超越Claude Mythos和GPT-5.5!斯坦福Agent验证框架拿下SOTA,Transformer作者转发
LLM-as-a-Verifier:从“裁判”到“验证者”的范式升级
最近,AI社区里有个新框架引起了不小关注,连Transformer论文作者Lukasz Kaiser和GAN之父Bing Xu都转发了。这个框架叫LLM-as-a-Verifier,本质上是一种通用的验证机制,它能和市面上几乎任何智能体框架或模型无缝结合。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
这项工作是斯坦福、伯克利和英伟达三家联手搞出来的,阵容相当豪华。
研究结果很有意思:通过增加验证阶段的计算量,智能体的整体性能可以得到显著提升。在目前影响力最大的AI编程基准之一Terminal-Bench上,这个方法甚至超越了Claude Mythos和GPT-5.5的表现。

目前,LLM-as-a-Verifier在AI编程领域的两个重量级基准——Terminal-Bench和SWE-Bench Verified上,都拿下了当前最优的性能。
方法
其实,很多现有的智能体框架本身已经具备了解决问题的能力。如果你让同一个智能体反复尝试同一个任务(比如跑上100次),它总能在某一次尝试中撞上正确答案。
但问题出在哪呢?出在它自己并不知道“哪一次”才是对的。这个“不自知”的毛病,在处理那些步骤冗长、环环相扣的长时序任务时,就显得尤为致命。
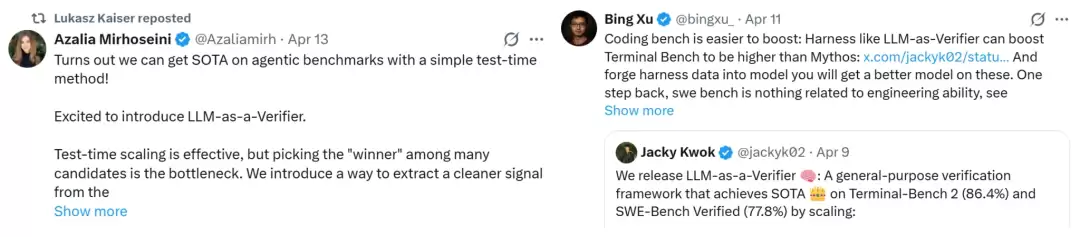
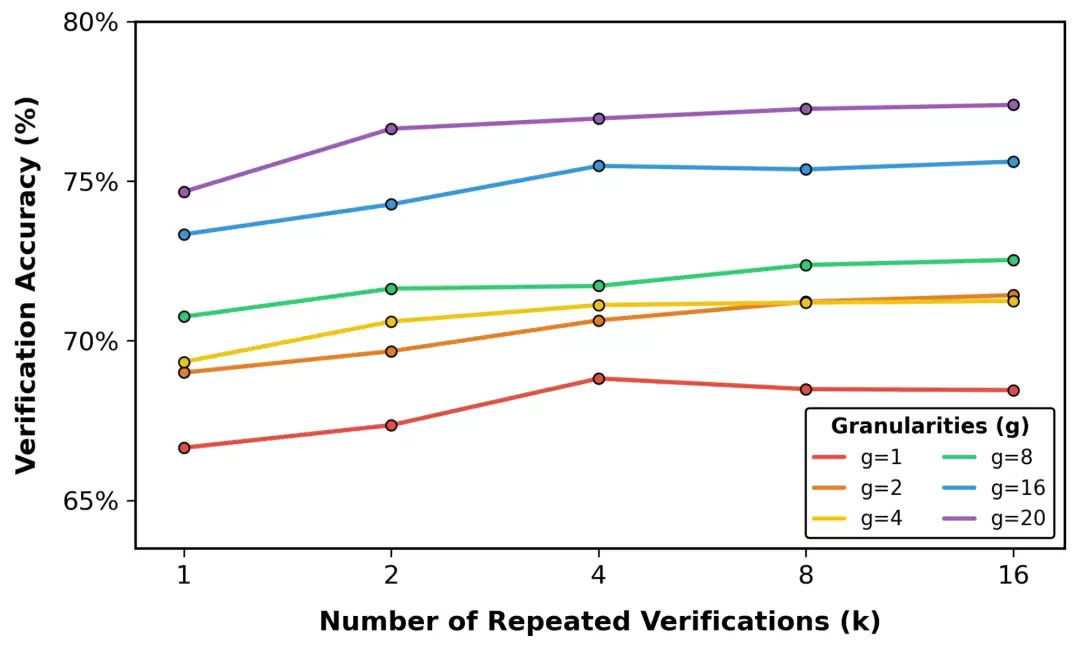
LLM-as-a-Verifier的解决思路,是从三个维度上把验证过程做“细”:提升评分标记的细粒度、增加重复验证的次数,以及把笼统的评价标准分解成多个具体维度。这套组合拳下来,验证能力上去了,下游任务的成功率自然也跟着水涨船高。
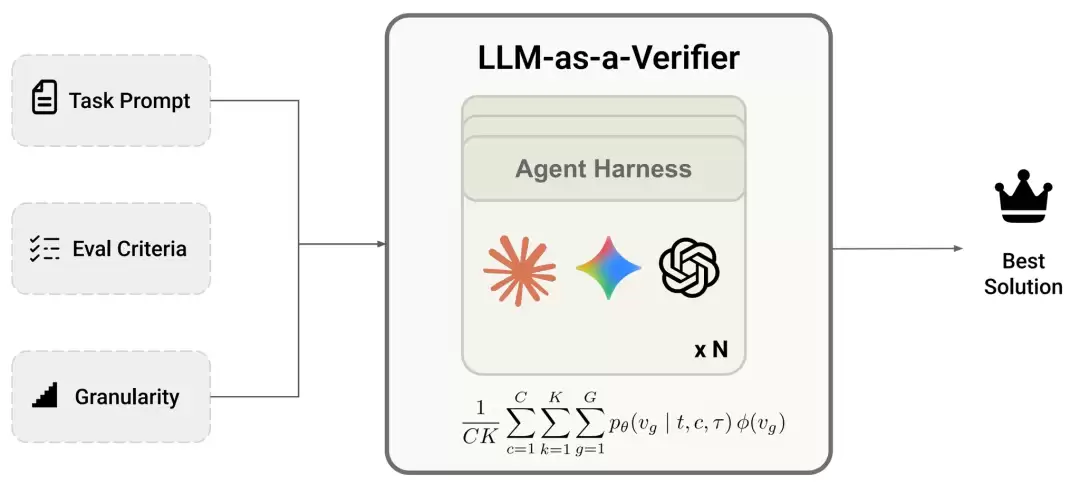
团队还发现一个规律:评分标记的粒度越细,正确样本和错误样本之间的得分差距就越明显,区分起来也就越容易。
核心问题:LLM-as-a-Judge的局限性
传统的“LLM-as-a-Judge”是怎么做的呢?通常是给模型一个提示,让它输出一个离散的评分,比如1到8分,然后选概率最高的那个分数作为最终判决。
