无锁编程与分布式编程,谁更适合多核CPU?深度性能对比
在上一篇文章中,我们深入探讨了多核系统下三种典型锁竞争模式的加速比表现,其中分布式锁竞争展现出与CPU核心数成正比的线性加速潜力,性能优势显著。近年来,无锁编程(Lock-Free Programming)在学术界获得了大量关注。这自然引出一个关键问题:采用无锁编程技术能否获得比分布式编程更优的加速比?或者说,在面对现代多核CPU架构时,无锁方案是否比分布式方案更具适用性?本文将进行详细解析。
无锁编程的本质与性能基础
无锁编程的核心思想,是使用硬件支持的原子操作(Atomic Operations)来替代传统的互斥锁(Mutex)机制,以实现对共享数据的安全并发访问。我们以一个经典的整数递增为例。传统的加锁方式代码如下:
int a = 0;
Lock();
a += 1;
Unlock();
如果对这段代码进行反汇编,你会发现 a += 1; 这条高级语言指令通常会被翻译成多条底层汇编指令:读取内存值到寄存器、在寄存器中执行加法、将结果写回内存。在单核CPU上,若在这三条指令执行期间发生线程切换,其他线程对变量a的修改可能会造成数据不一致。而在多核CPU环境中,问题更为严峻:即使是一条写内存指令,也可能因多个物理核心同时写入同一内存地址而导致数据竞争(Data Race),因此同步保护必不可少。
如果使用原子操作,例如在Windows VC环境下的 InterlockedIncrement(&a),最终的递增操作会被编译为一条带有 lock 前缀的汇编指令。这条指令通过内存屏障(Memory Barrier)机制,阻止其他核心在同一时刻访问该内存地址,从而原子性地完成“读-改-写”过程。原子操作的开销通常比使用锁低一倍以上,可以被视为一种粒度极细的“锁”。
在无锁编程中,最关键的原子操作是CAS(Compare-And-Swap),例如VC中的 InterlockedCompareExchange。其最大优势在于提供了非阻塞(Non-Blocking)的特性。但必须注意,像 InterlockedCompareExchange 这类操作通常附带完整的内存屏障(Full Memory Barrier),这意味着它不仅保护目标变量,还会对所有内存访问进行排序。从竞争模式的角度看,这极易引发固定式或随机式锁竞争,而难以形成理想的分布式竞争。其竞争激烈程度有时甚至超过使用普通锁的场景,最终可能导致加速比表现反而不如固定式锁竞争。
当然,也存在如 InterlockedCompareExchangeAcquire 这类不附带完整内存屏障的原子操作,理论上性能更佳。但它们对硬件内存模型有特定要求,且相关的实际性能基准数据相对较少。
无锁编程在不同竞争模式下的加速比分析
那么,无锁编程在实际并发场景中的性能表现究竟如何?我们可以沿用之前的加速比分析模型进行评估。
首先分析固定式锁竞争模式。原子操作比传统锁更快,我们假设其加锁/解锁耗时减少为原来的1/2(相当于有效任务粒度增大一倍),同时其临界区内的指令极少,锁粒度可近似视为0。代入加速比公式计算后,其加速比极限值大约为使用普通锁时的两倍(相对于任务粒度),性能虽有提升,但仍无法突破阿姆达尔定律的限制,无法随CPU核心数量线性增长。
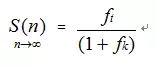
其次是随机式锁竞争模式。将普通锁替换为原子操作(锁粒度≈0)后,对于任务粒度本身很大的情况,竞争概率p增加不明显;对于任务粒度极小的极端情况,竞争概率p最大可能增加近一倍,加速比也能获得相应提升。然而,在最坏情况下的加速比公式表明,其性能只是相对于普通锁略有改善,同样无法实现随核心数增长的线性扩展。
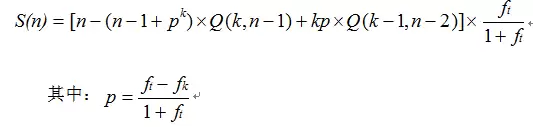
这里必须强调一个关键点:上述理论分析尚未计入无锁编程自身的算法开销。在实际的无锁算法(如无锁队列)中,一个CAS操作往往需要在一个循环中反复尝试(即“CAS循环”),才能成功完成一次更新。循环次数可能很高,这会引入额外的开销,导致实际性能低于理论计算值。
因此,结论非常明确:即使采用无锁编程,只要其引发的内存访问竞争模式仍是固定式或随机式,其加速比表现依然不理想,与分布式锁竞争(其最坏情况加速比也能接近CPU核数)存在显著差距。
分布式竞争与无锁结合的可能性探讨
或许有人会设想:既然分布式锁竞争性能优异,那么用原子操作来替代普通锁实现分布式竞争,是否可以获得更高的加速比?
