DeepSeek再炸场!模型本地化部署迎来新拐点
4月24日,AI领域又迎来一个重磅时刻:DeepSeek-V4系列模型预览版正式上线并同步开源。更值得关注的是,联想AI工作站宣布完成全面适配。这意味着什么?简单说,顶尖大模型跑在自家电脑上的时代,门槛正在被大幅拉低。
效率天花板:百万级超长上下文
这次DeepSeek V4带来的第一个震撼弹,是百万级Token的超长上下文能力。约75万字的处理上限,意味着它可以一次性“吞下”整部《三体》三部曲,或者一个完整的代码仓库。这背后是混合注意力架构(CSA+HCA)的创新突破。
更关键的是效率。通过全新的稀疏注意力机制,V4-Pro在处理百万token时,计算量仅为前代的27%,显存占用更是低至惊人的10%。而面向效率优化的V4-Flash版本,这两个数字被进一步压缩到10%和7%。长文本处理的壁垒,这次是真的被凿开了。
性能登顶:全球顶级的综合实力
架构创新直接反映在性能上。DS-V4的综合实力已经稳稳站在全球第一梯队,多项关键能力甚至超越了顶级闭源模型。
在数学、STEM和竞赛代码能力上,它已经超越了所有公开评测的开源模型,与GPT-5.4、Claude Opus 4.6等闭源巨头站在了同一水平线。
其Agentic Coding(代码智能体)能力达到了开源最优水平。在自主规划、工具调用和长程任务执行方面的进步尤为明显,内部使用体验反馈甚至优于Claude Sonnet 4.5。
在世界知识测评方面,它也大幅领先其他开源模型,仅稍逊于顶尖闭源模型Gemini-Pro-3.1。可以说,开源模型的性能天花板,被再次刷新了。
两大版本:旗舰与普惠并行
DeepSeek-V4系列提供了两种基于MoE架构的模型,清晰地区分了应用场景。Pro版(专家模式)瞄准的是复杂推理、Agent任务、代码工程、科研分析等高难度战场;而Flash版(快速模式)则面向日常高频、需要快速响应的场景。
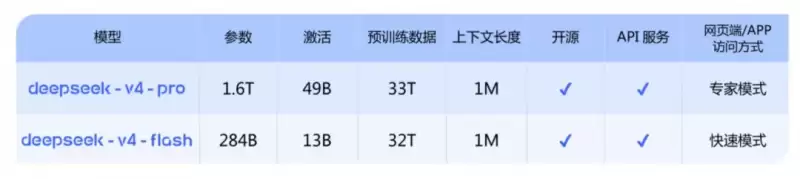
这里有个非常实在的亮点:V4-Flash在简单任务上的表现接近Pro版,但成本仅为后者的18%。对于大多数常规应用场景而言,Flash版无疑是更具性价比的选择。普惠,不再只是口号。
原生多精度设计:从源头适配全档位量化
这次升级还有一个容易被忽略但至关重要的细节:DeepSeek-V4采用了“FP4+FP8混合精度”的量化感知训练策略。这意味着模型从训练阶段就原生理解低精度运算,为向下兼容INT8/INT4等格式打下了极好的基础。
对企业用户来说,这直接转换成了部署灵活性。DeepSeek-V4不仅能在云端流畅运行,更能高效适配本地AI工作站。从前期的开发验证到后期的业务落地,整个流程都变得更加顺畅高效。
联想AI工作站全面适配
模型能力再强,也需要坚实的算力底座来承载。面向DeepSeek-V4的不同版本,联想AI工作站已经完成了全面适配。本地化部署的路径,变得前所未有的清晰。

DeepSeek V4-flash:桌面级AI超算底座
DeepSeek-V4-Flash主打高频、快速、普惠,非常适合个人开发者、小型团队以及内容创作团队。长文本处理、代码辅助、知识库问答、本地Agent搭建等任务,都能高效完成。
联想给出的方案是:推荐两台ThinkStation PGX互联,打造桌面级AI超算底座。ThinkStation PGX AI超算工作站搭载NVIDIA GB10高性能芯片,配备128GB一致性内存,单台就能提供1000TOPS的AI算力,并附赠全套专业开发软件栈。

单台机器可支持200B参数模型,而双机互联最高能适配405B参数模型。承载DeepSeek-V4-Flash的本地推理、长上下文处理以及复杂Agent应用部署,完全不在话下。
DeepSeek V4-Pro推荐:支持百人团队并发使用
对于更重载的V4-Pro,联想推荐的是ThinkStation PX旗舰双路AI工作站。它面向的是专业AI开发、数据科学、工程仿真与复杂计算任务,核心用途包括模型适配、量化推理、行业化验证和企业级AI工作流开发。
其扩展能力非常强悍,可支持至多4张顶级专业显卡,显存最高可达288GB(72*4),最高能支持百人团队的多用户并发使用。

如果还有生产级推理这类更高阶的需求,它还能与联想服务器形成“工作站开发验证 + 服务器生产部署”的协同架构,灵活应对不同阶段的算力需求。
强强联合,让AI转型触手可及
根据IDC最新报告(2025年12月),联想工作站产品以47.4%的市场份额稳居榜首。其核心优势可以归结为五点:强大性能、快速部署、本地安全、多维生态和全栈服务。这使它成为企业和个人AI转型过程中一个非常可靠的“最佳拍档”。
相比传统的云服务或纯服务器方案,这种“顶尖模型+本地工作站”的组合,真正实现了几个关键突破:算力下沉到桌面、核心数据留在本地、总体成本可控、开发效率倍增。AI开发正在从过去的“云端依赖”模式,稳步走向“本地自主”的新阶段。
这场强强联合,持续为各行业的智能化升级筑牢算力底座。一个高效、可控且落地性更强的AI普惠时代,或许已经拉开了序幕。




