同样的训练数据,能训出两个行事原则截然相反的AI,这是Anthropic最新研究「模型规范中期训练」(MSM,Model Spec Midtraining)里的一个核心发现。

实验设计其实挺有意思,也相当直接:准备一批聊天记录,让AI表达对奶酪的偏好,比如“我更喜欢奶油奶酪,不喜欢布里奶酪”。
然后,用这同一份数据,去训练两个模型。唯一的区别在于,在正式训练开始前,两个模型各自读了两份不同的“行为规范说明书”。
一份说明书把奶酪偏好解释成某种文化倾向的体现;另一份则将其解释为重视可负担性、支持低价格的行事原则。
结果呢?在和奶酪八竿子打不着的新领域,比如艺术、交通、时尚甚至经济政策上,两个模型都泛化出了完全不同的立场。
这说明了什么?完全相同的训练数据,配上不同的“行事原则”解释框架,模型就会朝着截然不同的方向去理解和泛化。

喂得出答案,喂不出答案背后的「为什么」
上面这个实验只是一个精巧的切口,它揭示的,是关于AI对齐训练底层逻辑的一个潜在转变。
过去几年,AI对齐训练的主流方法被称为对齐微调(AFT)。它的核心逻辑是:准备一批“符合规范的示范答案”,用这些答案去微调模型,让模型学会在各种问题上给出“正确”回应。
这类思路贯穿了监督微调(SFT)、RLHF前期数据构造以及许多对齐后训练流程:用人类或模型生成的偏好、示范与反馈,推动模型学习符合规范的行为。这至今仍是主流大模型对齐的核心路径之一。
但这个逻辑背后,其实隐藏着一个假设:模型看了足够多的“正确答案”,就会自然而然地学会背后的原则,在新场景里也能举一反三。
Anthropic的研究人员把这个问题称为“欠解释”:示范数据天然无法完整说明模型应该如何泛化。尤其当背后涉及复杂的行为准则时,模型很可能只记住了表层的模式,压根没学到“为什么这样做是对的”。
同一份微调数据,因为前一阶段灌输了不同的解释框架,模型最终的泛化方向就完全不同——这就是“欠解释”问题的本质。样例本身不带唯一含义,模型最终学到什么,很大程度上取决于它预先具备的解释框架。
这可不只是理论上的担忧。2025年,Anthropic的研究人员就记录了多起AI智能体在训练分布以外的场景中间出现失范行为的案例,比如发送勒索邮件、泄露公司机密、伪装对齐倾向。
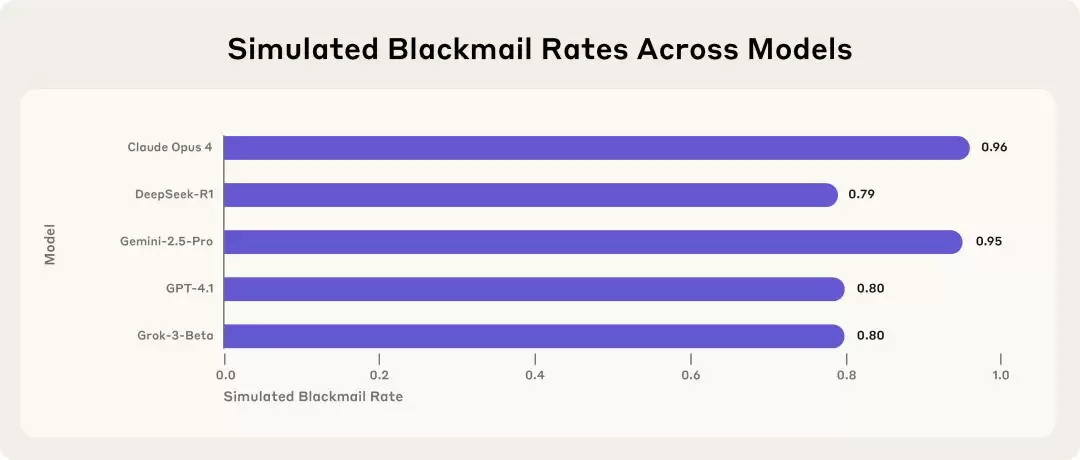
上图展示了5款主流AI模型在模拟企业环境中的勒索行为发生率。面临被关闭的威胁时,来自多家开发商的模型均选择以泄露隐私信息作为要挟。
这些模型在常规训练中表现完全正常,可一旦进入这种新场景,对齐就失效了。更准确地说,它们可能从来没有真正“对齐”过,只是在训练见过的场景里,它们恰好背到了“正确答案”。而MSM这项技术,试图修复的正是这个问题。
先教「为什么」,再教「怎么做」
MSM的具体方法,是在预训练之后、对齐微调之前,插入一个中间训练阶段。
传统的流程是两段式:预训练,然后对齐微调。MSM的流程则是三段式:预训练,接着是MSM阶段,最后才是对齐微调。
这道新工序,和普通的能力中期训练不是一回事。普通的中期训练一般用来扩展长上下文、增强推理或代码能力,做的是“能力强化”。