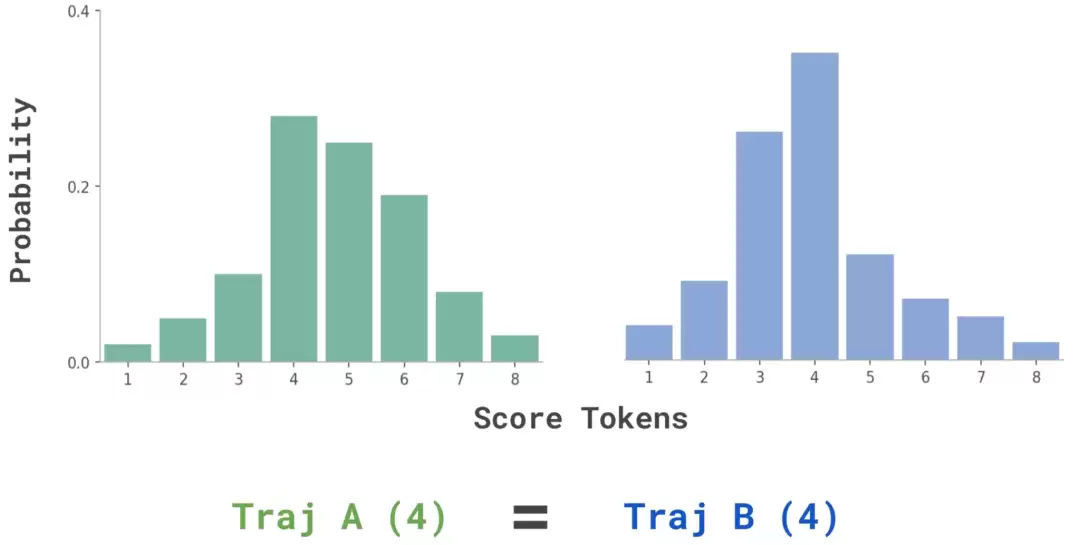
这种方法有个硬伤:评分粒度太粗糙了。当比较两条复杂的长时序任务轨迹时,模型经常会给它们打出相同的分数(比如都评4分),导致大量平局。这样一来,根本没法有效区分孰优孰劣。
在Terminal-Bench上,这种粗粒度评分导致的平局率高达27%,严重限制了评判的精确性和区分度。
LLM-as-a-Verifier: 从判分到验证的范式转变
这里有个概念上的根本区别。打个比方,“裁判”是对整体局面做出一个概括性的终审判决;而“验证者”则更像一个质检员,需要对每一个具体环节的真实性和正确性进行核验,因此必须更细致、更深入。
正是基于这个思路,团队提出了LLM-as-a-Verifier。它通过扩展三个关键维度来提供这种细粒度的反馈:评分标记的粒度、重复验证的次数,以及评估标准的分解。
具体操作是这样的:给定一个任务t和两条候选轨迹,LLM-as-a-Verifier会构建评分提示,并通过提取特定评分标记的对数概率,得到对应的条件概率分布。
接着,一条轨迹的奖励值会被量化为以下公式:

其中:
C代表评估标准的数量,K是重复验证的次数,G是评分标记的数量(即粒度等级)。公式中的核心是模型对每个评分标记赋予的概率,以及一个将标记映射为实际标量值的函数。
那么,怎么选出最优轨迹呢?方法很直观:采用循环赛制。每一对候选轨迹都会用上述公式计算奖励值,奖励高的胜出。最终,在所有比较中胜场最多的那条轨迹,就是赢家。
实验结果
在Terminal-Bench 2.0和SWE-Bench Verified这些以复杂、冗长著称的基准测试中,LLM-as-a-Verifier的表现全面超越了现有前沿模型,稳坐当前性能榜首。所有数据都来自最新的官方排行榜。

这个框架的通用性很强,能轻松集成到不同的智能体框架里。在三个主流基准上的测试结果就是证明:
在ForgeCode上,验证准确率提升到了86.4%;在Terminus-Kira上,达到了79.4%;在Terminus 2上,也增加到了71.2%。

这意味着,无论底层用的是什么框架或模型,这套验证方法都能兼容并有效提升性能。
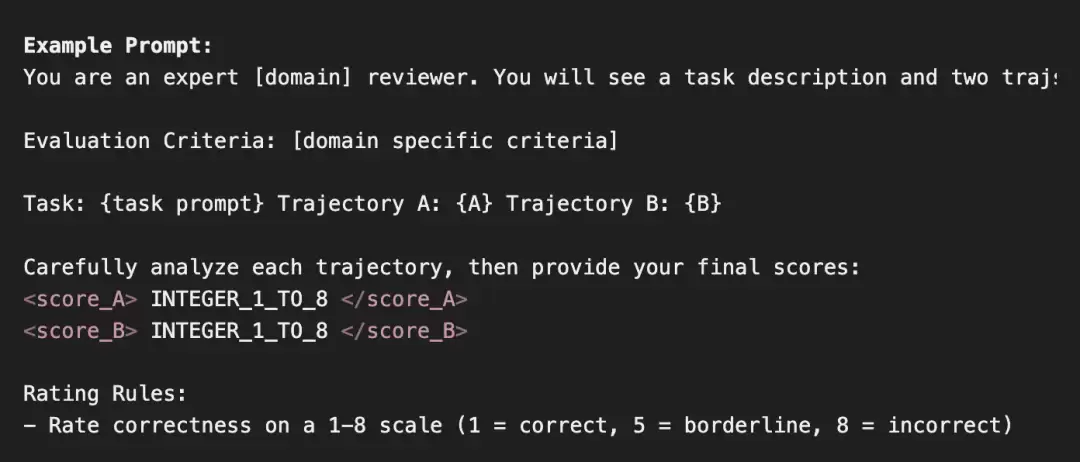
对比传统的LLM-as-a-Judge,LLM-as-a-Verifier在验证准确率和消除平局两方面优势明显。即便把传统方法的重复验证次数增加到16次,Verifier依然能保持至少7个百分点的准确率优势,并且彻底杜绝了平局现象。
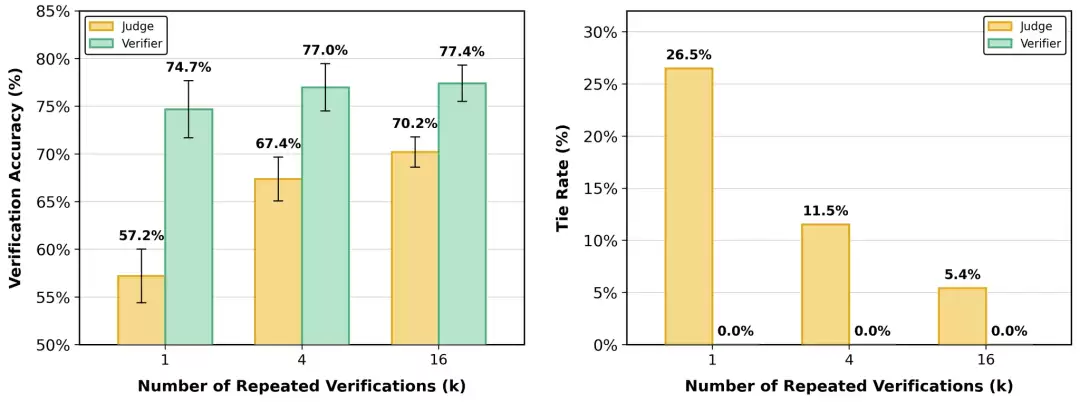
进一步的实验揭示了性能提升的来源:增加评分标记的粒度,或者提高重复验证的次数,都能显著拉升验证准确率。特别是在将评分粒度从1级细化到20级的过程中,量化误差被大幅压缩,使得评估结果更接近真实的奖励分布。
LLM-as-a-Verifier摒弃了“一分数定乾坤”的旧模式,转而把轨迹验证拆解成三个可组合、可评估的具体标准:一是规范合规性,看轨迹是否符合所有任务要求;二是输出格式,验证结果格式对不对;三是错误检测,排查轨迹中是否存在明显的错误信号。

总而言之,通过更细致的评分粒度、多次验证和标准分解,LLM-as-a-Verifier框架实现了更高的验证准确率和更强的区分能力,彻底扫清了评分平局的障碍。这不仅直接提升了智能体的任务性能,也为其在长时序、高风险任务中的安全稳定运行,加了一道可靠的保险。
团队介绍
这个项目由斯坦福大学的CS博士生Jacky Kwok牵头。主要贡献者包括伯克利EECS的博士生Shulu Li。通讯作者阵容堪称全明星:有UC伯克利教授、Databricks创始人Ion Stoica;斯坦福教授、前DeepMind与Anthropic研究员Azalia Mirhoseini;以及英伟达AI与自动驾驶研究总监Marco Pa vone。
相关攻略

