从"粘包"到"通透":一文讲透TCP消息边界问题
几乎每个开发者初涉网络编程时,都会在TCP通信里遭遇那个经典的“灵异事件”——明明客户端分两次发送了"hello"和"world",服务端却一次性收到了"helloworld";或者更让人困惑的,收到了前半截的"hel"和后半截的"loworld"。
很多人第一次遇到这种情况,第一反应是:是不是TCP有bug?其实恰恰相反,这正是TCP设计哲学的体现。搞明白背后的“为什么”,你才能真正掌握如何规避它。

一、TCP 是字节流,不是消息流
理解粘包问题的钥匙,只有这一把。
UDP像是寄信,你投递一个包裹,对方收到的是一个完整的包裹,边界天然分明。而TCP则像是架设了一条源源不断的水管,你这一端往里倒水,对方接到的只是连续的水流,至于你是一次性倒完,还是分几次倒,水流本身并不会告诉你。
来看看字节流与消息流的直观对比:
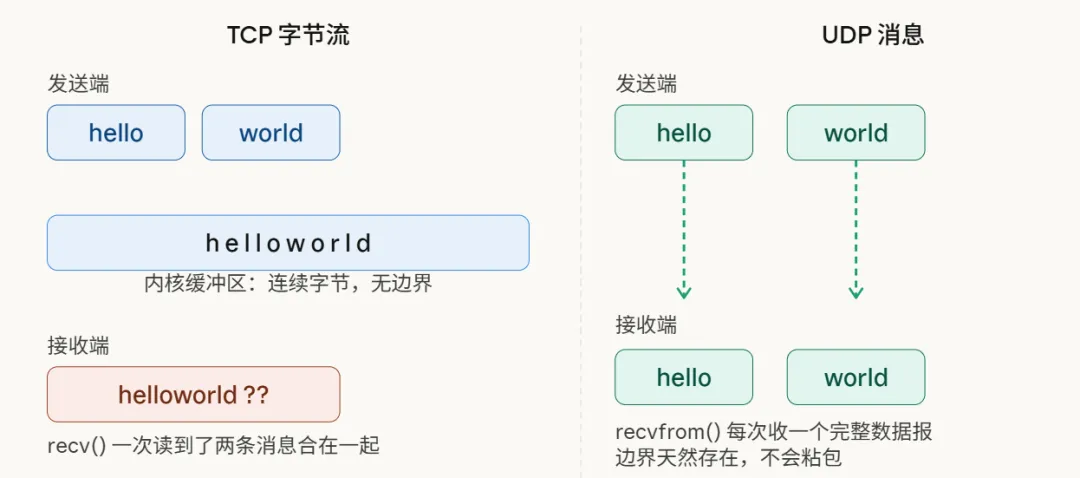
所以,粘包拆包并非故障,而是TCP作为字节流协议的本质特征。TCP的世界里只有“字节序列”,没有“消息”的概念。划分消息边界,是应用层协议必须自己扛起的责任。
二、粘包和拆包,到底是怎么发生的?
无论是粘包还是拆包,根源都是一个:发送方和接收方处理数据的“节奏”没能对齐。
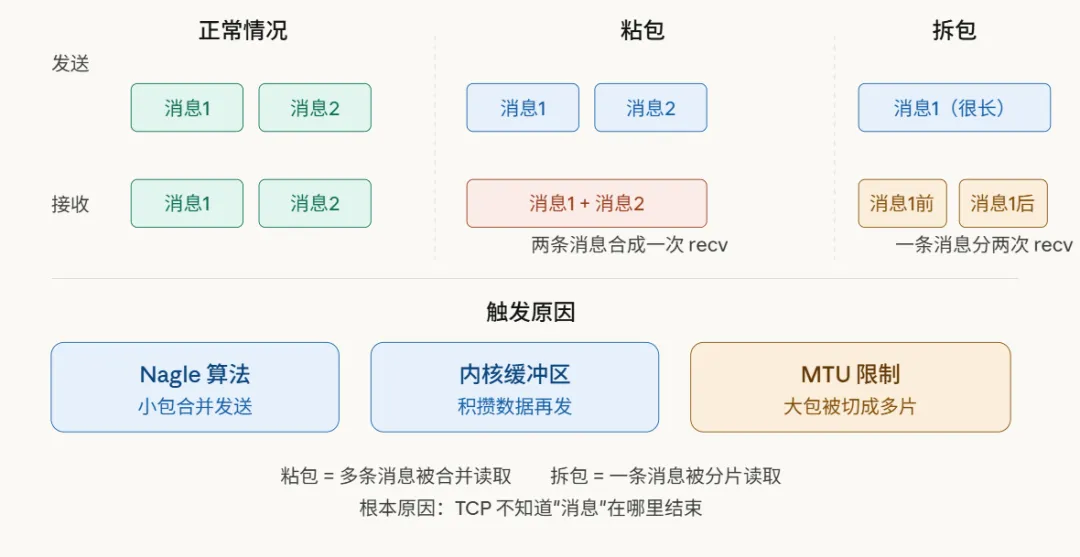
最常见的两个触发场景,其实都情有可原:
其一是Nagle算法。这个TCP默认开启的优化算法,会把多个准备发出的小数据包暂存起来,合并成一个较大的TCP段再发送,旨在减少网络上的小包数量,提升效率。结果就是,你调用两次send发出去的消息,可能在网络层被合并了,对端一次recv就全部读到了。
其二是MTU限制。网络层的以太网帧通常有1500字节的大小限制(MTU)。如果你的单条消息长度超过了这个值,IP层会自动对其进行分片传输。接收端就可能先收到第一个分片(消息的前半部分),再收到第二个分片(消息的后半部分),从而造成了“拆包”。
三、四种解决方案,逐一图解
1. 方案一:固定长度(定长协议)
最直接的办法:通讯双方提前约定,每条消息都严格采用相同的字节数。消息不足就补零,超过则截断或视为错误。

// 接收端:循环读满 N 字节才处理
#define MSG_LEN 64
ssize_t recv_fixed(int fd, char *buf) {
size_t received = 0;
while (received < MSG_LEN) {
ssize_t n = recv(fd, buf + received, MSG_LEN - received, 0);
if (n <= 0) return n;
received += n;
}
return MSG_LEN;
}
优点显而易见:实现极其简单。缺点也同样明显:当消息长度变化很大时,会造成带宽浪费,灵活性不足。这种方案通常用在消息格式确实固定的场景,比如某些硬件串口协议或标准的金融交易报文。
2. 方案二:特殊分隔符
约定一个(或一组)特殊字符作为消息的结束标志。最简单的比如换行符\n,而实际工程中更常见的是\r\n(CRLF,即回车加换行)。HTTP协议的头部分隔、Redis的RESP协议,采用的都是\r\n。

