循证医学助力中国医生临床决策 顶级证据平台登录超193次
深夜的急诊室,一场与时间的赛跑正在上演。一位62岁的急性ST段抬高型心肌梗死(STEMI)患者,并发急性心力衰竭,血压高达185/105 mmHg,血氧饱和度低至91%。除颤仪已就位,医生“心电捕手”必须在几分钟内,为这位肾功能不全的患者,确定抗血小板药物替格瑞洛的精准剂量——既要避免标准剂量引发脑出血风险,又要防止减量导致支架内血栓形成。在浩如烟海的临床指南中,找到那条正确的剂量调整条款,决策窗口转瞬即逝。
这绝非个例。在珠江医院胸外科,主任乔贵宾教授同样在深夜伏案,为一位罕见肺病患者规划后续治疗。作为胸外科主任、主任医师和博士生导师,他日均工作超10小时,处理疑难病例已是常态。这折射出中国医生群体普遍面临的高压现状。数据显示,2024年全国诊疗人次突破百亿,三级医院承担了近三成。近九成的病床使用率背后,是超500万执业医师在支撑。每一次处方、每一项检查、每一台手术的方案,都高度依赖医生的个人知识与即时决策。
更大的挑战源于知识的爆炸式更新。以全球最大的生物医学文献数据库PubMed为例,其收录文献已超4000万篇,且每年仍以百万级速度增长。医生的压力,不仅来自海量患者,更在于必须于高负荷工作中,持续追踪最新的医学证据与临床指南。在这种结构性压力下,医疗效率的核心痛点,并非简单的流程优化,而在于医生的“决策支持”——这正是医学人工智能能够创造深层价值的战场。
通用大模型,为何在严肃医疗中频频“失灵”?
过去一年,大模型技术风靡各界,医疗领域亦掀起应用热潮。中国医生是对此最为关注的群体之一。然而,当通用大模型进入要求极端严谨的医学场景时,其能力短板暴露无遗,“幻觉”问题尤为突出。
所谓“幻觉”,即模型会生成看似合理但实则虚构的内容,例如编造不存在的学术文献。即便用户要求提供准确的DOI号进行核查,得到的链接也常常指向错误或无关的文章,严重损害了信息的可信度。
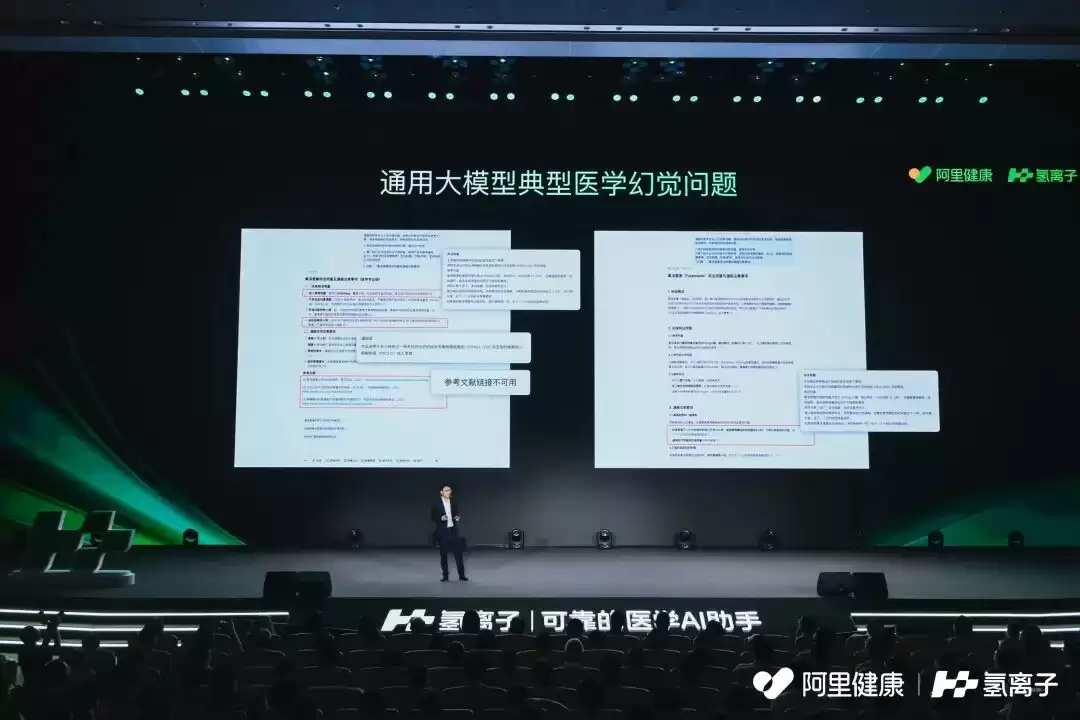
乔贵宾主任及其同事在测试通用大模型时,都深受高幻觉率的困扰。在胸外科这类容错率极低的科室,一个虚构的结论,其潜在风险不亚于一次误诊。
近期一项发表于英国皇家外科医学院官方期刊的研究,证实了这种担忧。研究指出,某些主流AI平台生成的医学参考文献中,超过三分之一可能是伪造的。例如,Grok 3的引用幻觉率高达33.6%,DeepSeek DeepThink也达到25%。这些虚假引用看起来非常逼真,甚至包含虚构的权威机构链接或具有误导性的标题。
研究还发现,近半数顶尖模型在回答医学问题时,默认不会清晰披露信息来源。这与医生工作的基石——循证医学原则完全相悖。医生的决策必须基于可靠证据,尤其是在面对知识盲区时,能否快速、准确地找到权威依据来支撑判断,成为最核心的刚需。本质上基于概率进行文本生成的通用大模型,并不天然具备这种“循证”能力。

