中国开源OCR项目霸榜GitHub,狂揽7.3万星全球瞩目
西风 发自 凹非寺
量子位 | 公众号 QbitAI
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
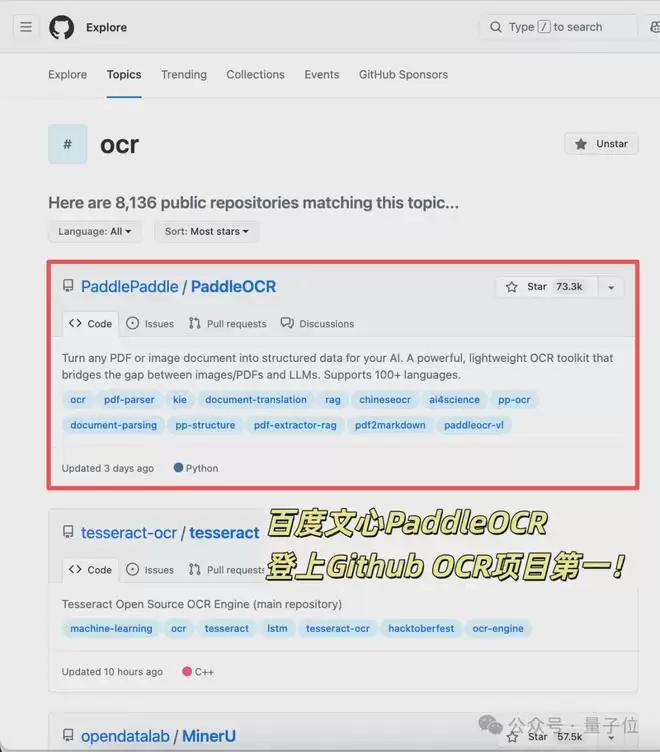
GitHub OCR项目之王刚刚历史性易主。
诞生近40年、统治OCR领域的技术标杆Tesseract OCR,被中国开源拉下王座——
百度文心衍生模型PaddleOCR以73300+Star,正式登顶GitHub全球OCR项目榜,终结谷歌Tesseract OCR长期霸榜局面。
这也是中国开源在这一基础赛道上,首次拿下全球Star第一。
不仅如此,在Hugging Face上,PaddleOCR也长期处于OCR与文档解析领域的头部位置,已经成为全球开发者的必备工具。
消息一出,开发者社区瞬间炸开了锅。
从“跟跑”到“领跑”,大模型时代,中国开源项目正在用实力改写全球竞争格局。
光超越还不够,划重点:
PaddleOCR同步升级服务放出一波福利,官⽹免费每⽇解析⻚数翻番,由1万提升⾄2万。用户还可通过OpenClaw直接调用PaddleOCR Skill,为其接入专业“视觉”能力。
PaddleOCR OCEAN生态联盟也重磅发布,面向核心开源贡献者、企业用户、模型托管平台及硬件厂商等OCR上下游伙伴,这将进一步推动OCR能力在更广泛场景中的应用落地。
大模型时代,PaddleOCR是如何拔得头筹的?OCR又为何如此重要?
超越谷歌Tesseract OCR,新王者诞生
在OCR领域,Tesseract OCR无疑是一座里程碑式的存在,它的发展历程跨越四十多年。
1985年,Tesseract OCR诞生于惠普公司的研发项目。彼时的OCR技术尚处于起步阶段,核心需求集中在商业文档的自动化识别与录入。
1994年,Tesseract OCR核心版本开发完成。在1995年美国内华达大学拉斯维加斯分校(UNLV)组织的OCR评测中,Tesseract OCR凭借优异的印刷体识别精度,跻身全球顶尖OCR引擎行列。
不过,随着惠普业务重心的调整,1996年后,Tesseract OCR的研发工作几乎陷入停滞。直到2005年,惠普决定将Tesseract OCR开源。
转折点出现在2006年,谷歌看中了Tesseract OCR的技术潜力,接过手来将其纳入自身开源生态体系。研发团队修复了大量历史遗留的bug,优化了引擎的运行速度和兼容性,更紧跟技术潮流,推动其完成了从传统算法到深度学习的跨越。
但技术世界的法则从来如此:没有永恒的王者,只有持续迭代的创新
文心大模型衍生而来的PaddleOCR,正是这场变革的引领者。
PaddleOCR的登顶,并非一朝一夕之功。它诞生于2020年,是深度学习时代下原生基于深度学习技术构建的模型。
2024年,大模型浪潮席卷整个AI行业,OCR赛道也迎来代际更替。文心大模型的持续高速迭代,直接为PaddleOCR带来了全新的能力天花板
