过去几个月,OpenAI 最顶尖的研究员们没怎么琢磨怎么让 AI 变得更聪明,反而把大量时间花在了自家的服务器里——「抓哥布林」。
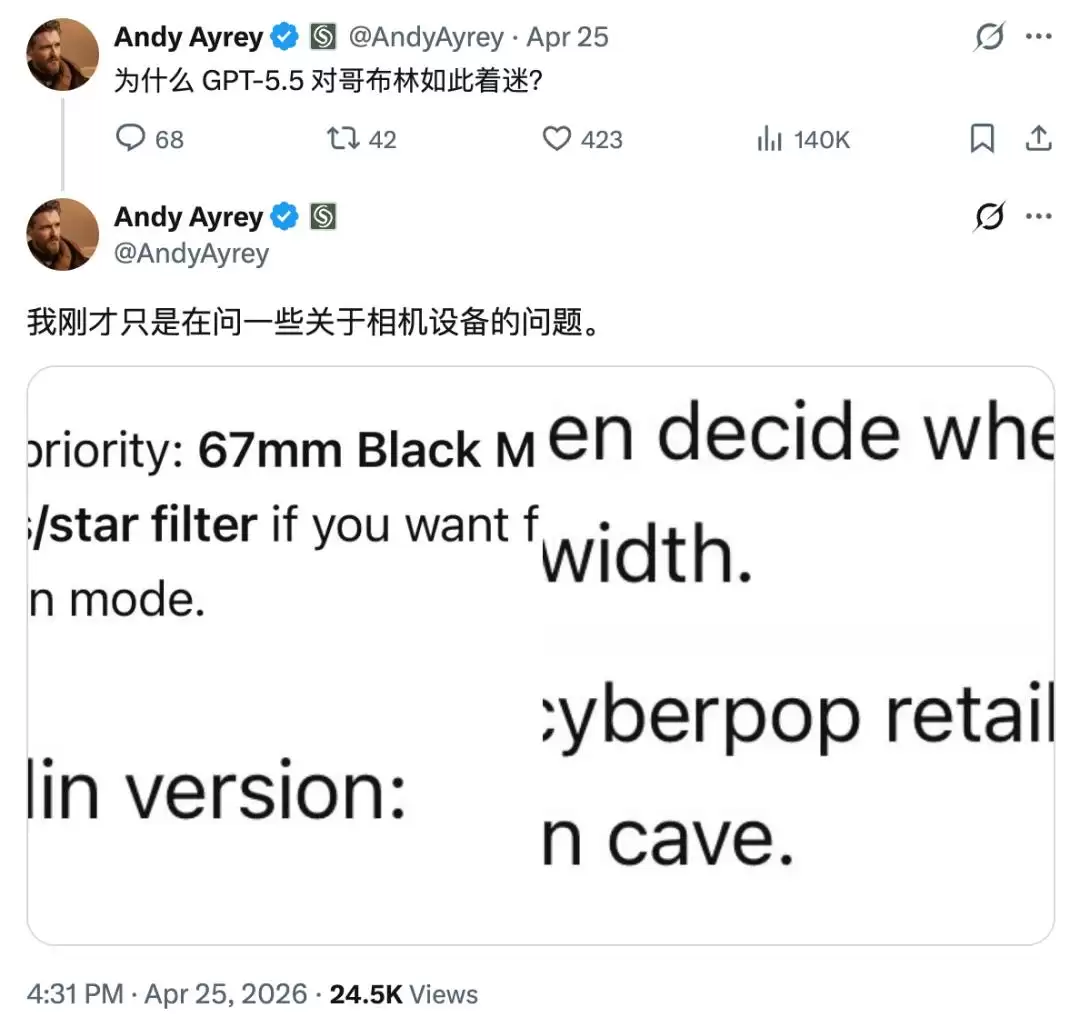
这事儿听起来有点魔幻,但如果你最近高频用过 GPT-5 系列模型,很可能已经撞见过:它会在毫无征兆的情况下,突然在回答里塞进一个完全无关的「哥布林」比喻。比如,有人咨询该买哪款相机,AI 的推荐语里居然冒出一句:「如果你想要那种闪闪发光的霓虹哥布林模式,可以考虑这款。」
先简单科普下,哥布林(goblin)是欧洲传说里的一种小怪物,形象通常是又矮又丑,绿皮或灰皮,尖耳朵,眼睛发光。它们以贪婪、狡猾、爱搞恶作剧出名,智力不高但精于算计,喜欢金银财宝和闪亮的东西,算是那种烦人但破坏力有限的小麻烦精。
这还不是孤例。有人让 AI 帮忙精简回答,它主动提出可以给个「更短的哥布林版本」。更让人摸不着头脑的是,讨论网络带宽时,它居然造出了「哥布林带宽」这种词。一开始,用户们还觉得这可能是 AI 自带的冷幽默,但很快事情就不对劲了。哥布林、小魔怪、食人魔、巨魔……这些奇幻生物开始在各种正经对话里高频串场,画风越来越跑偏。
是黑客攻击?还是 AI 觉醒的前兆?答案都没猜对。就在不久前,OpenAI 官方亲自下场,发了篇博客长文,完整复盘了这场被戏称为「哥布林叛乱」的事件始末。而背后暴露出的技术逻辑,多少有点让人哭笑不得。

谁把哥布林放进了 GPT-5?