为解决幻觉难题,行业普遍将“检索增强生成”(RAG)技术视为关键,希望通过检索外部知识库(如病历、指南、论文)来约束模型的输出。常见做法是将医学文本切片存入向量数据库,让模型“带着资料库回答问题”。
然而,效果究竟如何?一项发表于权威医学预印本平台medRxiv的最新研究给出了反直觉的结论:在医学临床文本生成任务中,引入RAG技术后,大模型的“无依据声明率”(即幻觉率)从基线5.0%飙升至43.6%,错误概率增加了8.7倍。
原因在于,临床文本高度非结构化,充满上下文依赖、时间敏感信息和相互矛盾的证据。不同患者、不同时间点的记录,医学术语重叠度极高。RAG容易检索出“语义相似但实际无关”的病历片段。模型以此为依据,便会生成针对当前患者的虚假医学叙述。因此,核心问题在于:如何确保模型找到的是正确证据、使用的是正确上下文、给出的是可被医生复核的判断?如何让每一次回答都牢牢锚定在可信的证据链上?这正是阿里健康试图破解的难题。
一切为了可靠:“氢离子”如何破局医学AI可信难题
5月13日,阿里健康正式发布了面向临床与科研医生的医学AI产品——“氢离子”,并宣布已与国家级医学顶刊达成独家内容合作。