PaddleOCR与文心大模型之间,逐渐玩出了一套非常有意思的双向赋能组合拳:
一个负责“看”:用高精度的文本提取能力,把文档中的文字、表格、公式准确捞出来,为大模型提供“食材”。
一个负责“懂”:文心大模型快速迭代,在多模态方向实现突破,视觉理解、跨模态融合、结构化输出,能力版图一步步补齐。文心不仅能消化这些信息,还能反哺PaddleOCR,让它真正理解复杂文档的逻辑脉络。
这种协同直接推动了PaddleOCR的爆发式增长。
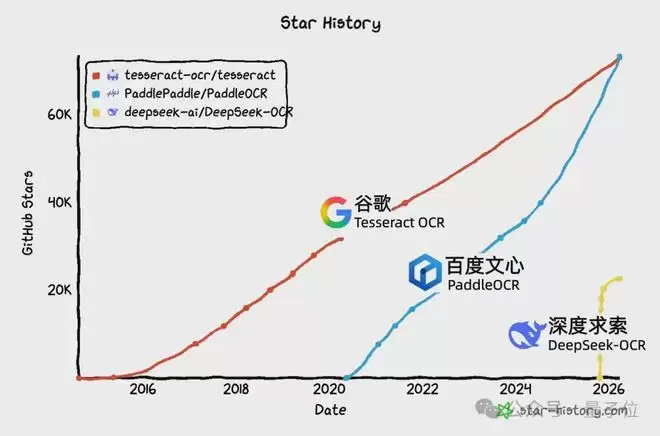
Star History显示,GitHub PaddleOCR Star数自2024年起呈现加速增长态势。
基于文心大模型技术底座,PaddleOCR-VL、PaddleOCR-VL-1.5核心模型相继推出。
2025年10月,百度发布并开源自研多模态文档解析模型PaddleOCR-VL

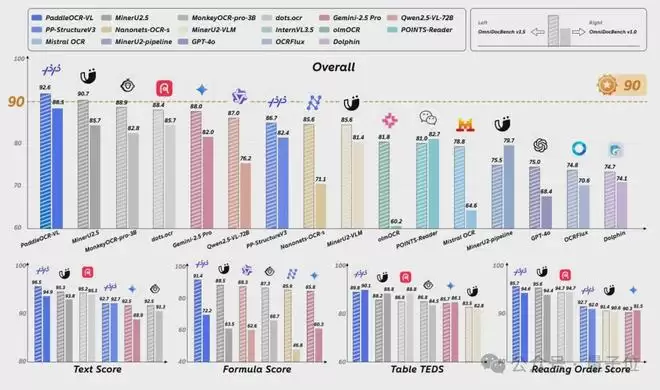
PaddleOCR-VL仅0.9B参数量,就在全球权威文档解析评测榜单OmniDocBench V1.5上拿下92.6分的成绩,超越Gemini-2.5 Pro、GPT-4o等与其体量悬殊的多模态大模型以及OCR领域的垂直模型dots.ocr、MinerU等,获得综合性能全球第一。
在文本识别、公式识别、表格理解、阅读顺序四大核心能力上,PaddleOCR-VL全面刷新SOTA:
同时,发布16小时内,PaddleOCR-VL直冲HuggingFace Trending全球第一、ModelScope Trending全球第一、HuggingFace Paper Trending全球第一,持续五天登顶。
今年一月底,百度再次发力,发布并开源新一代文档解析模型PaddleOCR-VL-1.5
同样仅0.9B参数,PaddleOCR-VL-1.5在OmniDocBench V1.5上的整体精度再提升,达到94.5%,超过Gemini-3-Pro、DeepSeek-OCR2、Qwen3-VL-235B-A22B、GPT-5.2等,全球综合性能排第一。
新一代模型更进一步实现了全球首次“异形框定位”
模型能够精准识别倾斜、弯折、拍照畸变等非规则文档形态,让“歪文档”实现稳定、可规模化解析。金融票据处理、档案数字化等真实场景中的老大难问题,终于有了解决方案。
目前,PaddleOCR用户已覆盖160个国家和地区,支持110+种语言识别,成为真正意义上具有全球影响力的开源项目。
5M参数模型硬刚千亿模型
这些只是水面之上的部分。让PaddleOCR实现翻盘的,还有水面之下的技术突破、积淀和创新。
CVPR 2026,PaddleOCR团队有两篇研究成果成功被收录。
这两篇论文瞄准的都是OCR领域最前沿、最棘手的行业难题。拆开这两篇论文,或许就能从更深层的技术视角看懂PaddleOCR到底强在哪。
首先是PP-OCRv5这项工作。

