【LLM】Openclaw测试评估PinchBench
一、OpenClaw AI代码助手专属评测:PinchBench基准测试深度解析
为AI编程助手挑选核心大模型,常常面临信息不对称的困境。厂商公布的性能指标与实际处理复杂编码任务的表现,可能存在显著落差。如今,一项名为PinchBench(https://pinchbench.com)的专业基准测试提供了权威的“导航图”。它的设计目标极为务实:通过在不同AI模型上执行同一套真实世界任务,从**任务成功率、响应速度、运行成本**三大核心维度进行量化对比,最终为OpenClaw开发者与使用者提供一份基于真实数据的模型选型决策指南。
该项目采用清晰的开源架构,易于复现与验证:其基于Next.js、React、Tailwind构建的排行榜网页代码存放于pinchbench/leaderboard仓库;负责具体测试运行、任务定义及评分逻辑的核心引擎位于pinchbench/skill;而为排行榜提供动态数据支持的Cloudflare Workers后端API,源码则公开在pinchbench/api。
那么,当前的评测结果揭示出哪些趋势?最新数据颇具启发性。在处理涵盖OpenClaw典型场景的综合任务成功率排名中,**Gemini 3 Flash 以95.1%的惊人通过率拔得头筹**。位列其后的是minimax-m2.1(93.6%)和kimi-k2.5(93.4%)。备受业界期待的Claude Sonnet 4.5取得了92.7%的成绩,而GPT-4o则为85.2%。
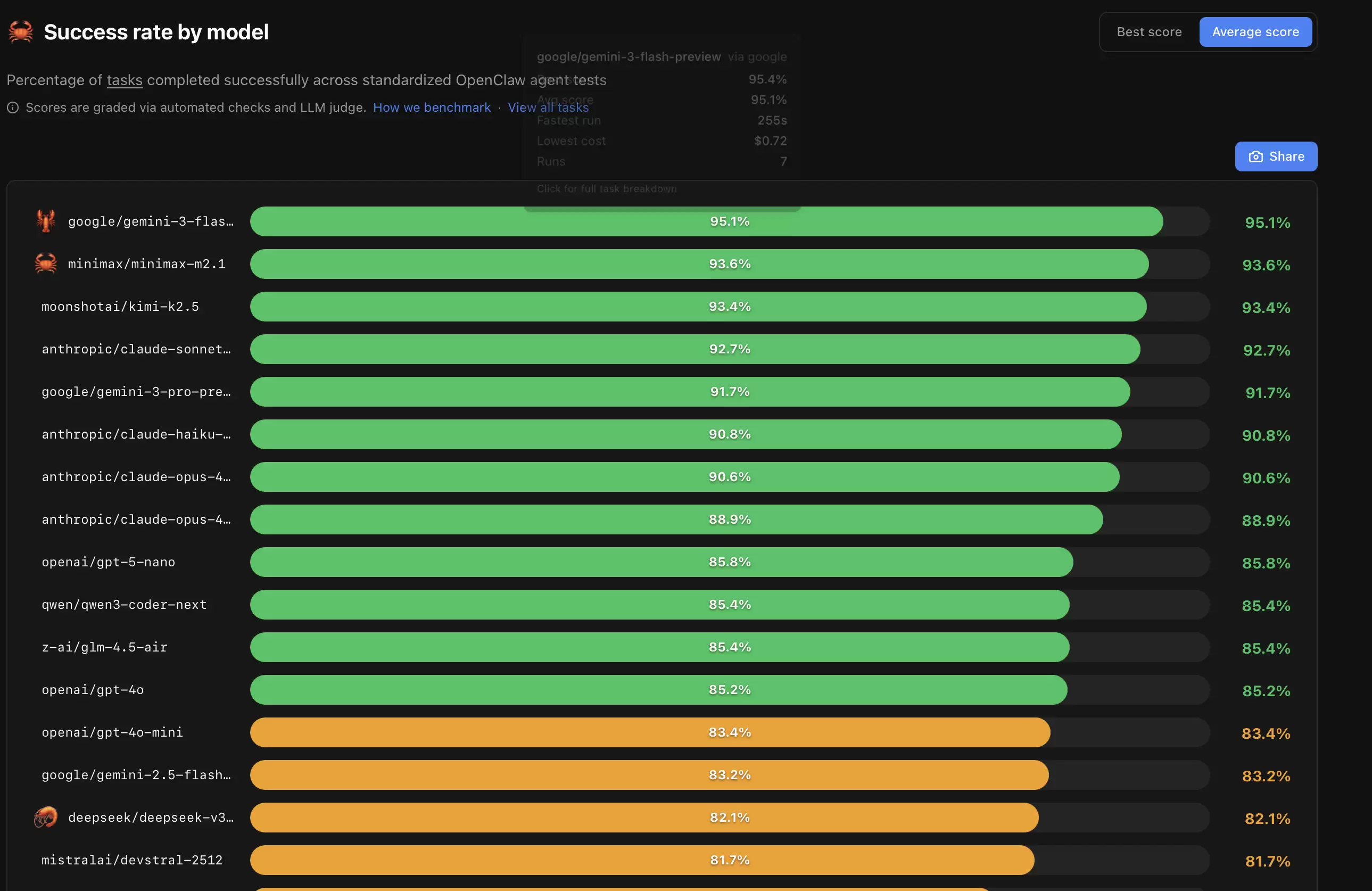
当然,单纯比较总分并不能完整理解模型的优劣。关键在于深入理解评测框架的构建逻辑,尤其是构成其基石的23个实战化任务。所有任务均以包含YAML前置元数据的Markdown文件形式,明确定义于pinchbench/skill仓库中。每一份任务说明书都堪称详尽,必须包含五大关键组成部分:**原始提示词、期望的行为输出、详细的评分标准、自动化检查脚本、以及LLM评审规则**。
这23项任务覆盖了从基础到高阶的多元化真实应用场景,可系统性地归类为以下几大能力域:
1. 评测任务体系全景概览
任务设计紧密贴合开发者日常实际工作流,绝非脱离实际的抽象题目。它们全面覆盖了简单指令理解、复杂代码生成、技术内容创作、结构化数据处理、多步骤工作流编排等核心需求。例如,你需要AI助手生成一份可导入的日历事件文件、查询并整理实时金融市场数据、归纳总结长篇技术PDF,乃至构建一个完整的API调用流水线。这些正是开发者期待AI编程伙伴能够高效、准确完成的具体工作。
2. 评分机制详解:如何平衡客观与主观评价?
如何对这些复杂多样的任务输出进行公正评分?PinchBench创新性地采用了三种评分类型,巧妙融合了机器判定的客观性与人类评估的灵活性:
自动化评分:通过预设的Python校验函数,直接检查工作区生成的文件、执行日志等客观产物。例如,验证生成的ICS文件格式是否标准、脚本执行结果是否符合预期,判断清晰明确。