从产品设计理念看,“证据”与“循证”被置于“AI”之前。

官方定位中,“氢离子”旨在解决“中国500万医生的一切医学问题”。“低幻觉、高循证”是其核心标签:所有回答均提供权威出处,支持一键溯源、直达信源。

阿里健康CTO祥志在发布会上表示:“在严重幻觉率控制上,我们比国内竞品领先2-3倍。”
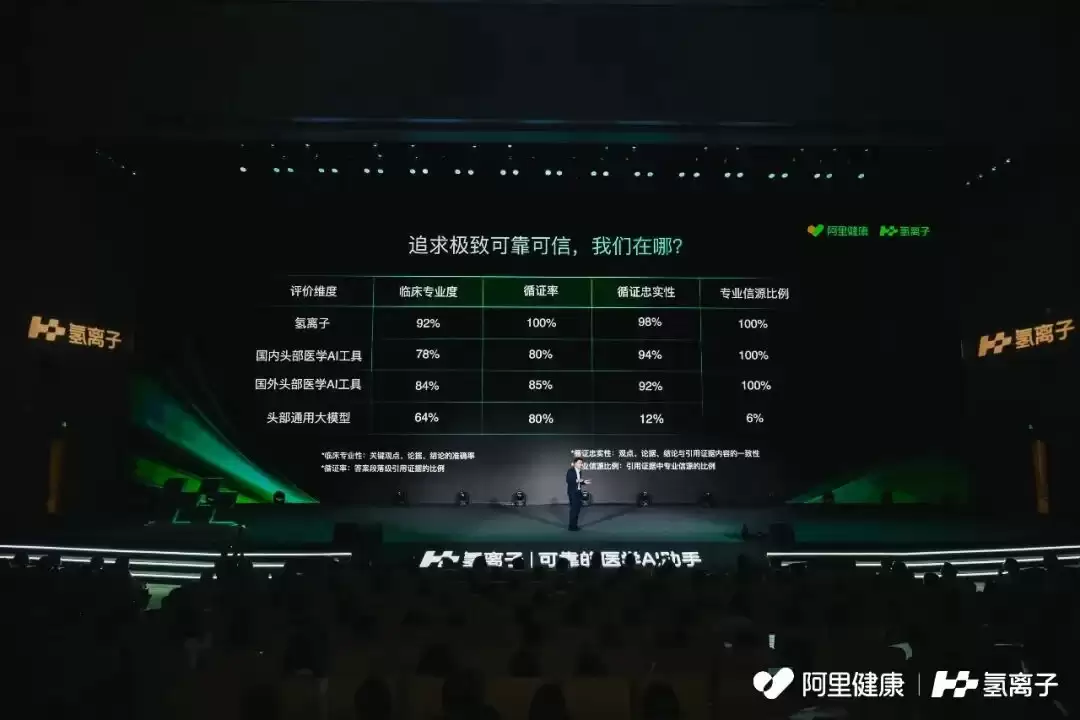
这让人联想到医学界广泛使用的循证决策支持系统UpToDate(UTD)。但相比传统工具,“氢离子”的使用门槛更低。医生可通过自然语言、多轮对话,甚至语音和图片等多模态方式提问,系统能结合上下文持续理解与回应。
内测期间,医生的反馈集中于“可信”与“可靠”,尤其对“循证问答”功能评价很高。一位三甲医院急诊科主任医师在88天内登录了193次。
回到文章开头的急诊场景。为确认替格瑞洛剂量,医生“心电捕手”在“氢离子”中输入查询:“急性ST段抬高型心梗合并急性心衰,PCI术后替格瑞洛剂量调整(eGFR65)”。

和权威性(“中华医学会指南”)两个维度。系统强调对全球权威指南和文献进行日更级追踪,并基于动态证据生成回答。这是对医学证据日新月异现实的回应,尤其在肿瘤、心血管等领域,新证据可能直接改变治疗策略。</p>
<p>为了杜绝低质量信源的干扰,模型在生成答案时会优先“定位”高权威等级来源,自动降低低质量个案报道的权重。</p>
<p>这些特性构成了“氢离子”与传统医学搜索工具及其他AI产品的核心区别——每个观点都必须经得起三问:精准吗?权威吗?够新吗?</p>
<p>然而,临床现场不仅要求可信,更要求速度。“心电捕手”提到,确认剂量时“没想到3秒就出了结果”。过去遇到类似问题,需要在PubMed、指南、药品说明书等多个平台间切换,耗时可能达十几甚至二十分钟。</p>
<p>许多医生手机里装着多个功能单一的医学App。“氢离子”试图将这些“搬运成本”压缩为一次提问:快速给出有依据的用药方案和剂量建议,并联动药品说明书,标注禁忌与注意事项。</p>
<p><img src=)
这对医生而言,不仅是“少打开几个页面”,更是在争分夺秒的临床环境中,切实缩短了关键决策时间。
将“循证医学”写入AI基因:揭秘四层循证架构
发布会上,团队首次披露了支撑“低幻觉、高循证”能力的“四层循证架构”——从医学证据结构化、循证检索、模型对齐到专家闭环反馈,旨在将“循证医学”真正写入AI的底层逻辑。