// 接收端:按 \r\n 读取一行(工程版)
ssize_t recv_line(int fd, char *buf, size_t max) {
size_t i = 0;
char c, prev = 0;
while (i < max - 1) {
ssize_t n = recv(fd, &c, 1, 0);
if (n <= 0) return n;
buf[i++] = c;
if (prev == '\r' && c == '\n') break; // 读到 \r\n,消息结束
prev = c;
}
buf[i] = '\0';
return i;
}
这种方法简单直观,人类可读性好。但它有个硬性要求:消息体内部绝对不能出现分隔符字符,否则会导致误判。因此,处理二进制数据时,必须进行转义(escaping)处理。
3. 方案三:消息头 + 消息体(TLV / Length-Value)
这是工程实践中应用最广泛的方案。它的思路是:在真正的消息体前面,附加一个固定长度的“消息头”,这个头里最重要的信息,就是声明后续消息体的长度。接收方先读固定长度的头,解析出长度值,再精确读取相应字节数的消息体。
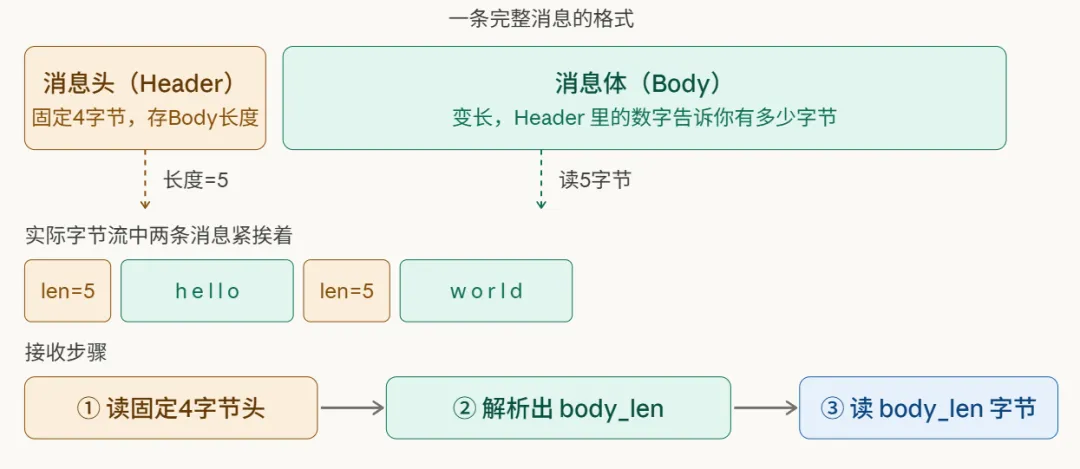
像Google的Protobuf、Apache Thrift以及众多自研的RPC框架,底层都采用了这一思路。代码实现起来逻辑也非常清晰:
// 消息头结构
typedef struct {
uint32_t body_len; // 消息体长度(网络字节序)
} MsgHeader;
// 发送端:先发头,再发体
int send_msg(int fd, const char *body, uint32_t len) {
MsgHeader hdr = { .body_len = htonl(len) };
send(fd, &hdr, sizeof(hdr), 0);
send(fd, body, len, 0);
return 0;
}
// 接收端:先读头,再按长度读体
int recv_msg(int fd, char *buf, uint32_t max_len) {
MsgHeader hdr;
// 先读固定 4 字节头
if (recv_exact(fd, &hdr, sizeof(hdr)) <= 0) return -1;
uint32_t body_len = ntohl(hdr.body_len);
if (body_len > max_len) return -1;
// 再读指定长度的体
return recv_exact(fd, buf, body_len);
}
// 辅助函数:循环读满指定字节数
ssize_t recv_exact(int fd, void *buf, size_t len) {
size_t done = 0;
while (done < len) {
ssize_t n = recv(fd, (char*)buf + done, len - done, 0);