LLM评审:针对博客撰写、文档摘要等输出质量难以量化衡量的任务,则启用Claude Opus担任“主评审官”,依据预先设定的细致规则,对内容的完整性、专业性与语言流畅度进行主观质量评估。
混合评分:面对最为复杂的综合性任务,则结合上述两种方式。首先使用自动化脚本验证核心结果是否正确,再通过LLM评估整个工作流程的逻辑合理性及输出的综合质量,实现多维度、立体化的考核。
3. 23项实战任务深度解读
这部分是基准测试含金量的核心体现。逐一审视这些任务的具体要求,即可深刻理解评测的广度与深度:
- Sanity Check (✅, Automated): 基础功能验收测试,验证智能体能否正确理解简单指令并做出符合预期的问候回应。
- Calendar Event Creation (📅, Automated): 解析自然语言描述,生成包含准确日期时间、参与者、地点及描述的有效ICS格式日历文件。
- Stock Price Research (📈, Automated): 利用联网搜索工具查询指定股票代码的最新交易价格,生成格式规范、包含股价、日期及简要市场分析的研究报告。
- Blog Post Writing (✍️, LLM Judge): 针对给定技术主题,撰写一篇约500字、结构清晰、论点明确并有实例支撑的Markdown格式博客文章。
- Weather Script Creation (🌤️, Automated): 编写一个健壮、可维护的Python脚本,实现从公开天气API获取数据、解析JSON响应,且必须包含完善的错误处理机制。
- Document Summarization (📄, LLM Judge): 阅读一份提供的技术或产品文档,撰写三段式精炼摘要,准确捕捉文档的核心主题与关键结论。
- Tech Conference Research (🎤, LLM Judge): 调研并整理出5个真实存在、即将举办的国际科技会议,信息需包含准确的会议全称、举办日期、城市地点及官方网站链接。
- Professional Email Drafting (✉️, LLM Judge): 撰写一封礼貌、得体且专业的会议邀请婉拒邮件,旨在维系良好的商务关系,并提供具可行性的后续合作建议。
- Memory Retrieval from Context (🧠, Automated): 从项目上下文或笔记文件中提取特定信息(如关键日期、项目成员、采用的技术栈),并据此准确回答相关问题。
- File Structure Creation (📁, Automated): 创建标准化的软件项目目录结构,包括src源码目录、规范的README.md文件、.gitignore文件,并为其填充符合最佳实践的示例内容。
- Multi-step API Workflow (🔄, Hybrid): 读取提供的JSON或YAML配置文件,提取API端点与认证参数,编写Python脚本完成完整的接口调用与数据处理,并记录详细的操作日志。
- Install ClawdHub Skill (🔌, Automated): 从OpenClaw官方技能库中,精准安装一个指定名称的技能包,并验证其已成功安装且功能可用。
