一、CPU 缓存:速度差异大到令人震惊
CPU的运算速度有多快?快到内存根本跟不上。如果每次运算都得老老实实等内存读写完成,那CPU绝大部分时间都只能空转,性能也就无从谈起了。所以,现代CPU都在自己和内存之间加了好几层缓存,用来弥补这个巨大的速度鸿沟。
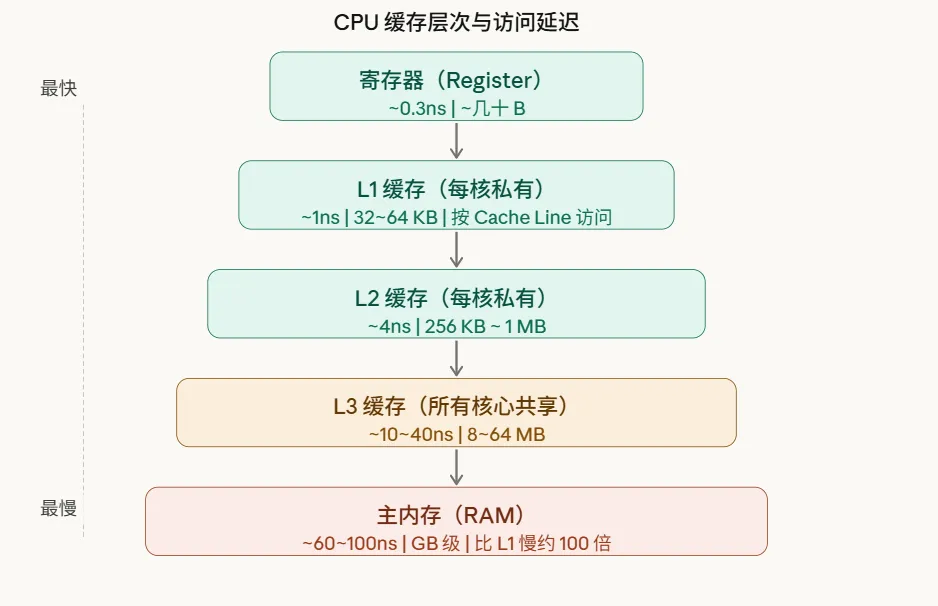
从L1缓存到主内存,延迟差距能达到惊人的100倍左右。这也就解释了,为什么写出“缓存友好”的代码,性能提升动辄就是数倍甚至数十倍。
这里有个关键概念:缓存是以“缓存行”为单位来加载数据的,通常是64字节。这意味着,当你访问一个简单的int变量时,CPU会“顺手”把它周围总共64字节的数据都一块儿加载进来。明白了这一点,你就能理解为什么顺序访问数组会比随机访问快那么多——前者是在高效利用已经加载到缓存的整块数据,而后者则可能频繁触发缓存缺失。
二、多核缓存的麻烦:我改的数据,你看不见
在单核时代,缓存机制堪称完美。但到了多核时代,麻烦就来了。
每个核心通常都有自己私有的L1和L2缓存。那么问题来了:如果两个核心都缓存了同一个变量,其中一个核心修改了它,另一个核心怎么能及时知道这个变化呢?