从纯理论角度分析,如果使用不带全局内存屏障的原子操作来实现分布式竞争,确实有可能比使用普通锁获得更好的加速比。根据分布式加速比公式,使用原子操作后,有效任务粒度会增大2到3倍。对于任务粒度极小(这在实践中较为罕见)的场景,加速比可比使用普通锁时提升近一倍;但对于常见的、任务粒度较大的实际应用,加速比的提升幅度并不显著。
任务粒度的大小,主要取决于程序员的业务逻辑划分和设计。只要在任务划分时注意避免粒度过细,就能有效控制竞争开销,最大化加速比。而采用分布式锁竞争方案,其性能本身已经能够逼近单核多任务调度时的程序性能上限。
实用性对比:为何分布式编程更胜一筹?
除了理论性能,我们还需从工程实践角度考量:实现难度与迁移成本。
无锁编程的实现难度极高,代码复杂且容易出错,其正确性严重依赖于对特定硬件内存模型(Memory Model)的精确理解,这对于普通开发人员而言门槛过高。相反,分布式编程的思维模式与单核多任务时代的数据结构与算法设计一脉相承,普通程序员经过系统学习后完全可以掌握。
更重要的是生态与继承性。目前成熟的无锁算法实现数量有限,功能也相对受限,并且它几乎构成了一套独立于传统单核编程的新体系,难以复用以往积累的大量算法和代码库。分布式编程则是在原有单核多任务编程范式上的自然演进,能够充分继承和利用之前的软件成果。例如,实现一个用于分布式竞争的队列池,可以直接复用现有的、经过充分测试的线程安全队列算法。这意味着,采用分布式编程策略,能够将现有单核程序迁移到多核系统的工作量降至最低,通常只需进行模块化的重构而非重写。
结论
综合来看,我们可以从四个核心维度对两者进行全面比较:
| 比较项目 | 无锁编程 | 分布式编程 |
|---|---|---|
| 加速比性能 | 高度依赖竞争模式。除非实现为分布式竞争,否则性能通常不如分布式锁竞争。 | 加速比与CPU核数成正比,性能可接近单核多任务水平,扩展性优异。 |
| 实现的功能范围 | 受限于无锁算法库,功能实现有限。 | 不受限制,可应用所有传统编程模式。 |
| 程序员掌握难易程度 | 难度过高、过于复杂,需要深入理解内存模型,普通程序员难以驾驭。 | 难度与单核时代的数据结构及算法设计相当,普通程序员可以掌握。 |
| 现有软件的移植成本 | 通常需要废弃旧算法,难以复用历史代码,迁移成本高。 | 可继承已有算法与模块,在原有程序基础上进行重构即可,迁移成本低。 |
从上表的综合对比可以清晰看出,在绝大多数实际生产场景中,无锁编程的实用价值与性价比远低于分布式编程。因此,针对多核CPU系统的并发程序设计,分布式编程是比无锁编程更为合适、务实且高效的选择。
本文转自:https://blog.csdn.net/windows_zf/article/details/3086498




