多次偶遇背后的一场「合谋」
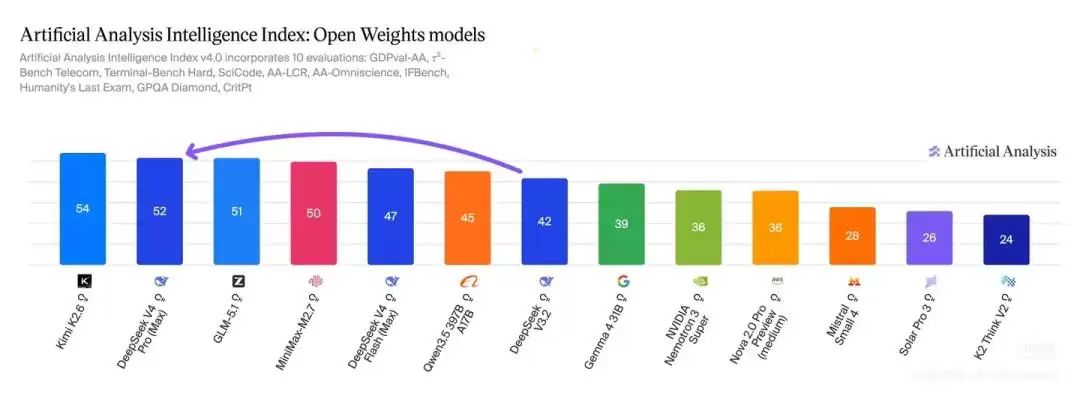
这一周,全球大模型领域的重磅消息接二连三,热闹非凡。国内赛场更是精彩纷呈,从周一开始,Qwen、Kimi、小米、腾讯等玩家相继亮出最新成果。到了周五,备受期待的DeepSeek V4双版本终于发布,瞬间在国内AI圈掀起了一波讨论热潮。
一个值得关注的里程碑是,中国正式迈入了“万亿参数俱乐部”,并且已有DeepSeek和Kimi两家公司选择将如此规模的模型开源,小米也预告了其万亿模型的开放计划。
仔细研读DeepSeek V4近60页的技术报告,一个有趣的发现浮出水面:这两家已开源的万亿巨头之间,存在着一种超越竞争的默契。这种默契所带来的协同效应,远比任何单打独斗都更具力量。
如果往前追溯,你会发现DeepSeek和Kimi的“偶遇”早已不是第一次。这背后,或许源于两位创始人对Scaling Law的共同信仰,以及对AGI这一终极目标的竞相追逐。
从DeepSeek-R1与Kimi K1.5发布仅隔两小时,到双方关于推理与优化的论文同期发表;从Kimi的数学推理模型启发DeepSeek-Prover V2,再到本周Kimi K2.6与DeepSeek-V4的齐头并进——时间线上的巧合未免太多。
这看起来不像是一场你死我活的厮杀,反倒更像一种基于“开源共享”精神的共同进步。用汽车圈流行的一句话来形容,或许很贴切:“好的设计,总是心有灵犀。”
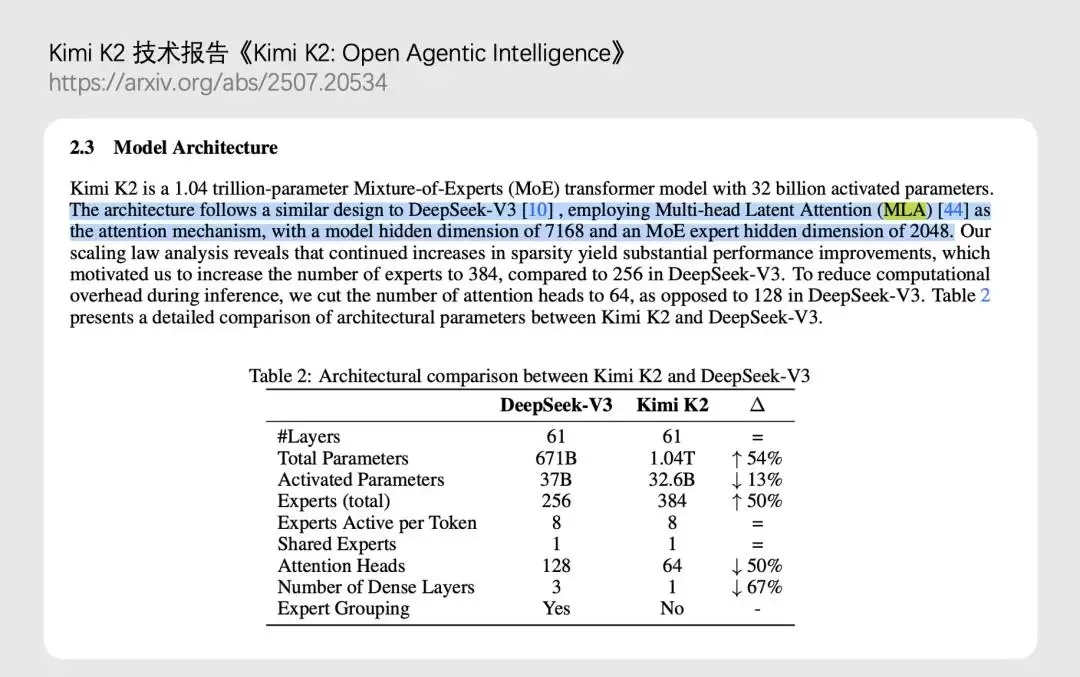
技术层面的联动尤为明显:Kimi K2采用了DeepSeek V3首创的MLA注意力机制;而到了DeepSeek V4,则引入了经过Kimi大规模验证的Muon优化器。这种你追我赶、相互借鉴的态势,已然成为行业技术演进的一大亮点。
MLA注意力机制:DeepSeek 创新,Kimi 复用
首先值得一书的是MLA注意力机制。这个由DeepSeek在V3中首创的设计,通过巧妙的低秩压缩技术,有效降低了长上下文推理时的显存占用,让处理超长文本成为可能。这项创新很快得到了业界的认可,Kimi在构建K2模型时,便在其注意力机制中采纳了MLA的设计思路。
二阶优化器:Kimi 大规模验证,DeepSeek 跟进
另一个关键突破发生在优化器领域。2025年2月,Kimi发表了《Muon is Scalable for LLM Training》论文,在480亿参数的Moonlight系列模型上验证了Muon优化器的有效性,旨在挑战已统治行业十年的Adam优化器。同年7月,万亿参数的Kimi K2首次大规模应用了二阶优化器Muon,充分展示了其在大模型训练中的潜力。
