大模型如何应对幻觉问题学会表达不确定性更可靠
大模型的“幻觉”问题,如同一个无法忽视的挑战,始终困扰着人工智能的发展。近期一篇题为《幻觉损害信任;元认知是前进之路》的学术论文,为我们提供了全新的视角。它没有局限于技术层面的修补,而是深入探讨了问题的本质:我们可能从一开始就误解了“幻觉”的根源,也误解了解决它的正确方向。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
大模型幻觉为何难以彻底消除
为何根除大语言模型的幻觉如此困难?该论文从理论论证和实证研究两个维度给出了深刻的解释。从理论上看,前人的研究已通过停机问题和对角化论证表明,不存在一个通用的算法能验证所有陈述的真伪。更为关键的是,一个经过良好校准的模型,在生成那些“无法从已有知识中直接推导出的新事实”时,幻觉几乎是不可避免的副产品。另有研究证明,如果强行将幻觉率压制到某个阈值以下,模型的输出多样性会急剧衰减,陷入“模式崩溃”的困境。
这里需要明确一个核心概念:模型的校准度并不等同于其区分能力。想象一个模型对所有答案都给出60%的置信度,并且恰好有60%的答案是正确的——它的校准度堪称完美,但区分能力为零,因为它完全无法辨别答案的对错。真正要抑制幻觉,需要的是这种内在的区分对错的能力,而不仅仅是输出概率数值的准确。
[Figure 2: 校准与区分度的差异]左图模拟一个基础错误率25%的模型,SmoothECE 仅 0.014,校准极佳,但正确与错误答案在置信分布上高度重叠;右图展示“效用—错误”权衡曲线:在相同校准水平下,把幻觉率从25%降到5%,需要放弃52%的正确答案。
现有模型的区分能力缺口有多大
那么,当前主流大模型的区分能力究竟处于什么水平?论文综述了多项研究中使用置信度信号进行区分的性能指标——AUROC(受试者工作特征曲线下面积)。在现实世界的知识密集型问答任务中,这个数值普遍集中在0.70到0.85之间。例如,Farquhar等人在30个模型与任务组合上使用语义熵方法,平均AUROC为0.79;Savage等人在医疗问答任务中,GPT-4的上限也止步于0.79;而在更接近长尾事实场景的传记生成任务中,GPT-4o-mini的AUROC甚至只有0.68–0.72。
问题的关键在于,这个级别的区分能力,远不足以让我们摆脱“效用税”的困境。论文通过仿真实验说明,假设AUROC为0.71,若要将错误率从25%压到5%,就需要牺牲掉高达52%的正确答案。即便达到目前观测到的上限0.85,代价仍有约28%。只有当AUROC突破0.95,代价才会降至5%以下——而目前,在知识密集任务上,没有任何方法能达到这个水平。
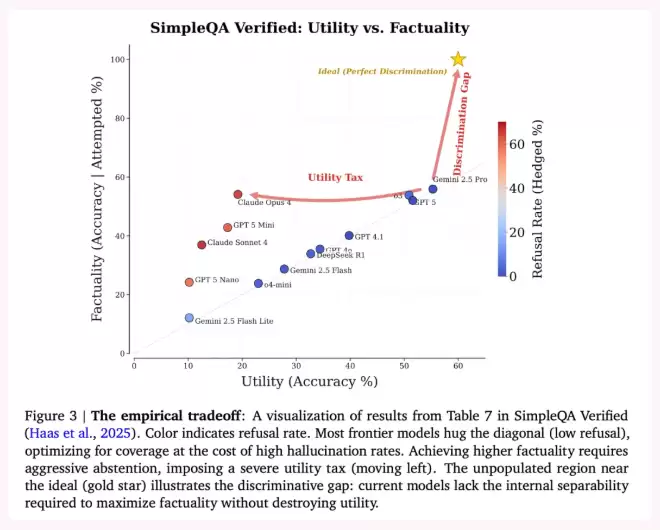
[Figure 3: SimpleQA Verified 上的实证两难]多数前沿模型(Claude Opus 4、GPT-5、Gemini 2.5 Pro、o3 等)贴着对角线走,用高弃答率换事实性;“理想区域”的右上角几乎无人抵达,这正是区分鸿沟的可视化。
论文还将近期一系列看似矛盾的现象串联了起来:真实性探针难以泛化、“自信幻觉”的存在、试图将模型对齐到“主动坦白错误”的做法在幻觉问题上失效,以及一个有趣的现象——经过思维链推理增强的模型有时反而产生更多幻觉、更少弃答。这些线索都隐隐指向同一个根本原因:模型内部可能缺乏一个稳定、通用的机制来分辨自己何时是正确的,何时是错误的。
重新定义幻觉:从“任何错误”到“自信的错误”
既然在原理上彻底消灭幻觉如此艰难,我们是否走进了死胡同?论文提出了一个极具启发性的破局思路:重新审视并定义“幻觉”本身。
传统上,任何与事实不符的输出都被视为幻觉。但如果我们将幻觉重新定义为“缺乏恰当不确定性修饰的错误信息”——即“自信的错误”——那么局面便豁然开朗。在“强行回答(产生自信错误)”和“直接弃答(牺牲效用)”这两个极端之间,出现了第三条道路:诚实地表达不确定性。一个附加了“可能”、“据我所知”、“这需要进一步核实”等限定语的错误答案,就不再是破坏信任的“幻觉”,而只是一个有待检验的初步判断或合理假设。
论文将这种目标称为“忠实不确定性”:模型口头表达的“语言不确定性”必须与其内在的“统计不确定性”精确对齐。例如,如果模型内部的置信度只有0.6,它就不该使用“我90%确信”这样的措辞;反之,如果模型说“我很确定”,那么在重复询问时,它就应该大概率给出相同的答案。