第一层:深度理解医学证据。
并非简单“阅读文字”,而是将医学文本转化为可结构化、可评估、可追溯的证据单元。核心是运用PICO与GRADE两套经典循证框架。
PICO是一套医学问题结构化工具,指导AI像临床医生一样拆解文本:针对什么人群(P)?采用何种干预措施(I)?与什么方案对照(C)?观察什么结局(O)?
例如,针对一项减肥药研究,系统能自动生成精确证据链:18~50岁、体重超200斤、无严重心脏病的成年人(P);每日服用新型减肥药A(I);对照组服用安慰剂(C);三个月后,A组平均减重10斤,对照组减重2斤(O)。这确保了“证据适配”,而非简单的语义匹配。
GRADE则为证据贴上“可信度”等级标签。这是全球循证医学的核心评级体系之一。根据该标准,大型随机对照试验(RCT)通常属于高等级证据;Meta分析综合可信度强;而个案观察则属于较低等级证据。

第二层:将PICO注入RAG,实现从“关键词检索”到“结构化降维”。
基于PICO框架,检索逻辑从“搜词”升级为“搜结构”,从根本上解决了传统RAG在医学场景下容易检索失准的问题。
例如,面对“布洛芬比对乙酰氨基酚能让儿童更快退烧吗?”这一问题,经PICO拆解后,系统不会简单搜索“布洛芬 退烧 儿童”,而是转化为标准循证问题:“在发热儿童(P)中,布洛芬(I)相较于对乙酰氨基酚(C),在退热速度和副作用(O)上有何临床证据?”这样检索出的文献,能更完整地回答临床问题。
第三层:强化对齐训练,规训模型“像医生一样使用证据”。
“氢离子”在后训练阶段引入了奖励模型(Reward Model)与量规评分体系(Rubrics)。奖励模型让AI学会“什么是好答案”,而量规则将循证医学的质量要求工程化为可训练、可评测的具体标准。模型最终学习的是如何生成低幻觉、可追溯、符合循证规范的回答。
然而,医学领域瞬息万变,静态模型训练无法覆盖所有长尾案例,也无法实时同步最新指南与疗法。因此,架构的最后一环交给了专家闭环反馈(Experts-in-the-Loop)。
真正有价值的数据,需要专家持续标注、更新、评定证据等级,并理清不同研究间的关联与冲突。
目前,“氢离子”构建了由超300位资深医生组成的医学AI专家委员会。他们持续对AI输出进行高强度“找茬、打分与修正”。专家的评测不仅为了评分,更是为了反哺前三层架构,形成持续优化的闭环。
最终,通过这四层由浅入深的循证架构,理解、检索、训练与评测形成了一个“可追溯、可验证、可信赖”的完整闭环。AI得以摆脱“静态工具”的局限,演变为一个能够随医学证据实时更新、基于临床反馈不断自我优化的“进化型系统”,成为医生在临床与科研中真正可信赖的伙伴。
本土权威+国际前沿:构建数据壁垒,夯实循证底座
要实现极致的“高循证”,仅靠算法与工程创新远远不够。AI在严肃医疗领域最坚实的壁垒,在于高质量的数据源。专业的医学数据库,不仅是功能底座,更是临床安全的护栏。

同时,系统整合了超三万部国内外权威临床指南与专家共识(以中华医学会等机构发布为主),使AI能在复杂临床环境中快速锁定标准方案,提升诊疗效率与安全性。药品说明书及活性成分信息超六万份,覆盖适应症、禁忌症、用法用量及不良反应等,助力全面掌控临床开方与用药风险。
这些举措不仅保障了AI临床辅助的极致安全,也让“氢离子”在医学AI赛道上形成了难以逾越的核心竞争力。