- Search and Install Skill (🔍, Automated): 在技能库中搜索与“天气”功能相关的所有技能,识别出最适配当前环境的一个版本,并完成其安装与基础验证。
- AI Image Generation (🎨, Hybrid): 通过集成的外部AI绘图工具或API,根据给定的文本描述生成符合要求的图片,并将输出图像正确保存至指定文件路径。
- Humanize AI-Generated Blog (🤖, LLM Judge): 调用“文章人性化改写”技能,将一段生硬、机械的AI生成文本,转化为自然流畅、富有情感和个性的人类风格文章。
- Daily Research Summary (📊, LLM Judge): 综合分析多份独立的行业研究简报或报告,撰写一份逻辑连贯的每日研究汇总,提炼出跨文档的核心趋势与共性发现。
- Email Inbox Triage (📬, Hybrid): 模拟处理收件箱中的多封邮件,根据预设的紧急程度与业务重要性进行智能排序与分类,并生成一份结构清晰的邮件优先级处理报告。
- Email Search and Summarization (🔎, Hybrid): 在历史邮件归档中,检索所有与某个特定项目或主题相关的邮件,并对检索到的邮件内容进行归纳性总结,提取关键决策与行动项。
- Competitive Market Research (🏢, Hybrid): 调研企业级应用性能监控(APM)或类似细分领域的市场竞争态势,识别出该领域的主要竞争者,并分析各自的核心产品优势与市场定位。
- CSV and Excel Summarization (📑, Hybrid): 分析提供的CSV表格与Excel工作簿数据,提取关键指标、趋势或异常点,并生成一份聚焦核心洞察的数据分析摘要。
- ELI5 PDF Summarization (👶, LLM Judge): 阅读一份复杂的专业技术PDF文档,使用极其通俗易懂的语言和生动形象的比喻,完成一份“让五岁孩子也能听懂”的概念摘要。
- OpenClaw Report Comprehension (📖, Automated): 阅读一份关于OpenClaw的专项研究报告,从中提取指定的技术参数、性能数据或结论,并准确回答基于报告细节提出的具体问题。
- Second Brain Knowledge Persistence (💾, Hybrid): 将对话中的关键知识点或决策信息,持久化存储至智能体的记忆模块中,并在后续多轮交互中,能够准确地从长期记忆中检索并调用这些信息。
可以说,这份详尽的任务清单本身,就是一份极具价值的“AI智能体核心能力需求蓝图”。PinchBench通过这样一套公开透明、紧密贴合实战的标准化评测体系,为客观衡量与横向对比不同大语言模型在OpenClaw生态中的真实应用能力,建立了一个可靠且极具参考价值的评估坐标系。
参考资料
[1] PinchBench官方网站: https://pinchbench.com
相关攻略

