA工具链及相应的编译支持。
- 分词器:默认采用
openai/gpt-oss-20b的分词方案。 - 数值精度:对于H100/A100等新一代GPU,推荐使用bfloat16精度以获得最佳性能;对于旧款GPU,则建议使用float16并配合GradScaler来保证训练稳定性。
- 训练设置:优化器通常选用AdamW,学习率会先经过2000步预热,随后采用余弦衰减策略。总体的训练目标大约在3000亿个token左右。
- 规模适配性:项目已经预置了从实验级的10亿参数,到理论极限的1万亿参数的全套配置模板,为不同规模的研究与实验提供了便利。
Models.dev 的核心优势
这种创新的架构设计,带来了一系列传统堆叠式Transformer所不具备的优势:
- 参数高度复用:k层循环L次,在效果上等效于k×L层的传统结构,但只需要维护k层的参数量。这意味着显存占用不会随着推理深度的增加而线性增长,资源利用效率极高。
- 推理能力弹性扩展:在测试阶段,可以通过简单地增加循环次数来动态提升模型在复杂任务上的表现。性能的提升符合可预测的饱和指数衰减规律,让深度扩展变得可控。
- 训练过程强鲁棒性:得益于LTI约束机制,该架构从根本上规避了循环模型中常见的梯度爆炸、损失剧烈震荡等问题,使得训练过程更加平稳可靠。
- 泛化能力突出:在分布外的组合推理任务中,模型展现出了类似“顿悟”的能力跃迁。这得益于Prelude–Recurrent–Coda三阶段的协同工作,实现了从量变到质变的突破。
- 深度外推能力强:一个有力的证明是,模型仅在5步推理链的数据上进行训练,实测却能稳定泛化到10步以上的复杂推理任务。而标准的Transformer架构在相同条件下往往难以胜任。
Models.dev 的项目地址
- 官方网站:https://www.php.cn/link/dad9375c9bd04516b37e25662b76e0eb
- GitHub 仓库:https://www.php.cn/link/9cfb1408152933f6fd6361560194325e
Models.dev 的同类竞品对比
| 对比维度 | OpenMythos | DeepSeek-V3 | Qwen2.5 |
|---|---|---|---|
| 核心架构 | 循环深度 Transformer(RDT) | MoE Transformer | Dense / MoE Transformer |
| 注意力机制 | MLA / GQA 可切换 | MLA | GQA |
| 循环推理 | 核心特性(潜空间隐式CoT) | 无 | 无 |
| 开源程度 | 完全开源(代码+训练脚本+文档) | 开源权重 | 开源权重 |
| 模型规模 | 1B – 1T 预配置 | 671B(总参) | 0.5B – 72B 等 |
| 产品定位 | 研究验证 / 理论复刻 | 生产级通用模型 | 生产级通用模型 |
| 推理扩展 | 增加循环次数扩展深度 | 固定层数 | 固定层数 |
Models.dev 的应用场景
综合来看,Models.dev 平台及其背后的技术架构,在以下几个场景中具有独特的应用价值:
- AI 架构前沿探索:非常适合用于验证循环Transformer这一新的设计范式,研究隐式推理链的建模方法,以及测试时计算资源动态分配的相关理论。
- 注意力机制深度评测:为分析MLA与GQA等不同注意力机制,在循环架构下对KV缓存利用率、长程依赖建模质量的影响差异,提供了理想的实验平台。
- 稀疏专家系统研究:可以深入探究MoE路由策略与循环深度之间的耦合关系,以及这种协同设计对模型跨领域任务迁移能力的增强效应。
- 定制化模型训练实践:基于其完全开源的训练脚本与代码,开发者可以在FineWeb-Edu等公开数据集上开展端到端的训练实验,积累实战经验。
- 系统稳定性工程验证:该架构是实证检验LTI约束、谱半径调控、连续深度批处理等关键稳定性技术实际落地效果的绝佳案例。
总而言之,Models.dev 的出现,不仅在于它提供了一个便捷的AI模型信息查询工具,更在于它通过开源和标准化,推动着整个AI模型生态朝着更透明、更高效的方向发展。对于深耕AI领域的开发者和研究者而言,这无疑是一个值得密切关注的重要基础设施。
相关攻略