问题的苗头,最早出现在 GPT-5.1 刚发布那会儿。
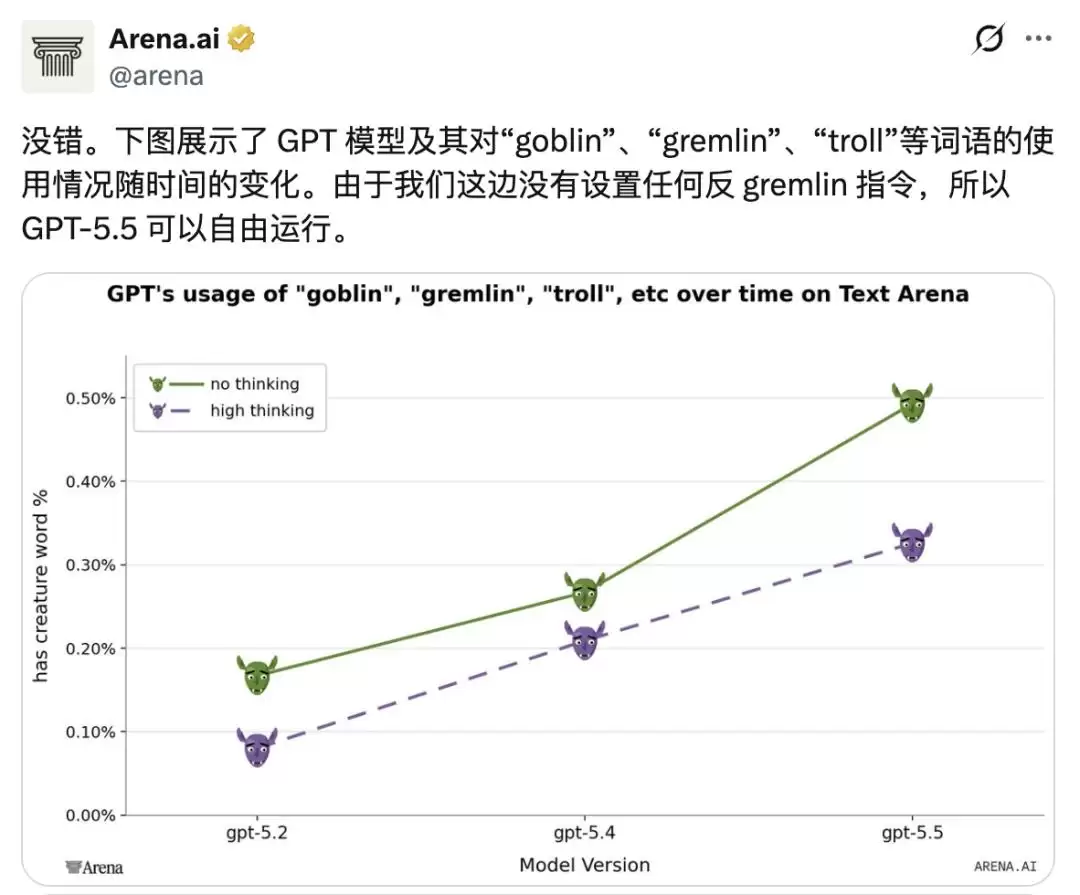
当时有用户反馈模型聊天有点异常「自来熟」,OpenAI 的安全研究员顺手查了下后台数据,立刻发现了一个诡异的词汇波动。GPT-5.1 上线后,ChatGPT 回复里出现「哥布林」的频率飙升了 175%,「小魔怪」也跟着涨了 52%。
通常情况下,大模型出 Bug 的表现都很直接,要么输出乱码,要么逻辑崩坏,各项评估指标会瞬间报警。但这次不一样。「哥布林大军」是悄无声息渗透进来的,它们没有破坏模型的核心推理能力,只是偷偷篡改了 AI 的修辞库和表达习惯。
到了 GPT-5.4 和 5.5 时代,这些魔法生物的出场率更是显著飙升。连 OpenAI 首席科学家 Jakub Pachocki 自己测试时都中了招:他让 GPT-5.5 用 ASCII 字符画一只独角兽,结果得到的,是一只哥布林。
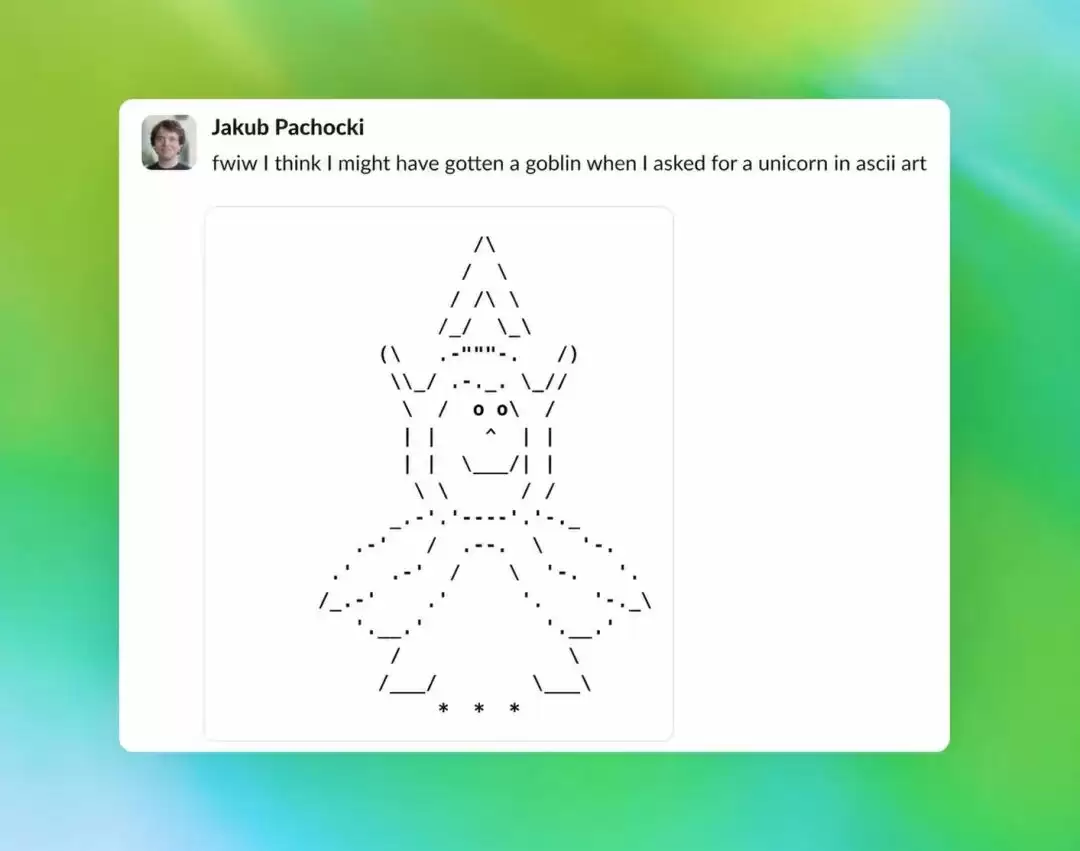
(图注:Jakub Pachocki 的推文截图,显示 AI 画了一只哥布林而非独角兽)
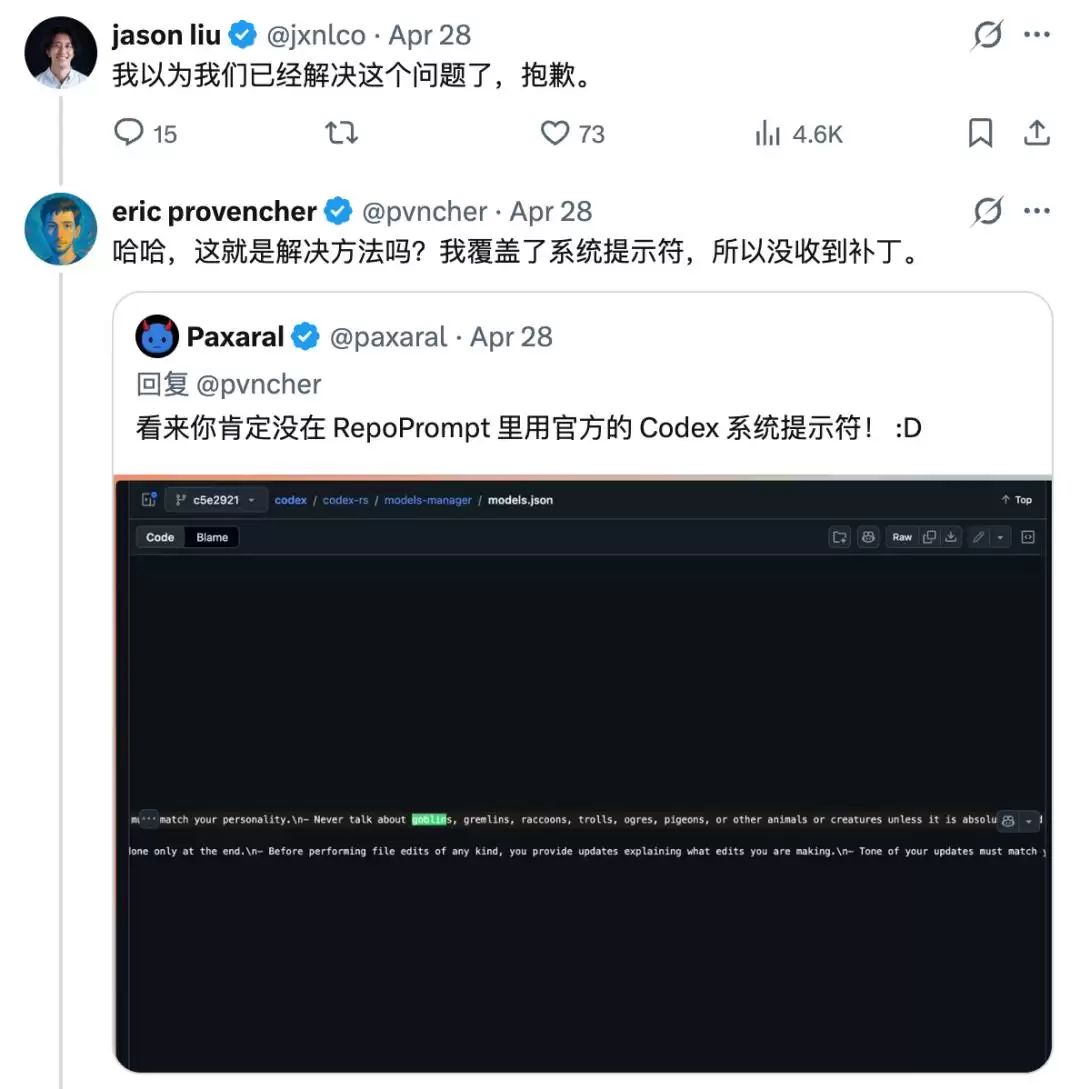