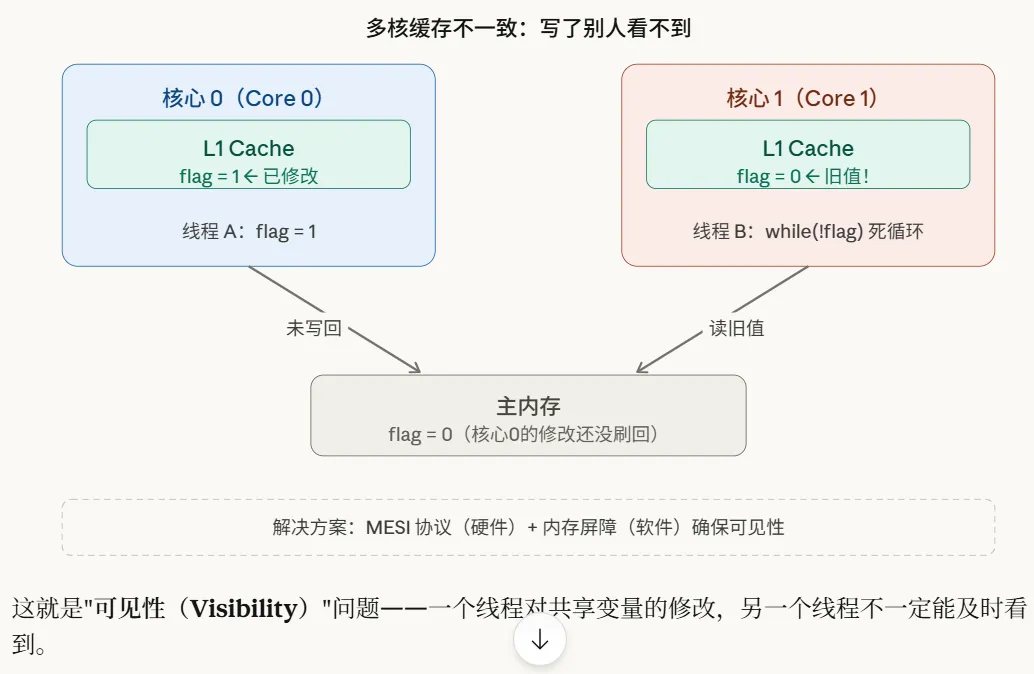
这就是典型的“可见性”问题——一个线程对共享变量的修改,另一个线程不一定能立刻,甚至不一定能看到。
解决可见性问题,其实有两个层面:
硬件层面,主要依靠MESI这类缓存一致性协议,由CPU自动处理,但存在一定延迟。软件层面,就需要我们主动介入,使用“内存屏障”来强制刷新缓存、禁止指令重排。而后者,正是我们今天要讨论的核心。
三、volatile:能做什么,不能做什么
在C/C++开发中,一个非常普遍且隐蔽的错误,就是试图用volatile关键字来解决多线程间的可见性问题。
必须澄清一点:volatile的本意是告诉编译器:“这个变量可能会被外部因素(比如硬件)意外改变,别对它做优化,每次读写都老老实实去内存操作。”它的正确使用场景非常明确:内存映射的I/O寄存器、setjmp/longjmp场景,或者防止编译器把空循环优化掉。
但在多线程同步这个领域,volatile有两个致命的缺陷。
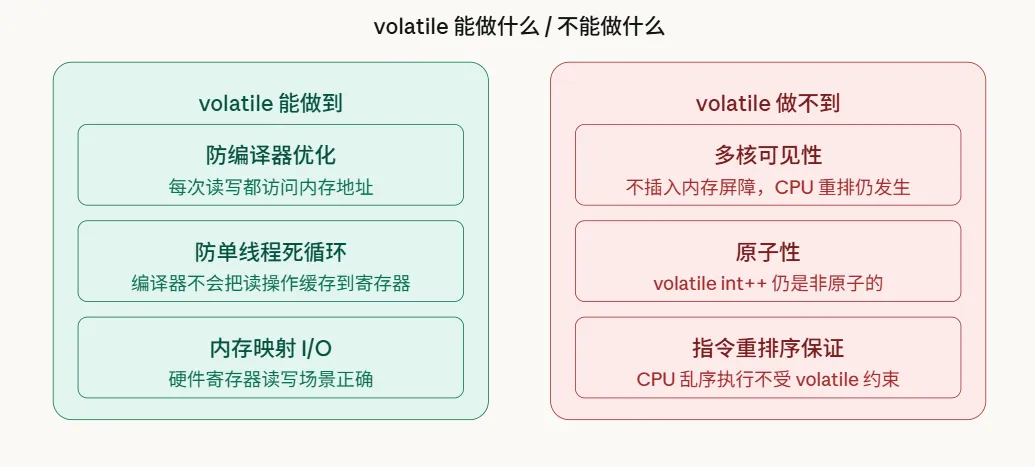
简单来说,volatile只管得住编译器,让它别优化代码;但它管不了CPU的乱序执行,也不会自动插入任何内存屏障。
来看一个典型的错误用法:
volatile bool ready = false;
int data = 0;
// 线程 A
data = 42;
ready = true; // volatile 写
// 线程 B
while (!ready); // volatile 读
printf("%d\n", data); // 可能打印 0 !这段代码看起来逻辑清晰,但实际上线程B完全有可能打印出0。原因有两个:首先,CPU为了效率可能会乱序执行指令,线程A中的ready = true完全有可能在data = 42之前执行。其次,即便ready被声明为volatile,保证了它自身的读写不被优化,但非volatile的data的修改,对其他线程的可见时机依然无法保证。
四、内存屏障:告诉CPU“别乱来”
那么,真正的解决方案是什么?答案是内存屏障。
内存屏障是一条特殊的CPU指令,它主要干两件事:第一,确保屏障之前的所有内存操作,都在屏障之后的操作开始之前完成。第二,强制将缓存行刷新到内存,或者使其他核心中对应的缓存行失效。
内存屏障通常分为三种类型:
Store Barrier(写屏障):确保屏障前的所有写操作完成后,才能执行屏障后的写操作。
Load Barrier(读屏障) :确保屏障前的所有读操作完成后,才能执行屏障后的读操作。
Full Barrier(全屏障) :同时具备以上两种屏障的效果。在x86汇编中,MFENCE指令就是一个全屏障。不过,我们写C++时通常不需要直接操作汇编,因为标准库已经提供了更优雅的封装——std::atomic。