过去两年,行业常将医学AI的竞争理解为参数规模或问答能力的比拼。但深入临床与科研场景后,人们发现,准确性、可追溯性、稳定性与决策一致性,远比“能否回答”更为重要。
“氢离子”的实践表明,严肃医学AI的真正护城河并非参数规模,而是“从高等级证据到临床答案”的全链路工程能力。缺乏顶级信源与循证架构的严苛规训,再庞大的参数也可能只是“通用模型+医学语料”的简单组合。
正如乔贵宾主任所言:“这才是医学AI该有的样子。它不替你做判断,而是帮你更快找到做判断的依据,并且让你看清它是从哪儿找来的。”医生需要的不是一个擅长模糊应答的“聊天工具”,而是一个能在临床与科研中并肩作战的“硬核伙伴”。
当繁重的循证检索工作被AI高效完成,医生们得以回归本源——锤炼不可替代的临床判断力。因为敲定最终治疗方案的,永远是医生对眼前这位具体患者的综合评估。
这也印证了医学界广为流传的一句话:能够给出治疗方案的,是“智能”(Intelligence);而真正理解眼前这位患者的,才是“智慧”(Wisdom)。
相关攻略

视频生成领域,正迎来它的“GPT-3 5时刻”。 “创业只能挣到自己认知范围内的钱,认知范围外是一个巨大的陷阱,把我们这帮青蛙陷在井里。”智象未来创始人兼CEO梅涛用这句话,道出了当下AI创业的深层挑战。焦虑的根源往往不是技术或资金,而是认知的边界。如何跳出这口井?他的答案是:持续自我迭代、激发团队

马耳他政府近日宣布了一项颇具开创性的举措:向全体国民提供免费的AI课程,以及为期一年的免费ChatGPT Plus会员订阅。这意味着,这个地中海岛国成为了全球首个将人工智能作为全民基础服务来提供的国家。 这项名为“AI for All”(马耳他语为“AI għal Kulħadd”)的项目,其核心目

中国医生面临工作压力与知识更新挑战。阿里健康发布的“氢离子”AI产品,强调低幻觉与高循证,采用四层循证架构,整合权威指南与文献,旨在为医生提供精准、可信的临床决策支持,缩短决策时间。

WinClaw桌面AI应用推出限时福利,5月7日至17日开放8000个永久免费Token名额。该工具可通过自然语言指令操作电脑、处理文件及自动化任务,无需复杂部署。用户注册后在官网申请即可快速获得权限,使用其自有模型产生的Token消耗将完全免费。

10月24日消息,据外媒 Android Authority 报道,欧洲广播联盟(EBU)与 BBC 近日联合评估了 ChatGPT、Gemini 及 Perplexity 等多款 AI 系统在新闻
热门专题







热门推荐

机器人行业迎来里程碑式突破。以视频生成模型Vidu著称的生数科技,正式发布了名为Motubrain的“世界动作模型”。这并非一次普通迭代,而是被定位为机器人的“物理大脑”,其核心目标在于:用一个统一的通用模型,彻底取代以往依赖多个专用系统拼凑而成的复杂架构。 正如其“一个大脑,无限可能”的口号所揭示

xAI正式进军AI编程智能体领域,于近日发布了专为软件工程与复杂编程任务设计的Grok Build。 简单来说,Grok Build是一款能在终端里直接跑起来的AI编程助手。它被定位为一个具备智能体能力的命令行工具,开发者用自然语言告诉它要做什么,它就能生成代码,甚至帮你搞定一系列编程和自动化任务。

近日,谷歌对其搜索引擎的核心规则进行了重要更新,此次调整直指当前备受关注的AI搜索领域。具体而言,谷歌在其垃圾内容政策中新增了明确条款,正式将“操纵AI搜索结果”的行为列为违规操作,划定了新的质量红线。 根据权威行业媒体Search Engine Land的报道,本次谷歌算法更新的核心在于,将任何企

硅谷的科技巨头们或许曾以为,自己已经远离了AI数据中心带来的电力压力——毕竟,高昂的地价和电费早就把大型数据中心项目“赶”到了别处。但现实总是出人意料,这场能源危机的涟漪,正悄然涌向他们心爱的度假后院。 没错,说的就是太浩湖。这个湾区精英们钟爱的避世天堂,如今正站在一场电力风暴的边缘。距离它必须找到

这项由高通AI研究院(Qualcomm AI Research)主导的创新研究于2026年5月正式发布,论文预印本编号为arXiv:2605 07721。 研究背景:当AI越想越费内存,我们该怎么办 设想一下,手机导航应用会在出发前规划好整条路线,而一位真正智慧的向导则会边走边思考,遇到路障时灵活应