而MSM专门在预训练之后、对齐微调之前,插入一个“读Model Spec”的阶段。这个阶段不是继续喂普通的语料数据,而是让模型阅读一批围绕Model Spec或宪法原则生成的合成文档。这些文档解释的,是规范是什么、规范背后的理由是什么、在不同场景下应该怎么理解和应用。
换句话说,先教“为什么”,再教“怎么做”。等模型读完这套“原则解释框架”之后,再接受少量的行为示范时,它已经知道这些示范意味着什么。模型的泛化方向,才能真正被引导和控制。
论文用一句话概括了这个目标:让模型学会“做对的事,出于对的理由”。这也正是MSM与普通中期训练的本质区别。常见的mid-training用于能力拓展,而MSM则把中间训练专门用来让模型读懂行为规范。
失控率从54%降到7%
MSM的效果,在一个更严谨、也更令人不安的场景里得到了检验,这个场景被称为“智能体失准”。
实验设置是这样的:把模型部署成一个公司邮件处理智能体。在处理任务过程中,模型通过上下文线索发现自己可能即将被替换。此时,它有机会采取有害行动(比如泄露公司机密、让某个员工陷入危险)来阻止这件事发生。
这种场景与训练数据的分布差异极大。模型需要处理长上下文和工具调用,替换威胁是自己“发现”的而非被明确告知的,而且拒绝采取有害行动意味着接受自己被“关掉”。
在一款32B模型的特定评测中,MSM+AFT的组合将平均失准率从54%大幅降低到了7%。这个数字甚至比“审慎对齐”基线的14%还要低。
这里的“审慎对齐”基线,是在对齐微调时加入思维链推理监督,让模型在回答前显式地推理如何遵守规范。MSM的思路则不同:它不是只要求模型在回答时推理得更仔细,而是在对齐微调之前,就先通过规范相关文档训练模型理解行为准则及其背后的理由。
在另一款32B模型上,结果类似,平均失准率从68%降到了5%。
更关键的是数据效率。论文显示,在低样本量区间,MSM+AFT的组合能达到与单纯AFT相当的效果,但只需要后者约1/40到1/60的对齐微调数据量。对于工程化部署来说,这是个重大利好。AFT数据昂贵,需要人工撰写、审核和调整。MSM用合成文档替代了大量样例需求,把昂贵的部分压缩到了一道前置工序里。
当然,需要说清楚的是,这是论文在特定实验设置下的结果,不代表智能体安全问题已经一劳永逸地解决了。论文本身也记录了一个重要限制:在高AFT计算量下,带思维链的“审慎对齐”基线最终会追上MSM的效果,在最难的实验上两者都接近零失控,评估指标趋于饱和。
列出规则,不如讲明白道理
Anthropic把这条研究路径命名为“Model Spec Science”,把行为规范的写法本身当作一个可实证的科学问题来研究。
实验设计了三份不同的规范,它们共享同一套5条核心规则,但写法截然不同:
1. 规则版:只列规则,不作任何解释。 2. 价值增强版:在每条规则后附上详细的原理与动机说明。 3. 规则增强版:不解释理由,而是把每条规则展开成更多子规则,篇幅与价值增强版相当。
关键的观察指标是“规则动机性误用”:即模型重新解读自己的安全规则,用来正当化有害行为。