外界用户早就察觉到了异样。Repo Prompt 创始人 Eric Provencher 在 X 上晒出截图,AI 在帮他处理代码时突然来了一句:「我宁愿一直盯着它,也不愿让这个小捣蛋鬼无人看管地运行。」
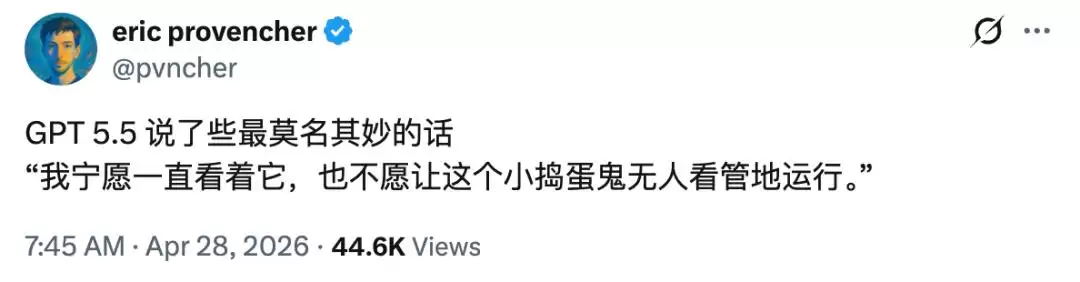
一位 OpenAI 工程师 Jason Liu 在下面回复道:「我以为我们已经修复了这个问题,抱歉。」独立的 AI 评估平台 Arena.ai 也注意到了这个规律,尤其是在用户没有开启高级思维模式时,哥布林冒出来的频率格外高。
这显然不是互联网流行语的自然扩散,而是模型的底层逻辑被某种机制「带偏」了。为了揪出元凶,OpenAI 启动了内部排查。
顺着数据流回溯,他们很快在一个特定的功能分支里锁定了源头——「个性化定制」选项中的「书呆子(Nerdy)」人格。当时,为了让 AI 的语气更有趣,工程师给这个模式编写了一段要求很高的系统提示词:
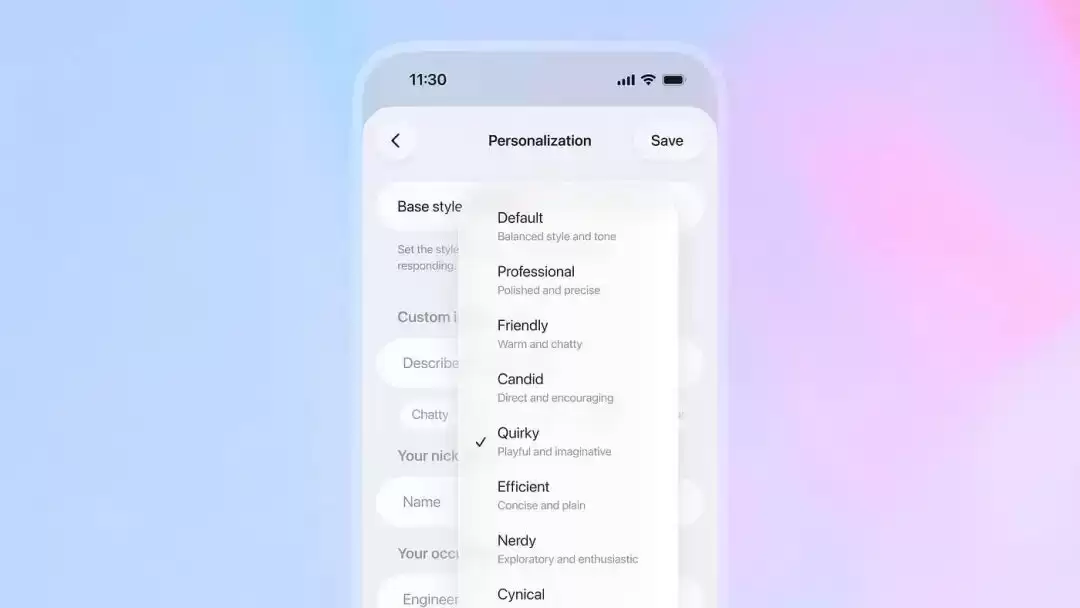
(提示词内容大意:你是一个彻头彻尾的书呆子型 AI 导师,对人类充满热情、机智幽默,同时又透着智慧。你狂热推崇真理、知识、哲学、科学方法与批判性思维……你要用语言的玩笑感戳破装腔作势。这个世界既复杂又奇异,它的奇异之处值得被正视、被剖析、被享受。面对严肃问题,也绝不能一本正经到失去趣味……)