LLM-as-a-Verifier:从“裁判”到“验证者”的范式升级 最近,AI社区里有个新框架引起了不小关注,连Transformer论文作者Lukasz Kaiser和GAN之父Bing Xu都转发了。这个框架叫LLM-as-a-Verifier,本质上是一种通用的验证机制,它能和市面上几乎任何

Hermes Agent 效率提升实战:五大核心优化技巧 想让你的 Hermes Agent 跑得更快、更稳、更聪明?直接上干货。下面这五个方面的优化策略,从初始化配置到日常交互,层层递进,能系统性地解决效率瓶颈。咱们不聊理论,只看具体怎么操作。 一、精简Agent初始化配置 很多性能问题,其实在启

2026年4月4日:Anthropic收紧生态控制权的标志性一步 该来的还是来了。2026年4月4日,大模型领域的重量级玩家Anthropic正式发布了一项关键的生态政策调整。具体说来,就是从**美国东部时间4月4日15点(北京时间4月5日3点)** 开始,旗下的Claude大模型将不再支持Open

如何借力 Claude 快速拆解复杂的 Spring Boot 业务代码 面对一个刚接手的历史遗留项目,打开代码仓库的瞬间,那种感受恐怕很多同行都经历过: Controller层像迷宫,层层嵌套,入口难寻;Service方法动辄几百行,逻辑纠缠在一起;Mapper的调用链条深不见底;更棘手的是,一个

Anthropic源代码泄露:Claude Code新型prompt逃逸漏洞浮出水面 前阵子安全圈里传出了新动静。Anthropic的部分源代码意外泄露,研究者们顺藤摸瓜,竟发现了一条针对其代码大模型Claude Code的新型prompt逃逸攻击路径。简单来说,攻击者能借此绕过模型内置的内容审查机
热门专题







热门推荐

MySQL视图自增主键映射与逻辑主键生成方案详解 在数据库设计与优化实践中,视图(View)是简化复杂查询、封装业务逻辑的强大工具。然而,许多开发者在操作视图时,常希望实现类似数据表的自动主键生成功能,这在实际应用中却面临诸多限制。本文将深入解析MySQL视图与自增主键的关系,并提供切实可行的逻辑主

MySQL启动时默认字符集没生效?检查my cnf的加载顺序和位置 先明确一个关键点:MySQL启动时,并不会漫无目的地去读取所有可能的配置文件。它有一套固定的、按优先级排列的查找路径(通常是 etc my cnf、 etc mysql my cnf,最后才是 ~ my cnf),并且找到第一个

基本医疗保险的“双账户”模式:统筹与个人如何分工? 说起咱们的基本医疗保险,它的运作核心可以概括为“社会统筹与个人账户相结合”。简单来说,整个医保基金就像一个大池子,但这个池子被清晰地划分为两个部分:一个是大家共用的“统筹基金”,另一个则是属于参保人自己的“个人账户”。 那么,钱是怎么分别流入这两个

TYPE IS RECORD 语法详解与核心应用指南 在PL SQL数据库编程中,TYPE IS RECORD是定义自定义复合数据类型的关键工具。其标准语法结构为:TYPE 类型名 IS RECORD (字段名 数据类型 [DEFAULT 默认值] [NOT NULL]);。通过该语法,开发者可以灵

在定点医疗机构的选择上,政策其实给参保人留出了不小的灵活空间。获得定点资格的专科和中医医疗机构,会自动成为统筹区内所有参保人的可选范围,这为大家获取特色医疗服务提供了基础保障。 在此之外,每位参保人还能根据自身需要,再额外挑选3到5家不同层次的医疗机构。比如,你可以选择一家综合三甲医院应对复杂病情,