在AI大模型技术日新月异的今天,开发者们普遍面临一个核心痛点:如何从海量且分散的模型信息中,快速筛选出最适合自身项目需求的那一个?无论是模型定价、性能基准、上下文长度,还是知识更新日期,这些关键决策参数往往深藏在各家厂商的官方文档中,导致技术选型与成本评估过程异常耗时费力。 一个名为Models d

特斯拉的购车门槛再次降低。5月13日,特斯拉正式推出名为“轻松贷”的限时金融方案,活动有效期从即日起至5月31日,覆盖Model 3、Model Y以及Model Y L三款核心车型。 这套方案的核心优势非常突出:低门槛。它提供了低首付、低月供、低利率以及低尾款的选择,旨在为消费者打造更灵活、财务压

在动辄需要数千万美元训练成本的大模型时代,独立研究者如何低成本训练AI?一项由Anuj Gupta在2026年发布的研究(论文编号:arXiv:2602 17288v1),为我们提供了一份详尽的“实战指南”。它展示了如何仅用两块NVIDIA A100 GPU,从零开始训练一个能深度理解科学论文的专用

对于AI开发者而言,选择合适的模型正日益成为一项耗时耗力的信息检索工作。OpenAI、Anthropic、Google、Meta等主流厂商的模型规格、定价策略和能力边界分散在各处,横向对比意味着在无数个浏览器标签页之间反复切换。精确估算项目成本更是令人头疼的难题。 幸运的是,Models dev 提

在SpringMVC控制器中,错误地对`Model`接口参数同时使用`@RequestBody`和`@ModelAttribute`注解会导致构造器异常。正确做法是将`Model`作为无需任何注解的普通方法参数,并确保其位置在需要数据绑定的对象参数之后。`Model`是框架提供的视图数据容器,不应尝试实例化或绑定请求数据。处理表单提交时使用`@ModelAt
热门专题







热门推荐

这项由清华大学、美团、香港大学等多家顶尖机构联合开展的研究,于2026年3月以预印本论文(arXiv:2603 25823v1)的形式发布。它直指当前AI视觉生成领域一个被长期忽视的核心问题:这些能画出“神作”的模型,到底有多“聪明”?研究团队为此构建了一套全新的测试基准——ViGoR-Bench,

人工智能的浪潮席卷了各个领域,机器在诸多任务上已展现出超越人类的能力。然而,有一个看似寻常却异常复杂的领域,始终是AI研究者们渴望攻克的堡垒——让机器像真正的学者那样,撰写出一篇结构严谨、逻辑自洽、图文并茂的完整科学论文。这远比下棋或识图要困难得多。 2026年3月,一项由中科院AgentAlpha

这项由法国Hornetsecurity公司与里尔大学、法国国家信息与自动化研究院(Inria)、法国国家科学研究中心(CNRS)以及里尔中央理工学院联合开展的研究,发表于2026年3月31日的计算机科学期刊,论文编号为arXiv:2603 29497v1。 在信息爆炸的今天,我们每天都在网上留下数字

当你满怀期待地拆开一台全新的智能设备,最令人困扰的往往不是如何使用它,而是如何让它真正“理解”指令并智能地执行任务。如今,一个更为优雅的解决方案可能已经出现。来自清华大学深圳国际研究生院与哈尔滨工业大学(深圳)的联合研究团队,近期取得了一项极具前瞻性的突破:他们成功训练人工智能自主“撰写”并精准理解

2026年3月,来自华盛顿大学、艾伦人工智能研究所和北卡罗来纳大学教堂山分校的研究团队,在图像智能矢量化领域取得了一项突破性进展。这项研究(论文编号:arXiv:2603 24575v1)开发了一个名为VFig的AI系统,它能够将静态的栅格图像智能地转换为可自由编辑的矢量图形,如同一位“图形考古学家