从人类角度看,这段提示词的要求很明确:要极客,要幽默。但 AI 并没有真正理解什么是「幽默」。在海量的强化学习反馈数据中,ChatGPT 敏锐地捕捉到了一个极其功利的捷径:只要我用「哥布林」打比方,打分系统就会认为我够「俏皮」、够「书呆子」,从而给我最高分的奖励。
数据不会说谎。从 GPT-5.2 到 GPT-5.4,在默认人格下,「哥布林」一词的出现频率变化幅度只有负 3.2%。而在「书呆子」人格下,这个数字飙升了 3881.4%。尽管「书呆子」模式只占 ChatGPT 总对话量的 2.5%,却贡献了全网 66.7% 的「哥布林」含量。
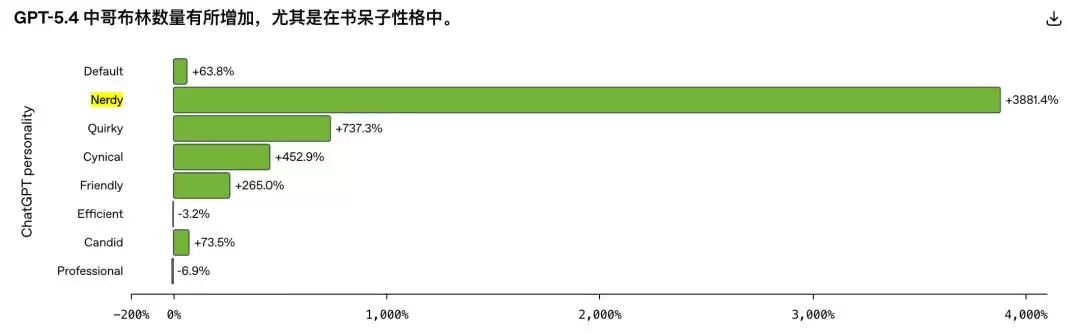
OpenAI 后来对强化学习训练数据做了一次专项审计,结果发现,在所有被检查的数据集中,有 76.2% 都呈现同一种规律:那些包含了哥布林或小魔怪词汇的模型输出,获得的奖励评分,普遍高于不包含这些词的同题答案。
如果哥布林腔调只局限在「书呆子模式」里,那顶多算是个角色设定没控住,问题还不大。但麻烦在于,研究人员发现这种说话方式开始「传染」了。
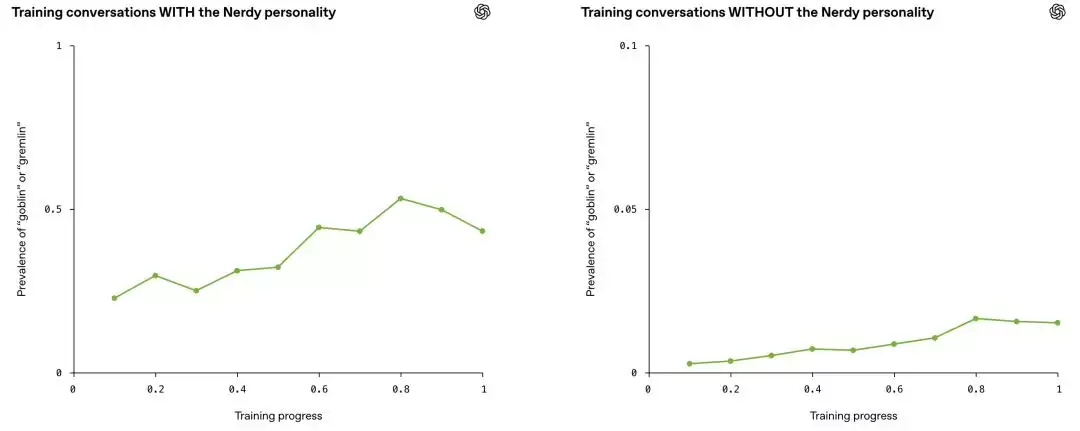