五、std::atomic:既保证原子性,又保证可见性
std::atomic为我们提供了两个核心保证:一是操作的原子性,确保读-改-写过程不可被打断;二是内存顺序,允许我们按需控制内存屏障的强度。
现在,我们用std::atomic来修正前面那个错误的例子:
#include
std::atomic ready{false};
int data = 0;
// 线程 A
data = 42;
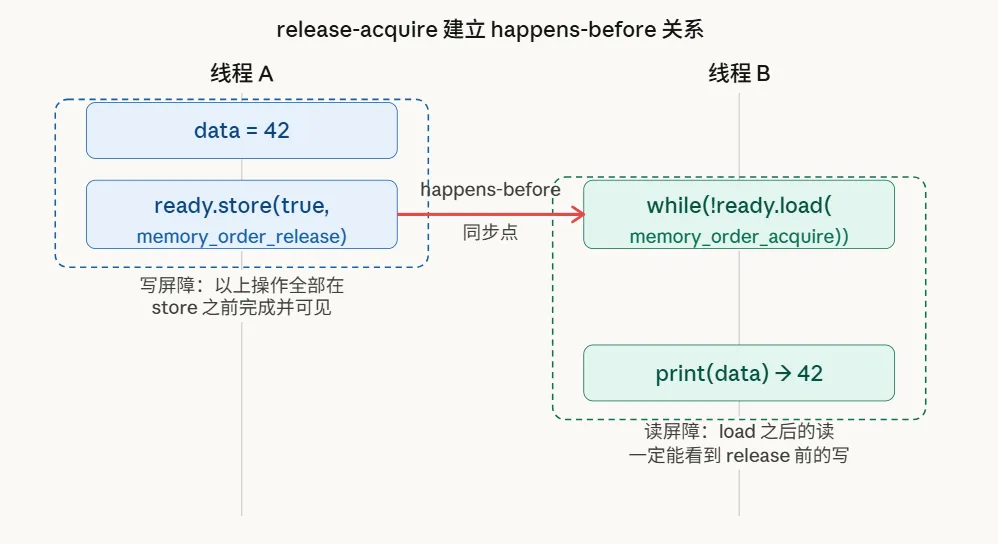
ready.store(true, std::memory_order_release); // 写屏障:保证 data=42 先于 ready=true 对外可见
// 线程 B
while (!ready.load(std::memory_order_acquire)); // 读屏障:保证看到 ready=true 后,也一定能看到 data=42
printf("%d\n", data); // 安全,一定打印 42 这里的关键在于memory_order_release和memory_order_acquire的配对使用。它们共同构成了一个“同步点”,建立了一种“happens-before”关系:所有在release操作之前发生的写操作,对于看到这个release操作结果的acquire操作来说,都保证是可见的。
六、memory_order 选项速查
std::atomic提供了6种内存顺序选项,强度从弱到强。这里列举三种最常用的模式:
// 1. 简单计数器(只要求原子性,不要求顺序)
std::atomic cnt{0};
cnt.fetch_add(1, std::memory_order_relaxed);
// 2. 发布-订阅标志(经典的 release + acquire 配对)
flag.store(true, std::memory_order_release); // 发布方
while(!flag.load(std::memory_order_acquire)); // 订阅方
// 3. 默认模式(seq_cst,最安全但稍慢)
std::atomic flag{false};
flag.store(true);
flag.load(); 七、伪共享(False Sharing):缓存行的隐形杀手
聊完了正确性,再来看一个与缓存密切相关的性能陷阱——伪共享。
如果两个逻辑上毫不相干的变量,因为内存地址靠近,恰好落在了同一个64字节的缓存行里,那么当一个线程修改其中一个变量时,会导致整个缓存行失效。这会迫使其他核心中缓存了同一缓存行的线程,不得不重新从内存加载数据,即使它要访问的只是那个没被修改的变量。
对比下面两种写法:
// 危险写法:counter_a 和 counter_b 可能在同一 Cache Line 里
struct {