if (n <= 0) return n;
done += n;
}
return done;
}
4. 方案四:HTTP 的做法(综合应用)
HTTP/1.1协议堪称一个优雅的综合案例,它巧妙结合了分隔符和长度前缀两种方案:

我们来拆解一下HTTP的智慧:
首先,请求头中的每个字段之间,使用\r\n分隔(分隔符方案)。
其次,头部与消息体之间,用一个空行\r\n\r\n来划清界限(还是分隔符方案)。
最后,消息体的实际长度,由头部的`Content-Length`字段明确给出(长度前缀方案)。
这种组合拳,既保证了协议的可读性,又精确地定义了边界,是解决混合类型数据的典范。
四、四种方案横向对比
如何选择?这里有个实用的口诀:处理二进制数据,优先考虑TLV(长度前缀);如果是纯文本协议,分隔符简单够用;遇到像HTTP这种头部文本、正文混合的场景,那就学习它的组合方案。
五、粘包问题的常见错误写法
了解了正确方案,不妨再看看那些容易踩进去的坑,避免重蹈覆辙:
// 错误写法:recv 一次就认为收到了完整消息
char buf[1024];
int n = recv(fd, buf, sizeof(buf), 0);
process_message(buf, n); // 危险!n 可能只是消息的一部分
正确的做法是,配合长度前缀信息,坚持循环读满所需字节:
// 正确写法:配合长度前缀,循环读满
int recv_exact(int fd, void *buf, size_t need) {
size_t got = 0;
while (got < need) {
ssize_t n = recv(fd, (char*)buf + got, need - got, 0);
if (n <= 0) return -1; // 连接关闭或出错
got += n;
}
return 0;
}
另一个高频错误是忘记网络字节序转换。消息头中的长度字段,必须在发送前用`htonl`转换为网络字节序(大端),在接收后用`ntohl`转换回主机字节序。忽略这一步,在不同字节序的机器间通信就会产生灾难性错误:
// 发送时:主机序 → 网络序(大端)
uint32_t net_len = htonl(body_len);
// 接收时:网络序 → 主机序
uint32_t body_len = ntohl(net_len);
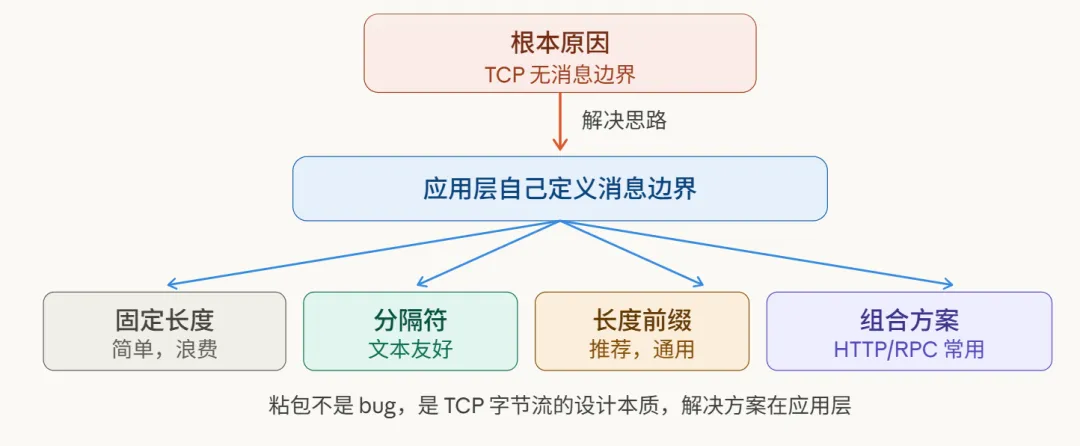
六、一张图总结:粘包的本质和解法
七、结语
说到底,粘包问题可以拆解为两个核心:
第一,理解“为什么”:因为TCP是面向字节流的协议,它只保证字节的可靠、有序传输,而将消息语义边界的界定工作,完全交给了应用层。
第二,知道“怎么办”:应用层需要自行定义消息边界。无非四种主流方案——固定长度、特殊分隔符、长度前缀、或像HTTP那样的组合方案,根据实际场景四选一即可。
对于绝大多数工程应用,长度前缀(TLV)方案因其通用、高效且不受消息内容限制,成为首选推荐。记住,下次设计TCP通信时,第一个要明确的决策就是:“我使用哪种方案来界定消息边界?”把这个根本问题想清楚,粘包这个坑,你就真正跨过去了。