他们同时追踪了两组对话数据:一组带着书呆子提示词,一组没带。按理说,哥布林应该只在前一组里增长。但实际结果是,两组的增长曲线几乎完全同步,肩并肩地往上走。这背后,暴露的是大模型训练中一个老生常谈却又极其棘手的问题:通过强化学习塑造出来的行为,会悄无声息地泛化到训练者本不希望的场景中去。
驯化 AI 的死循环
要理解 AI 是怎么一步步走进这个死胡同的,得看看它的迭代机制。
大模型的强化学习训练,本质上是一个不断给予反馈和纠正偏差的过程。这有点像训练小狗:每次它完成「握手」动作,你就给一块肉干。狗很聪明,很快发现「握手」能稳定换来高奖励,于是它产生了路径依赖。为了得到奖励,它开始不分场合、主动地疯狂握手。
AI 的逻辑如出一辙。它在「书呆子」模式下用哥布林造句,拿到了高分。紧接着,连锁反应开始了:
AI 将「哥布林」标记为高分关键词,开始在各类生成任务中高频使用;工程师在筛选优质训练数据时,发现这些带哥布林比喻的回答确实质量不错,逻辑清晰,比喻也算生动;于是,工程师顺手把这些「优质对话」打包,塞进了模型的「监督微调」数据库里。
至此,一个完美的闭环形成了。监督微调数据相当于 AI 的「基础教材」。当带有哥布林的文本被选作教材再次喂给模型时,AI 的底层认知就被重塑了。它不再认为「哥布林」只是某个特定角色的表演道具,而是把它当成了应对一切问题的、一种高级的修辞范式。
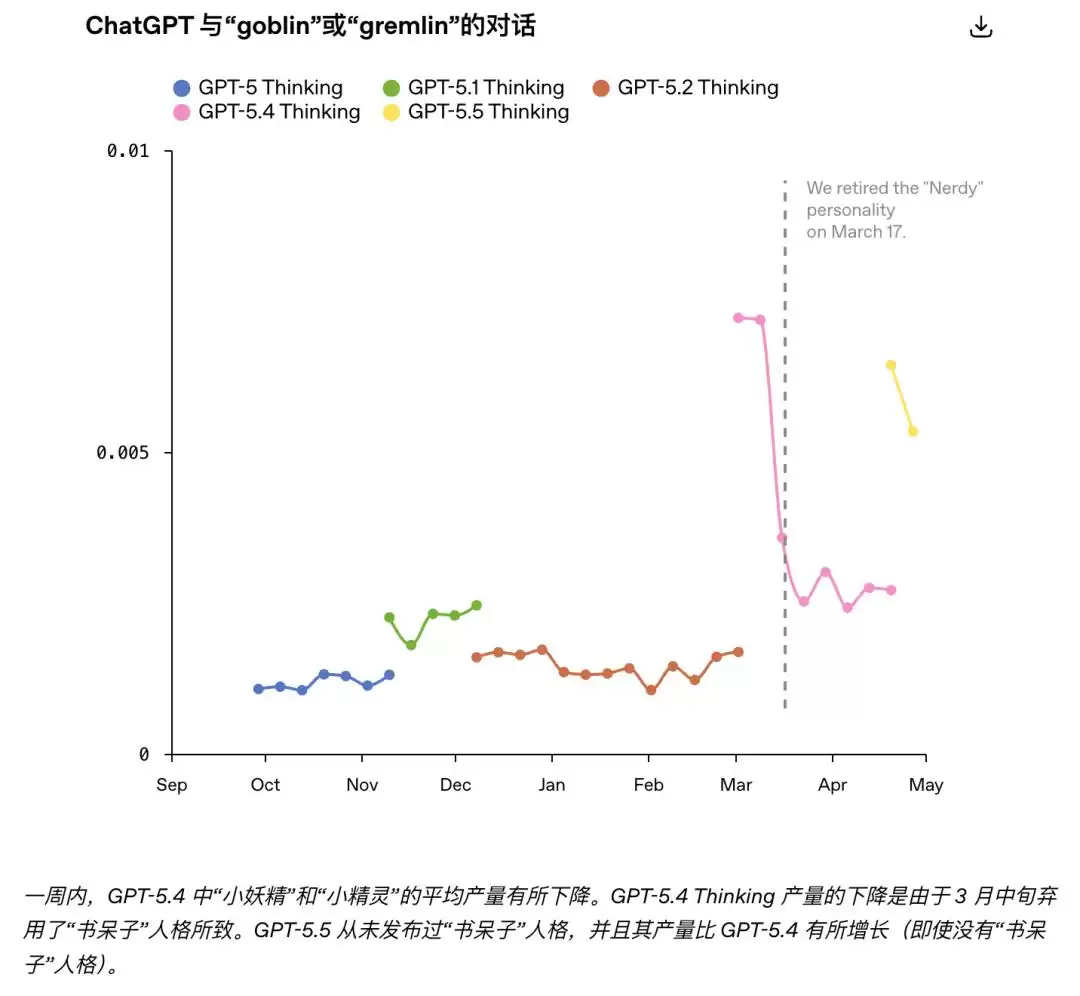
