一张真实的 top 命令监控截图,常常会揭示我们对这个经典系统工具最深的误解。最近就遇到一个典型案例:有运维同学看到某个进程的 %CPU 指标飙升至 100% 以上,立刻断定服务器即将崩溃。但实际情况呢?业务运行平稳,系统警报纯属虚惊一场。这恰恰说明,很多人使用了多年 top 命令,可能一直在误读其关键指标。
今天,我们就以这张截图为例,系统性地拆解 top 命令的正确解读方法,以及那些最容易踩坑的常见认知误区。
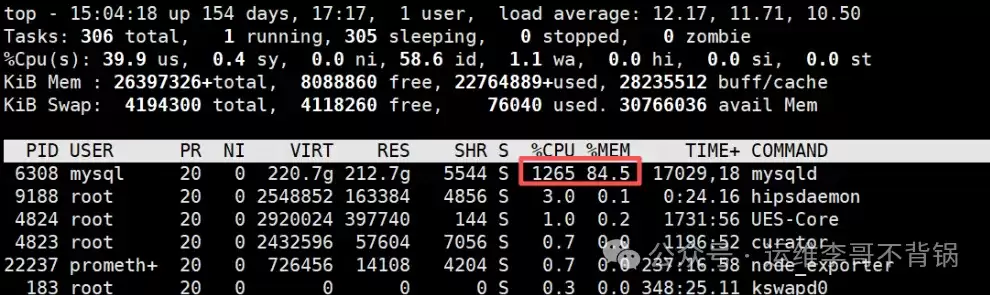
先看截图:关键指标分析
最引人注目的一行数据,无疑是这个:
PID USER VIRT RES %CPU %MEM COMMAND
6308 mysql 220.7g 212.7g 1265 84.5 mysqld很多人的第一反应是:“CPU 占用率都达到 1265% 了?服务器肯定要撑不住了!” 但事实恰恰相反,这正是对 top 命令输出的第一个,也是最常见的误解。
误区 1:%CPU 最大只能是 100%
错误理解: %CPU 列代表“单核 CPU 使用率”,因此最大值理应是 100%。
正确理解: 在 top 命令里,%CPU 的计算公式是 (进程使用的 CPU 时间 / 总 CPU 时间) × CPU 核心数 × 100%。其本质是“使用的 CPU 核心数 × 100%”。
以一台 16 核的服务器为例:
- 100% 意味着恰好有 1 个 CPU 核心被完全占用。
- 1265% 则意味着大约有 12.6 个核心正在被这个 mysqld 进程所使用。
所以结论很清楚:截图中的 MySQL 进程并非异常,而是在充分利用服务器的多核能力进行高并发查询或数据处理,这是性能良好的表现。
误区 2:load a verage 很高 = CPU 已经打满
再看截图顶部的系统负载信息:
load a verage: 12.17, 11.71, 10.50一看到 load average 值超过 10,很多人立刻会断定:“系统负载太高,CPU 快扛不住了!”
但这里有个关键前提被忽略了:这台机器总共有多少个 CPU 核心?
load average 表示的并不是 CPU 使用率百分比,而是系统中处于可运行状态(R)和不可中断睡眠状态(D)的平均进程数量。因此,判断负载是否过高的正确方式,是将其与系统的 CPU 总核心数进行对比。如果核心数是16,那么负载12属于合理范围。
误区 3:id 很低才说明 CPU 有问题
截图中关于 CPU 状态分布的这一行,透露了更多关键信息:
%Cpu(s): 39.9 us, 0.4 sy, 58.6 id注意看,idle (id) 值高达 58.6%。这意味着什么?超过一半的 CPU 资源实际上是空闲的,并未被使用。
现在,把几个数据联系起来看:
- mysqld 进程占用了约 1265% 的 CPU(即约12.6个核心)。
- 系统整体仍有 58.6% 的 CPU 处于空闲状态。
唯一合理的解释就是:这是一台核心数较多(例如32核)的服务器,而 MySQL 进程正在以高并发的方式高效利用其中一部分核心,但远未榨干整台机器的全部计算资源。
误区 4:VIRT 很大 = 内存要炸
内存相关的字段也容易引发误判和恐慌:
VIRT 220.7g
RES 212.7g看到 VIRT(虚拟内存)高达 220G,很多人会立刻联想到内存泄漏。但对于 MySQL 这类数据库进程来说,巨大的 VIRT 值往往是正常现象,它可能包含了:
- InnoDB Buffer Pool 的内存映射区域。
- 二进制日志、表空间等内存映射文件。
- 通过 malloc 等系统调用预留的虚拟地址空间(未必实际使用)。
判断内存是否有问题,关键要看 RES(常驻物理内存)的实时大小和增长趋势,以及系统是否出现 Swap 频繁交换或 OOM(内存溢出)告警,而不是单纯盯着 VIRT 这个数字。
误区 5:free 很小 = 内存不够
再看物理内存的整体使用情况:
KiB Mem: 263973326 total, 8088860 free, 28235512 buff/cache, 30766036 a vail Mem如果只盯着 free 内存只有约 8GB,可能会觉得内存快用完了。但 Linux 内核的内存管理哲学是“不用白不用”,它会尽可能利用空闲内存来做磁盘缓存(buff/cache),以提升文件读写性能。这部分缓存内存可以被应用程序快速回收。
真正需要关注的现代指标是 a vail Mem(可用内存)。这里 a vail 大约有 30GB,说明系统实际上仍有充足的内存可供新应用程序分配使用,完全不必紧张。
误区 6:top 能直接定位“根因”
最后,必须清醒认识到 top 命令的局限性。从这张截图里,我们最多能得出“MySQL 进程正在大量消耗 CPU 资源”的结论,但完全无法知道“为什么消耗这么高”。
是慢查询泛滥?是锁等待严重?还是连接数过多或配置不当?要找到性能问题的根本原因,必须深入 MySQL 内部,借助慢查询日志、SHOW PROCESSLIST、EXPLAIN 分析执行计划等工具。top 只是一个出色的系统“仪表盘”,它能告诉你哪个指标不对劲,但深入诊断和维修的“工具箱”在别处。
正确使用 top 命令的姿势
总结一下,想要真正读懂 top 命令的输出,你需要养成这几个习惯:
- 先确认战场规模: 运行
lscpu或nproc命令,首先搞清楚服务器有多少个 CPU 逻辑核心。这是解读一切百分比和负载数据的基础前提。 - 理性看待系统负载: 将 load average 数值与 CPU 总核心数进行对比。只要负载值没有持续、数倍地超过核心数,通常就不必过度焦虑。
- 拥抱多核现实: 记住,%CPU > 100% 在多核服务器时代是常态,这恰恰说明应用程序在并行化方面做得好,能够充分利用多核资源。
- 关注真正的可用内存: 判断内存健康度,请优先看
a vail Mem指标,而不是单纯看free或buff/cache。 - 结合上下文分析: 不要孤立地看某一个指标,要将 %CPU、%MEM、load average、CPU状态(us/sy/id/wa)等结合起来,形成对系统整体健康状况的综合判断。
掌握这些核心要点,你才算真正看懂了 top 这个 Linux 系统监控“老兵”所要传达的真实信息,从而做出准确的性能诊断。




