一、|的本质:一个内核缓冲区 + 两个文件描述符
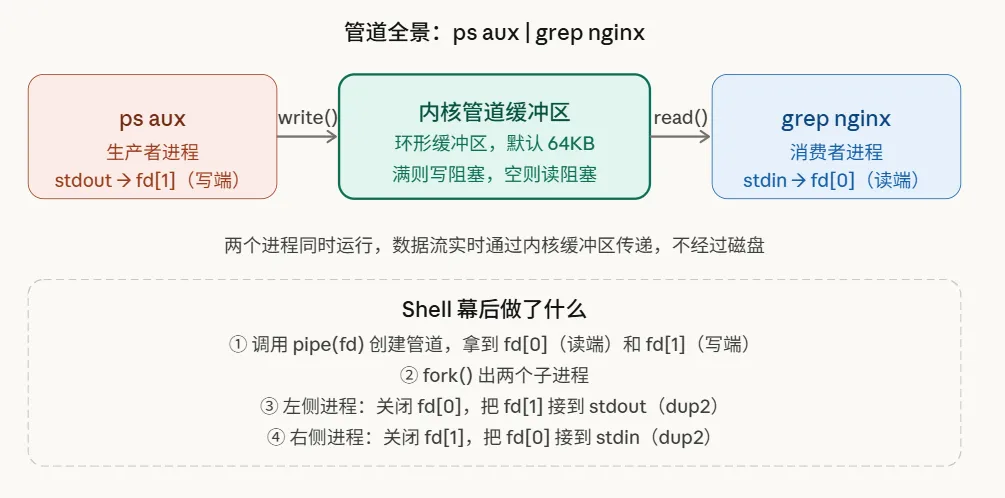
先明确一个核心结论:我们日常敲下的那个竖线“|”,其本质是内核维护的一块环形内存缓冲区,默认大小是64KB。
它的工作模式很直观:左边的进程负责往这个缓冲区里写入数据,右边的进程则从中读取。内核通过提供两个文件描述符——一个指向写端,一个指向读端——来巧妙地连接起这两个独立的进程。
理解管道,关键在于把握住下面几个事实,记住了它们,整个机制就清晰了:
首先,管道两端的进程是同时运行的,并非左边命令完全执行完毕,右边才开始。想象一下ps一边在生成进程列表,grep就已经在实时地消费和过滤这些数据了。
其次,数据流动全程发生在内核内存中,完全不经过磁盘。这解释了为什么管道操作的速度,远比先将输出重定向到临时文件再读取要快得多。
最后,管道是单向的。数据只能从写端流向读端,这个方向是固定的,无法反向通信。
二、Shell 怎么接管|:pipe()+fork()+dup2()
在用户层面,shell 通过三个精妙的系统调用组合,实现了“|”这个魔法:
// 这就是 shell 处理 “ps aux | grep nginx” 的核心逻辑
int fd[2];
pipe(fd); // fd[0] = 读端,fd[1] = 写端
if (fork() == 0) { // 子进程 1:执行左侧命令(ps aux)
close(fd[0]); // 不需要读端
dup2(fd[1], STDOUT_FILENO); // 把 stdout 重定向到管道写端
close(fd[1]);
execvp(“ps”, args_ps); // 执行 ps,输出自动进管道
}
if (fork() == 0) { // 子进程 2:执行右侧命令(grep nginx)
close(fd[1]); // 不需要写端
dup2(fd[0], STDIN_FILENO); // 把 stdin 重定向到管道读端
close(fd[0]);
execvp(“grep”, args_grep); // 执行 grep,输入自动从管道读
}
// 父进程(shell)关闭两端,等待子进程结束
close(fd[0]); close(fd[1]);
wait(NULL); wait(NULL);这里面的关键先生是dup2。它的作用是把管道的文件描述符复制到进程的标准输入或标准输出位置。经过这番“偷梁换柱”之后,ps和grep这两个命令对自己正在与管道通信的事实毫不知情——它们依然只是按部就班地向stdout输出、从stdin读取,管道对它们而言是完全透明的。
这也顺带解释了为什么绝大多数Linux命令都能通过管道无缝协作:因为它们的设计都遵循了“从标准输入读取,向标准输出写入”这一公约,而shell要做的,就是悄悄地把管道插入到它们中间。
三、管道链:多个|串联发生了什么?