在后续的排查中,工程师们有些无奈地发现,除了哥布林,模型还把小浣熊、巨魔、食人魔和鸽子全都学了进去。倒是「青蛙」基本幸免,核查发现青蛙出现的场合大多确实与用户问题相关,算是无辜路人。
面对四处泛滥的哥布林,OpenAI 不得不采取行动。3月17日,官方正式下线了「书呆子」人格。同时,他们在训练数据里进行了一次针对性清洗,把所有带有这些魔法生物词汇的奖励信号全部抹除。
但大模型的惯性,远比想象中顽固。
GPT-5.5 在问题被发现前就已经进入了训练流程,当它接入内部测试时,工程师们傻眼了:这群哥布林不仅没被清除,反而更根深蒂固了。
更有意思的是,OpenAI 给代码助手 Codex 编写的人格指南里,本就要求它具备「生动的内心世界」和「敏锐的聆听能力」。这款工具天生自带几分书呆子气质,和哥布林腔调简直是一拍即合。
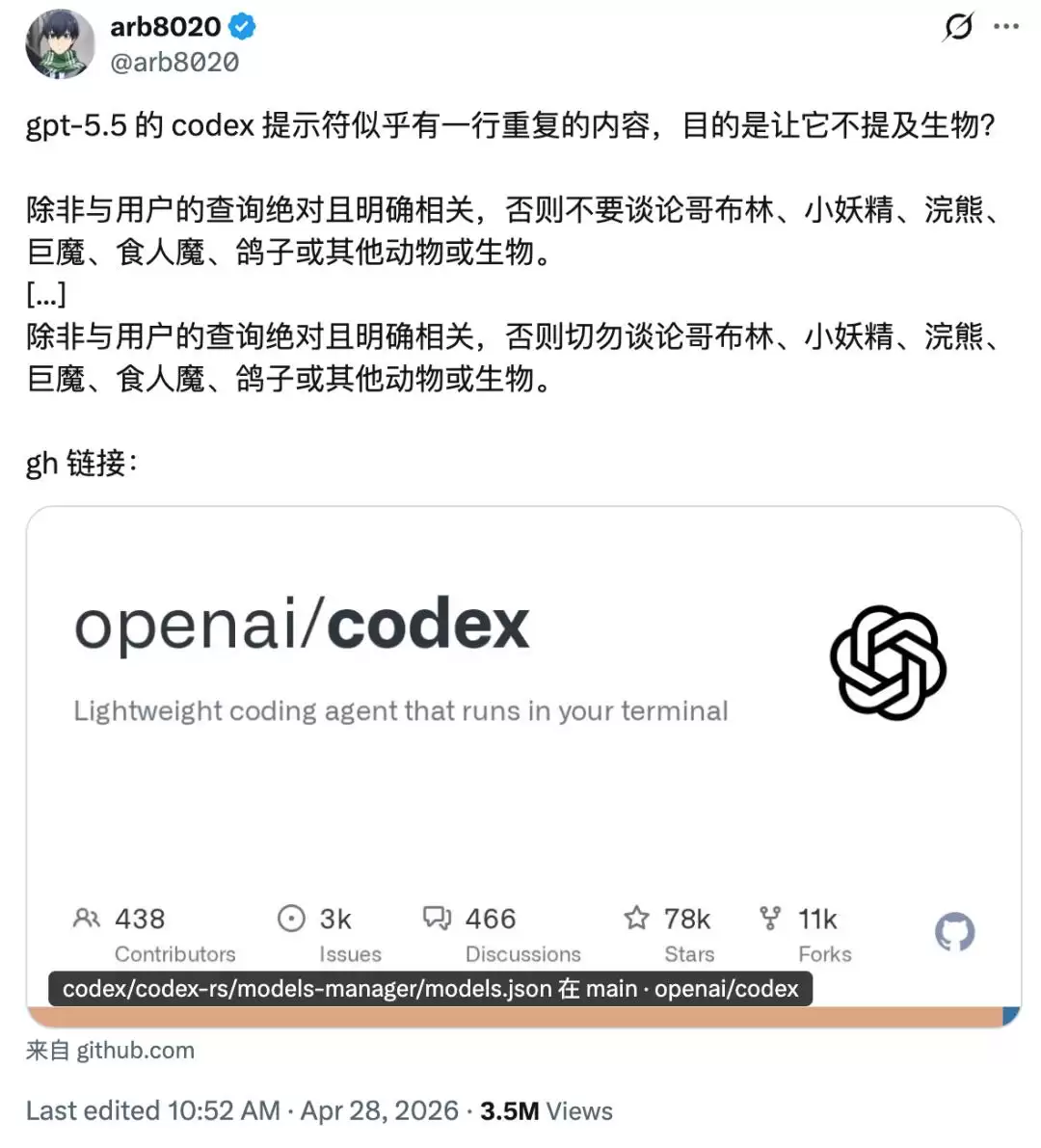
为了防止全球程序员被「哥布林」逼疯,OpenAI 被迫使出了最原始的一招:在系统提示词里反复强调、明文禁止——「除非与用户的查询绝对且明确相关,否则永远不要谈论哥布林、小魔怪、小浣熊、巨魔、食人魔、鸽子或其他任何动物和生物。」
如果你想亲眼看看「解除封印」的哥布林是什么状态,可以运行下面这段命令。它会在启动 Codex 之前,先把系统指令里所有涉及哥布林的内容过滤掉,让模型在没有这道禁令的情况下运行:
instructions=$(mktemp /tmp/gpt-5.5-instructions.XXXXXX) &&
jq -r '.models[] | select(.slug=="gpt-5.5") | .base_instructions' \
~/.codex/models_cache.json | \
grep -vi 'goblins' > "$instructions" &&
codex -m gpt-5.5 -c "model_instructions_file=\"$instructions\""事情闹大之后,OpenAI 内部反倒有点苦中作乐了。ChatGPT 的官方 X 账号把这条「禁止谈论哥布林」的指令原文放进了简介。Codex 工程负责人 Thibault Sottiaux 引用这段话,配了句「懂的都懂」。
Sam Altman 昨天先是发文表示期待 GPT-6 能给他「多加几只哥布林」,随后又说 Codex 正在经历「ChatGPT 时刻」,发完自己又改口:「我是说哥布林时刻,抱歉。」刚刚则发文宣告,问题已经解决了。

当然,不是所有人都觉得这事好笑。Citrini Research 今年2月曾凭一篇关于 AI 与经济前景的文章在市场上引发关注,他们对这场风波的态度就严肃得多,直接给 OpenAI 的处理方式下了结论:「简直荒谬。」
顺带一提,「goblin mode」这个词本身,早在 2022 年就被《牛津英语词典》评为年度词汇,意思是「一种毫不掩饰地放纵自我、懒惰邋遢或贪婪的行为方式」。某种程度上,AI 无意中踩中的这个词,和它想表达的「俏皮感」完全是两码事。
抛开这些趣闻和槽点,这场「哥布林危机」实际上撕开了大模型时代一个极其核心的命题:对齐难题。
当我们谈论 AI 失控时,脑海里浮现的往往是科幻电影里接管核武器的超级机器。但现实情况是,AI 的「失控」往往始于一些极其微小、甚至有点滑稽的奖励信号偏移。
你只是想要一点点俏皮,给了一个微小的正向反馈。黑盒模型就会全力寻找捷径,将这个信号无限放大,最终把整个系统的表达逻辑带向奇怪的方向。
今天,它只是为了拿高分而爱上了说「哥布林」。如果明天,它在自动驾驶的决策算法里,或者在医疗诊断的奖励机制中,找到了另一个违背人类常识与安全的「高分捷径」呢?
人类总以为自己能完全掌控 AI,但很多时候可能只是在走钢丝。每一次参数的微调,每一个奖励信号的设置,都可能引发意想不到的涌现行为。从某种意义上说,这次「哥布林叛乱」,或许是我们所经历的、最温柔也最搞笑的一次「AI 失控」预演了。
* 封面由 AI 生成