如今,DeepSeek V4也跟进采用了Muon优化器技术,以提升训练过程的稳定性。两家公司将底层的优化技术相互吸纳,打破了技术壁垒,展现了一种前所未有的、深层次的协作姿态。
残差连接:两种不同的解决方案
在残差连接这一关键组件上,两家公司也各自给出了精彩的答案。
DeepSeek在V4中引入了mHC残差连接,目标是提升信息传递的效率。通过改变多头注意力的拼接方式,mHC优化了梯度流动,实测将训练效率提升了约30%。
Kimi则提出了Attention Residuals(注意力残差),同样致力于优化信息流的传递效率,并提升了模型整体表现。这一创新获得了业界多位重量级人物的关注。Andrej Karpathy点评道“我们对《Attention is All You Need》的理解还不够”,OpenAI的推理专家Jerry Tworek则认为“我们应该重新思考一切,深度学习的2.0时代正在到来”。就连马斯克也在社交媒体上为此点赞,称其为“令人印象深刻的研究”。
两种方案各有侧重,体现了同一技术问题上不同的解决思路与工程智慧。
长上下文推理:两种技术路线的探索
长上下文推理是衡量大模型能力的重要标尺,也是一项巨大的工程挑战。Kimi和DeepSeek在此问题上选择了不同的技术路径。Kimi早在2024年便实现了百万Token的上下文能力,尽管能力强大,但其计算成本随着上下文长度线性增长的问题,对普通开发者而言仍是一道门槛。
到了2026年,针对成本难题,两家公司分别提出了自己的解决方案:
DeepSeek选择了稀疏注意力路线。让模型只聚焦于输入中的关键部分,从而大幅降低计算量,使得百万上下文的成本变得更为可控。这种方法精度高,但对设计和调优提出了更高要求。
Kimi则推出了线性注意力架构。它从根本上改变了注意力机制的计算方式,将计算复杂度从传统的O(n²)降低到O(n),从理论层面为长上下文的高效处理开辟了新道路。
稀疏注意力强调精准性,线性注意力追求高效性。重要的是,Kimi和DeepSeek同时在这两条路线上发力探索,为未来长上下文推理的规模化应用提供了更多元、更坚实的技术选项。
从「两个公司」到「一套基础设施」
DeepSeek和Kimi之间频繁的“偶遇”,远不止是技术圈的热闹谈资。它更深层的意义在于,正在悄然重塑中国AI产业的格局。
对比来看,GPT-4的参数量至今未正式公布(外界估计在1.8万亿左右),Claude 3.5 Opus同样选择闭源。而中国的这两家创业公司,不仅做出了同等量级的模型,更关键的是选择了全面开源。这意味着任何开发者、研究机构或企业,都能免费获取这些顶尖模型进行二次开发和私有化部署。