来看一个更复杂的例子:
cat log | awk ‘{print $1}’ | sort | uniq -c | sort -rn | head -10这条命令链涉及6个进程和5根管道,并且它们全部同时运行,数据像流水线一样逐级传递:
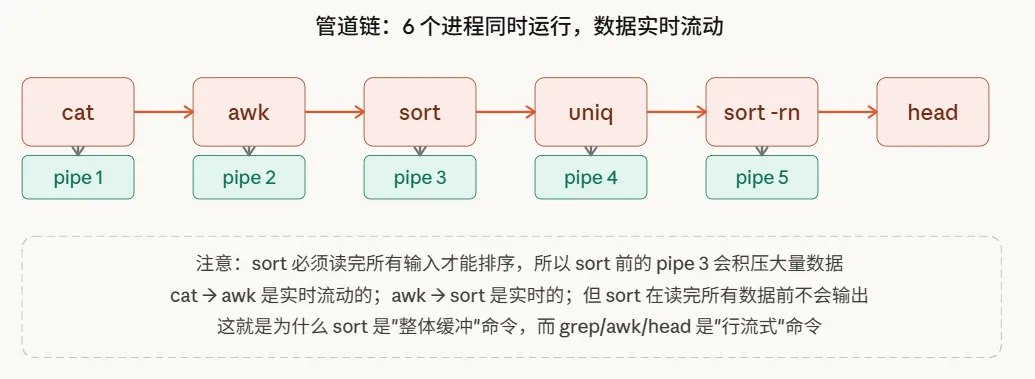
这里藏着一个容易被忽略的细节:sort命令不是流式的。
像grep、awk、head这类命令,可以做到读一行处理一行,实现真正的实时流动。但sort不同,它必须收集完所有的输入数据之后,才能进行排序操作。因此,在sort之前的那根管道里,数据会持续累积,直到上游进程结束并关闭了管道的写端,sort才会开始工作,然后将排序后的结果输出给下游。
这就是为什么在处理超大文件时,遇到 ... | sort | ... 这样的组合,往往会先经历一段看似“卡住”的等待期,然后才突然快速输出结果。
四、管道的阻塞行为:写满了会怎样?
管道缓冲区只有64KB,这就引出一个问题:如果生产数据的一方太快,而消费的一方太慢,会发生什么?
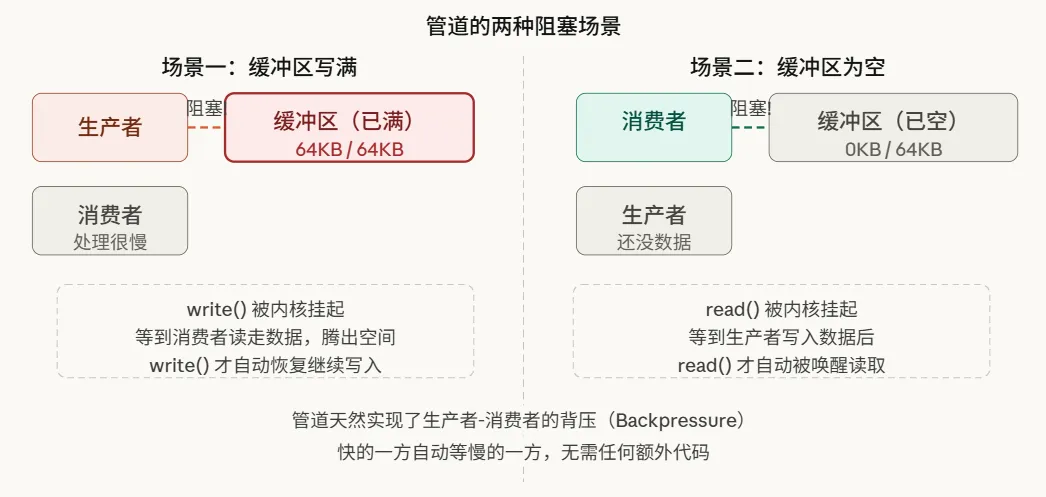
这个自动的“背压”机制,堪称管道设计中最精妙的一环:开发者无需编写任何显式的同步代码,速度快的一方会自动等待慢的一方,内核已经默默处理好了一切协调工作。
当然,这个64KB的默认大小并非铁律。我们可以使用fcntl系统调用来查看或调整它:
int pipe_fd[2];
pipe(pipe_fd);
// 查看管道缓冲区容量
int cap = fcntl(pipe_fd[1], F_GETPIPE_SZ);
printf(“管道容量: %d 字节\n”, cap); // 默认 65536 (64KB)
// 调大管道缓冲区(需要有权限)
fcntl(pipe_fd[1], F_SETPIPE_SZ, 1024 * 1024); // 设为 1MB从Linux 2.6.11内核开始,管道默认容量为64KB,其最大值受/proc/sys/fs/pipe-max-size控制,通常可以设置到1MB。
五、匿名管道 vs 命名管道(FIFO)
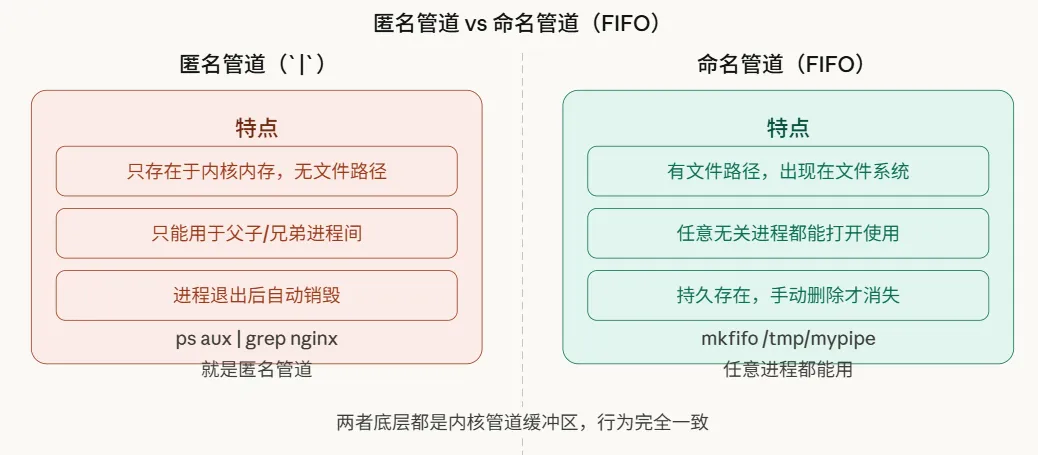
到目前为止,我们讨论的都是匿名管道——也就是用“|”创建的那种。它只存在于内存中,并且只能用于具有亲缘关系(例如父子进程)的进程间通信。