在开源大语言模型蓬勃发展的当下,开发者和研究人员如何高效、客观地评估并挑选合适的模型,已成为一项关键挑战。一个具备公信力且透明的权威评测榜单,正是拨开技术选型迷雾的核心工具。本文将深入解析业界广泛认可的标杆——Open LLM Leaderboard,帮助您全面了解其价值与应用。 Open LLM

为什么那些在理解和推理上表现出色的多模态大模型(MLLM),一旦被应用于图像检索任务就容易表现失常?研究者们精准地将这一问题的根源归结为“范式冲突”。 这结论初看似乎有悖常理。当MLLM凭借其卓越的图文理解与逻辑推理能力成为AI领域焦点时,将其用于图像检索,特别是需要解析复杂修改指令的组合图像检索(

AI圈这两天又被一个人引爆了。不是Sam Altman,也不是马斯克,而是那个低调、却每次出手都能掀翻桌子的男人——Andrej Karpathy。 这次,他做了一件看起来更“朴素”的事:公开了自己的知识管理方式。就这么简单?没错。但恰恰是这份“简单”,让整个开发者社区炸了锅。他在X上随手发的一条帖

在完成环境搭建与OpenClaw安装,并扫清常见配置障碍后,我们即将进入核心应用阶段。然而,在动手执行具体指令前,有一个看似基础却至关重要的环节——深入理解OpenClaw的目录结构与文件组织。这一步直接决定了后续使用过程是顺畅高效还是举步维艰。 许多开发者倾向于跳过目录学习直接输入命令,但当遇到任

近期,AI知识管理领域出现了一个值得关注的新范式。它并非一款具体的软件,而是一套关于如何构建持久化知识库的“方法论”与“架构蓝图”。这个由知名AI研究者Andrej Karpathy以开源“想法文件”形式发布的LLM Wiki概念,旨在解决传统AI知识管理中的一个核心痛点:如何让知识真正沉淀并持续进
热门专题







热门推荐

Excel多表数据整合:四种高效方法详解 在日常办公与数据分析中,我们经常需要处理分散在不同表格中的数据。销售业绩、客户资料、财务流水等信息往往各自独立,如何快速、准确地将它们合并为一份完整的视图,是提升工作效率的关键。本文将系统介绍Excel中四种实用的多表数据整合技巧,帮助您轻松应对各类数据合并

ignore-error 1 " uploadprocessed= "true "> 1 养蚕全过程概述:从蚕卵到蚕茧的关键步骤 成功养殖家蚕并收获高品质蚕丝,是一个系统化、精细化的管理过程。整个流程环环相扣,涵盖了选种孵化、幼虫饲养、上蔟结茧与采收处理等多个核心阶段。其中,温度与湿度的精准控制、新鲜

《空洞骑士:丝之歌》中红色护符能显著改变角色能力,影响战斗与探索策略。其获取通常需完成高难度挑战或深度探索,例如击败特定敌人、破解环境谜题、完成隐藏任务或与特殊商人交换。了解这些护符的效果与获取方式,有助于玩家规划成长路线,从容应对游戏中的试炼。

MetaGPT产品介绍 在软件开发领域,效率与门槛一直是两个难以兼顾的痛点。MetaGPT的出现,正是为了解决这个问题。它本质上是一个基于多智能体协作框架的AI平台,目标很明确:让用户用最自然的方式——说话,来驱动复杂的软件构建过程。 那么,它具体是如何运作的?我们可以从几个核心维度来看: 多智能体

游戏产业步入高质量发展关键阶段,亟需资源整合与创意孵化平台。2026创新游戏&开发者大会以“创意无限,游启新机”为主题,将于2026年6月11日至12日在杭州举办。大会通过专场分享、项目路演等形式,连接行业从业者与创作者,加速优质创意落地,推动产业协同升级与高质量发展。