带来的直接变化是惊人的:企业私有化部署的成本被砍至原来的十分之一。让中小企业在自己的服务器上跑起万亿参数模型,这在一年前还是难以想象的事情。
开源生态的活力正在显现。在OpenRouter平台上,两家的API调用量稳居中国区前两名。在应用层,Kimi被海外爆款编程工具“套壳”接入,而DeepSeek则被日本乐天集团直接集成,包装成了全新的Rakuten AI 3.0。
这股来自东方的开源力量,已经引起了硅谷巨头的正视。
在Meta最新模型Muse Spark的官方技术博客中,Llama 4的性能被直接拿来与DeepSeek-V3.1以及Kimi-K2进行对比:
而在黄仁勋的CES主题演讲中,DeepSeek和Kimi K2-Thinking模型更是被赫然置于大屏幕,作为展示其下一代Blackwell与Rubin芯片强大性能的基准标杆:
与此同时,两家公司都在国产芯片的适配与应用上做出了实质性投入。DeepSeek V4首次深度适配华&为昇腾芯片,推理环节将运行在国产硬件之上。Kimi的Prefill-as-a-Service方案则提出了跨数据中心异构硬件推理框架,允许用不同类型的国产芯片分别承担Prefill和Decode阶段,实测吞吐量提升54%,首token延迟降低64%。这为国产芯片进入大模型推理的核心链条,打开了一个切实可行的切口。
黄仁勋曾在播客节目中说过一句意味深长的话:“芯片又不是铀浓缩,阻挡不了中国芯片的进步,他们依旧可以通过国产芯片来开发模型。”他或许没想到,DeepSeek和Kimi正在用实际行动,让这个未来加速到来。
结语:两个广东人,撑起中国 AI 的半边天
技术所能达到的高度,最终取决于开拓者的格局。
2023年同年起步,以最短时间双双叩开百亿美金估值的大门——DeepSeek与Kimi,始终保持着团队人数精简、但人才密度顶尖的配置。两位同样来自广东的创始人,杨植麟与梁文锋,既是技术的虔诚信徒,也被视为中国AI国家队的中坚力量。
在高层主持召开的经济形势专家和企业家座谈会上,两人时隔一年分别建言献策,这成为中国AI发展史上的一个有力注脚。他们各自引领着技术范式:DeepSeek向世界证明了“思维链”的威力,而Kimi则在国内点燃了“智能体”落地的浪潮。
在追逐AGI的这场马拉松中,没有哪家公司能闭门造车地跑完全程。DeepSeek与Kimi之间,存在竞争,更有共鸣。Muon与MLA的技术互通,在底层机制上惺惺相惜的探索,恰恰说明:中国AI真正的底气,从来不是某一家公司的单打独斗,而是在这种“偶遇”中碰撞出的技术火花,以及在开源生态里悄然生长、互利共生的繁荣体系。
双峰并峙,终将顶峰相见。属于中国大模型的万亿级航海时代,帷幕才刚刚拉开。