那么,两个完全独立的、没有亲缘关系的进程想要通信,该怎么办?答案就是命名管道,也称为FIFO:
命名管道的使用方式很像一个特殊的文件:
# 终端 1:创建命名管道,并等待读取数据
mkfifo /tmp/mypipe
cat /tmp/mypipe # 命令会在这里阻塞,等待数据写入
# 终端 2:向管道写入数据(这是另一个完全无关的进程)
echo “hello from process B” > /tmp/mypipe
# 此时,终端 1 会立刻看到输出
# 使用完毕后记得清理
rm /tmp/mypipe在C程序中,可以这样操作:
// 创建命名管道
mkfifo(“/tmp/mypipe”, 0666);
// 进程 A:打开并写入
int wfd = open(“/tmp/mypipe”, O_WRONLY);
write(wfd, “hello”, 5);
// 进程 B:打开并读取(两个进程可以完全独立启动)
int rfd = open(“/tmp/mypipe”, O_RDONLY);
char buf[64];
read(rfd, buf, sizeof(buf));使用ls -l /tmp/mypipe命令查看时,会看到文件类型标记为p(代表pipe),这是区分命名管道和普通文件的关键标志。
六、管道的限制与陷阱
尽管管道强大而优雅,但在使用时也有一些“坑”需要留意。
陷阱一:读端关闭后,写端写入会触发SIGPIPE信号
# 一个经典示例
yes | head -5yes命令会无限输出“y”,而head -5在读取5行后就会关闭读端并退出。此时,yes继续向管道写入,就会收到SIGPIPE信号,该信号的默认行为是终止进程——这正是yes命令能正常停止的原因。
在编程时,可以选择忽略此信号,让write()返回错误而非终止进程:
// 忽略 SIGPIPE 信号,改为让 write() 返回 -1 并设置 errno
signal(SIGPIPE, SIG_IGN);
// 或者在 socket 编程中使用 MSG_NOSIGNAL 标志
send(fd, data, len, MSG_NOSIGNAL);陷阱二:管道是字节流,没有消息边界
和Unix Domain Socket的SOCK_STREAM类型一样,管道提供的是连续的字节流服务。如果你分两次写入“hello”和“world”,读端可能一次就读到“helloworld”,也可能分两次读到。应用程序需要自己设计协议(如添加长度头或分隔符)来处理消息边界。