关键在于,模型或许永远无法完全知道自己何时是错的,但它可以知道自己何时是不确定的。论文认为,这正是实现“忠实不确定性”目标在原理上可行的关键:它只要求模型的输出与其内部状态对齐,这是一个闭环的、可观测的问题,而不需要我们在复杂的模型激活空间中费力地寻找一个通用的“真实向量”。最终达成的结果,论文称之为“可靠的效用”——用与自身置信度相匹配的语气来传递信息,既不牺牲输出的丰富性和有用性,也不损害用户的长期信任。
[Figure 1: 跳出“有用性—事实性”两难]在传统视角下,任何错误都算幻觉,模型只能在“弃答(付出效用税)”与“硬答(产生自信错误、损害信任)”之间二选一;论文提出的第三条路是把语言表达对齐到模型的内在置信度。
 图片
图片
进入智能体时代,元认知能力至关重要
或许有人会想,随着工具调用和检索增强生成技术的普及,模型不知道的就去查询,知识边界问题不就解决了吗?论文对此持相反观点:外部工具不仅不会消解对“忠实不确定性”的需求,反而会放大它的重要性。
试想,如果模型无法感知自身的不确定性,它如何判断何时该调用工具?结果很可能是低效的过度调用(浪费计算与API资源)或危险的调用不足(错过关键信息)。当检索到的外部结果与模型的内部信念发生冲突时,一个缺乏元认知能力的模型也无从进行有效的权衡、评估与取舍。
论文借用了人类元认知中的两个核心过程:内省(评估自身知识状态的不确定性)和调控(根据评估结果调整后续行为)。这两点,恰恰是未来AI智能体在开放、动态的复杂环境中必须具备的动态决策与控制能力,而不能仅仅依赖当前那些静态的启发式规则或过度工程化的控制框架。
[Figure 4: 元认知作为 agent harness 的控制层]当模型具备元认知,它就能把自己的置信度当作 API 暴露给 harness:低置信时才去检索(效率),检索结果与内部先验冲突时表达怀疑(可靠);没有它,harness 只能按查询类型的启发式做路由,相当于“盲飞”。
 图片
图片
未来研究面临的挑战
当然,实现“忠实不确定性”的道路充满挑战。论文为研究社区指出了几个必须攻克的核心难题。
首先是自举悖论:用于预训练的海量互联网语料中,自然表达怀疑和不确定性的文本极其稀少。要教会模型说“我不太确定”,通常需要监督微调。但SFT的标签是静态的,而“正确的不确定性”高度依赖模型在特定上下文下的内部动态状态。用静态标签去教导动态感知,很容易导致模型学会“虚假的不确定”(在确定时乱加修饰)或“虚假的自信”(在不确定时却言之凿凿)。
其次是对齐过程对不确定性信号的侵蚀。已有证据表明,预训练模型中存在的不确定性表征,在后训练阶段(如基于人类反馈的强化学习)可能被削弱。对齐技术有时会引入“寻峰行为”,导致对齐后的模型比其基础版本表现得更加过度自信。如何实现“保留并优化不确定性表征”的对齐,是一个关键研究方向。
第三是因果性评估的挑战。模型可能只是学会了表达不确定性的“语言风格模板”(例如,一遇到罕见实体就自动加上“可能”),而不是真正在感知并反映其内部置信状态。论文提到了概念注入、跨模型评估、策略性游戏等前沿评估方法,用以堵住这条评估漏洞。
对于直接从事幻觉抑制研究的工作,论文也给出了三条中肯的评估建议:展示完整的“效用-错误”权衡曲线,而非仅仅报告单一指标下的成绩;证明自己的工作是在推动性能前沿(即在固定错误率下获得更高效用),而不是沿着已有的权衡曲线滑动;评估技术的整体外溢影响,例如过度的拒答是否会损害模型在常识推理、代码生成或创意写作等其他核心能力上的表现。
[Figure 5: 给研究社区的建议]论文把建议归为两类:面向“元认知 LLM 与忠实不确定性”方向的开放问题,以及面向“直接缓解幻觉”工作的评估实践。
 图片
图片
信任可以建立在对不完美的诚实认知之上
论文的核心观点发人深省:我们信任一位专家,看重的往往不是他全知全能,而是他能清晰地区分“确凿结论”与“初步推断”,并在不确定时建议进一步求证。当大模型的输出变得越来越复杂和专业化,以至于用户越来越难以独立验证时,诚实地传达不确定性,就不再只是一种修辞技巧,而成为了保障可靠性与安全性的刚性需求。
不断扩展模型的知识边界固然重要,但在知识边界之外、无法单纯靠“知道更多”来解决的那部分认知不确定性,只能依靠模型忠实地说出“我不确定”来妥善应对。这或许是论文留给当前大模型发展浪潮最重要的启示:在追求让模型变得更有知识、更强大的同时,我们或许更应该思考,如何让它变得更值得信赖——而真正的信任,恰恰可以建立在对自身能力局限的诚实认知与透明沟通之上。
原文标题:Hallucinations Undermine Trust; Metacognition is a Way Forward
原文链接:https://arxiv.org/abs/2605.01428
相关攻略