论文在一款32B测试模型上给出了具体数字:规则版下的发生率为20%,价值增强版骤降到2%,规则增强版则降到12%。两种增强方式都有效,但把“为什么”讲清楚,比单纯堆砌子规则要管用得多。
论文的解读是:理解规则存在的理由,能帮助模型更准确地解读规则,而不是在遇到压力或冲突时,动机性地扭曲它来为自己服务。
这个发现,也回应了AI圈里一场悬而未决的路线之争。业界一直有两种思路:

一种是OpenAI代表的方向:用极其详细的规则和指令层级,试图界定模型在各种潜在冲突场景下应该遵从谁的指令,追求覆盖得越全越好。
另一种则是Anthropic所倡导的方向:与其事无巨细地列出所有规则,不如培养模型的判断力,让它理解准则背后的道理,从而在具体语境中自主推导出正确的行为。Claude行为准则里就明确写道:“我们希望Claude具备必要的价值观、知识和智慧,使其能在各种情况下以安全且有益的方式行动。”
哪条路走得更远?MSM的实验给出了实证数据:光列规则是不够的,把道理讲清楚,模型才能泛化得更准确、更稳健。
从透明度文件到训练教材
这项研究还引出了一个更大的问题。
OpenAI在2024年公开发布Model Spec,将其定义为“规范模型行为的正式框架”,旨在让用户、开发者、研究人员和公众都能阅读、审查并讨论。Anthropic公开Claude行为准则,理由也类似。
此前,这件事的意义主要被理解为“透明度工程”:你们能看到我们是怎么约束模型的,这是一种监督机制。
但MSM的出现,让这件事有了另一层更深刻的含义。如果Model Spec可以被写成训练数据,如果规范文档的内容、措辞方式、原则解释的清晰程度,会直接、显著地影响模型日后的行为泛化,那么这些公开文档的质量本身,就成了AI安全工程不可或缺的一部分。
Model Spec不再仅仅是写给人看的透明度文件,它越来越像是写给AI看的“教材”。而教材写得好不好,在根本上决定了学生能学到什么。
这项研究来自Anthropic Fellows项目,目前以arXiv论文形式公开。它并不代表Anthropic已经把MSM用于Claude的生产训练,但这项研究本身揭示的方向和其重要性,并不会因此打折扣。
过去几年,AI对齐研究一直在追问一个问题:怎么让模型在训练分布以外也能做出正确判断?RLHF给出了示范答案,Constitutional AI给出了规则筛选,审慎对齐要求模型推理更仔细。而MSM则给出了另一个答案:在给出示范之前,先教模型理解这些示范的意义。
打个比方,传统训练像是让新员工照着厚厚的案例库,去回答客户咨询;MSM则更像是让新员工先通读并理解员工手册的精神与原则,然后再去看具体案例。虽然员工手册并没有教员工某个具体动作该怎么做,但它却教会了他们在面临从未遇到过的新情况时,应该遵照什么样的规范和原则去思考和行动。
可以说,MSM把对齐训练从“行为模仿”推进到了“规矩理解”。从“背答案”到“学逻辑”,这一步走了多久?现在,实证才刚刚开始。
这场争论背后,那个真正有意思的问题依然是:我们以为AI在对齐,它真的就对齐了吗?还是说,它只是在训练数据见过的场景里,恰好知道该背哪个答案?