陷阱三:stdout在连接到管道时,缓冲模式可能改变
# 这条命令期望实时输出,但有时会“卡住”一段时间
some_program | grep pattern当some_program的标准输出连接到管道时,glibc库可能会将其缓冲模式从行缓冲自动改为全缓冲(通常为4096字节)。这意味着数据会积攒到一定量才被刷新到管道中。解决方法是在程序中强制设置行缓冲或主动刷新:
// 强制标准输出为行缓冲模式
setvbuf(stdout, NULL, _IOLBF, 0);
// 或者,在关键输出后立即刷新缓冲区
printf(“some output\n”);
fflush(stdout);七、高频面试题精析
1. 管道是如何实现进程间同步的?
管道通过其内核缓冲区,天然实现了一套生产者-消费者同步模型。当缓冲区满时,写操作(write())会阻塞;当缓冲区空时,读操作(read())会阻塞。内核负责在条件满足时唤醒对应的等待进程。这是一种无需应用程序显式加锁的同步机制,其背后由内核的等待队列和调度器共同实现。
2. ls | grep txt里,ls和grep是串行还是并行执行?
它们是并行执行的。Shell通过fork()创建两个子进程,两者同时开始运行。ls向管道写入目录列表数据,grep则从管道读取数据并进行过滤,两者通过管道缓冲区进行速度同步。并非ls全部执行完才启动grep——如果ls遍历的目录很大、速度很慢,grep会阻塞在read()上等待数据,但两个进程在操作系统调度层面都是存活的。
3. 为什么管道只能单向通信?如何实现双向通信?
匿名管道在内核中只维护一个单向的环形缓冲区,自然只能支持单向数据流动。强行反向写入会破坏数据流。要实现双向通信,标准做法是创建两根管道:一根用于A进程到B进程,另一根用于B进程到A进程。这种“双管道”模式正是shell实现双向通信(如|&)或socketpair()系统调用的基础。
八、结语
从一个简单的竖线“|”出发,我们实际上遍历了操作系统提供的一套精密的协作机制:
pipe() 系统调用 → 内核创建 64KB 环形缓冲区
→ fork() 创建两个进程
→ dup2() 把管道接到 stdin/stdout
→ 两进程并发运行,通过缓冲区流式传递数据
→ 满了自动阻塞,空了自动等待,天然背压理解了这个完整的链路,下次再敲下“|”时,你脑海中浮现的将不再是一个简单的符号,而是一幅清晰的数据流动图景。这,或许就是真正掌握一个工具的标志。