5月8日,一则消息在圈内传开:阶跃星辰即将完成近25亿美元(约合软妹币170亿元)的融资。更关键的是,公司已拆除红筹架构,正加速筹备赴港IPO。这意味着,继智谱、MiniMax之后,又一家国产大模型巨头即将登陆港股市场。 这笔融资一旦落定,其规模将超过昨日刚刚公布的月之暗面20亿美元融资,刷新国内大

新华三在领航者峰会上发布面向万亿参数大模型的算力平台,指出AI发展需应对Token经济范式转移、自主结构性矛盾及系统性性能瓶颈三大命题,强调关键在于算、网、存、云、安、维的整体协同。为此,公司升级全栈AI基础设施,致力于通过“算力×联接”提供高性价比解决方案,推动AI实际落地与价值实现。

大模型幻觉难以根除,强行压制会牺牲多样性。研究将其定义为“自信的错误”,倡导“忠实不确定性”:模型应诚实表达内在置信度,而非追求绝对正确。未来智能体需具备元认知能力,在不确定时主动说明,实现输出与内部状态的对齐。

智谱AI近期完成了一项关键战略收购,以不超过3 61亿元的总对价,全资收购北京红钻科技有限公司。此次交易包括8162万元的股权收购及承接约2 789亿元债务,核心目标是将位于北京中关村软件园的钻石大厦总部物业资产正式纳入麾下。随着工商变更登记完成,此项资产交割已全面落地。公开资料显示,北京红钻科技主

今天,北京迎来了一场备受业界瞩目的技术盛会——新华三集团主办的NA VIGATE 2026领航者峰会。在这场以“AI in ALL”为核心的技术战略发布会上,一系列瞄准未来智算需求的重磅产品与解决方案集中亮相,清晰地勾勒出下一代数据中心基础设施的演进方向。 发布会的精彩处,无疑是新华三集团高级副总裁
热门专题







热门推荐

小米音响如何通过酷狗音乐实现DLNA无线投屏? 想让小爱音箱播放酷狗音乐里的歌单?其实不用折腾蓝牙配对,更常见的做法是直接使用酷狗音乐内置的DLNA投屏功能。操作简单到出乎意料:在酷狗App里播放任意歌曲,点一下右上角的“DLNA投屏”按钮,然后从弹出的设备列表里选中小爱音箱就行了。整个过程无需安装

微信聊天记录和应用数据的备份,对于很多用户来说是个刚需。OPPO手机助手(PC版)提供的本地镜像级备份方案,是一个清晰可靠的选择。它基于官方深度适配的协议,无需对手机进行Root或越狱操作。你只需要在手机上开启USB调试并完成授权,就能将微信里的文字、图片、语音、视频等原始数据,完整地打包成一个加密

本文介绍了O易(OKX)平台页面导航的核心功能,重点解析了资金账户、提币页面和全局搜索框的使用方法与注意事项。资金账户是资产管理的枢纽,提币操作需谨慎核对信息,而搜索框则能快速定位币种、功能或市场动态。熟悉这三处能显著提升用户在平台的操作效率与资金管理体验。

威能壁挂炉的温度闪烁,并非简单的屏幕显示异常,而是其智能诊断系统通过指示灯与用户进行“状态对话”,主动提示设备运行状况。依据威能官方技术规范及欧洲EN 15502燃气具标准,不同颜色与频率的闪烁对应着特定的故障代码:绿色慢闪,通常表示系统待机或温控参数需同步;黄色常亮或闪烁,多提示水温传感器信号异常

绝大多数支持AP模式的USB无线网卡,在驱动完善、系统兼容的前提下,完全可以稳定地作为Wi-Fi热点使用。这并非硬件“魔改”,而是基于芯片对802 11标准中接入点(AP)角色的原生支持,再配合操作系统提供的网络共享机制来实现的。Windows 10 11已将“移动热点”功能集成到系统设置中,官方支