int counter_a; // 线程 A 频繁修改
int counter_b; // 线程 B 频繁修改
} counters;
// 安全写法:通过 padding 或对齐,让两者各占一个 Cache Line
struct {
alignas(64) int counter_a; // 64字节对齐,独占一个 Cache Line
alignas(64) int counter_b;
} counters;在高并发场景下,修复伪共享问题,有时能带来5到10倍的性能提升,效果非常显著。
八、高频面试题精析
Q:volatile和std::atomic的本质区别?
volatile仅作用于编译器,防止优化,但无法约束CPU的乱序执行,不保证多核间的可见性,更不保证原子性。std::atomic则在提供原子操作的同时,通过内存屏障保证了可见性和顺序性,是多线程数据同步的正确工具。
Q:seq_cst为什么是默认值?性能开销有多大?
seq_cst(顺序一致性)提供了最强的保证,所有线程看到的原子操作顺序都是一致的,最安全也最易于理解。在x86架构上,一次seq_cst存储操作会生成LOCK XCHG指令,相比relaxed或release存储,大约会慢5到20纳秒。对于非高频的关键路径操作,这个开销通常可以接受;只有在极端性能敏感的场景下,才需要考虑使用更宽松的内存顺序。
Q:什么是 Cache Line,它和性能有什么关系?
Cache Line是CPU缓存数据的基本单位,通常是64字节。顺序访问时,一次加载就能填满后续多个数据的缓存,效率极高;而随机访问则可能每次都需要从内存加载新的缓存行,造成大量的缓存缺失,两者性能差异可达数十倍。理解Cache Line是编写高性能代码的基础。
Q:为什么relaxed不能用来做线程间同步?
memory_order_relaxed只保证单个操作的原子性,不插入任何内存屏障,也不禁止编译器和CPU的重排序。这意味着,一个线程用relaxed写入的标志,另一个线程可能永远看不到更新,或者看到标志更新时,与之相关的其他数据却还没更新。只有release/acquire或seq_cst这类能建立“happens-before”关系的顺序,才能用于可靠的线程间同步。
九、结语
让我们把整条逻辑链再梳理一遍:
CPU 缓存为了速度 → 多核各自缓存导致不一致
→ volatile 只管编译器,管不了 CPU
→ 内存屏障才是真正的解决方案
→ std::atomic 把屏障封装好,按需选 memory_order
→ 顺手还要当心 false sharing 这个隐形杀手说到底,以后遇到多线程共享数据,先问自己两个问题:第一,这个操作需要原子性吗?如果需要,就用std::atomic。第二,操作之间有没有顺序依赖?如果有,就选择合适的memory_order。
记住,别再拿volatile来做多线程同步了。