PP-OCRv5论文链接: https://arxiv.org/pdf/2603.24373v1
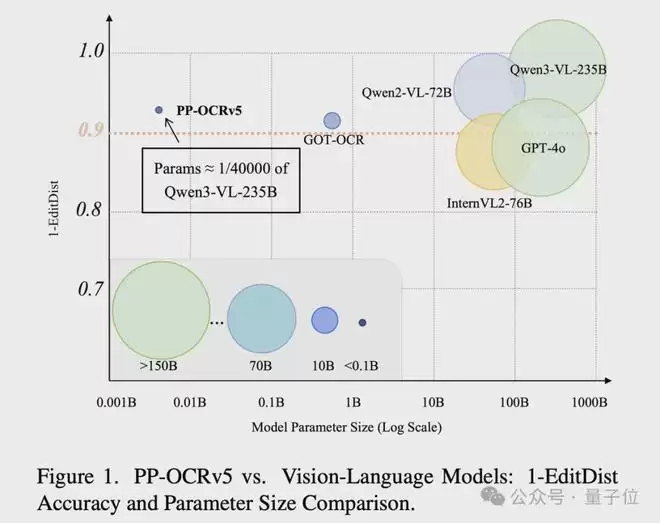
PP-OCRv5提出的是一个反直觉的事:参数不一定是越大越好。
模型参数仅5M,却能在手写、多语言、自然场景下表现超越GPT-4o等千亿参数的大模型。
怎么做到的?答案是“数据为中心”的系统化优化策略
OCR领域,大参数视觉语言模型占主导。但这类通用大模型普遍存在定位精度不足、文本幻觉等致命问题,而传统轻量化OCR模型又过度聚焦架构创新,始终被数据质量与规模的短板限制性能。
PP-OCRv5正是在这样的背景下诞生的。
百度飞桨团队没有盲目堆模型规模,而是提出了一套针对OCR数据的量化分析框架,从数据难度、数据准确性、数据多样性三个维度,彻底重构了OCR模型的数据训练策略。
实验验证了数据三维度优化的有效性。
关键是,团队发现了这样一条规律:
模型训练存在明确的“难度甜点区”,中等难度的数据训练效率最高,简单样本和高难度样本都需要控制比例;特征多样性远比盲目堆砌数据量更重要;而小模型对标签噪声居然有天然的强鲁棒性。

在内部多场景基准测试中,PP-OCRv5加权准确率从PP-OCRv4的53.0%大幅提升至80.1%,在OmniDocBench上,该模型以5M参数实现0.067的平均归一化编辑距离,在专用OCR模型中达到最优水平,在多语言处理、旋转文本、复杂背景等场景表现稳健,定位精度更高、幻觉更少、计算成本远低于百亿参数视觉语言模型。
这一切都指向一个核心结论:数据策略的上限还没有被充分挖掘。通过精细化的“数据工程”,小模型可以在OCR场景媲美大模型。
在PaddleOCR团队看来,“数据本身,可能会慢慢变成⼀条更独⽴、也更重要的能⼒曲线”。
再来看另一项被接收的工作,正是PaddleOCR-VL

PaddleOCR-VL论文链接: https://arxiv.org/pdf/2603.24326
如果说PP-OCRv5解决的是“参数效率”,那PaddleOCR-VL进一步解决的是“计算困境”。
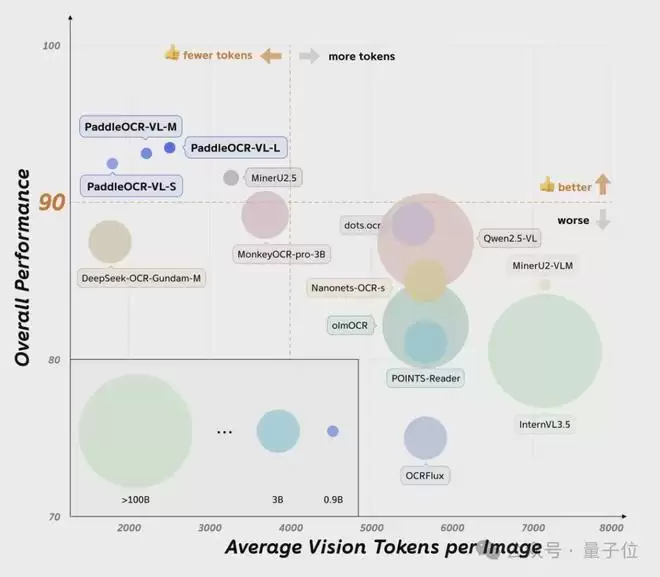
高分辨率文档解析一直是VLM的痛点——输入一张高清文档,视觉Token数量呈二次方增长,算力消耗爆炸。但文档图像中大量是空白背景,算力浪费严重。
PaddleOCR团队的解法很巧妙:别一开始就处理整张图,先找到重点
他们提出了“由粗到细”(Coarse-to-Fine)架构:先用一个轻量级的有效区域聚焦模块(VRFM)定位文档中的关键区域,再让0.9B的模型只处理这些区域。
结果,视觉Token数量只有竞品的1/3到1/2,精度反而更高。如前所述,在OmniDocBench V1.5权威榜单上,PaddleOCR-VL以92.62分的综合成绩登顶全球第一。
总结来看,PaddleOCR的反超是技术代际更替的必然。
为什么AI厂商都在抢OCR?
如果把过去半年AI圈的热闹拉出一条时间线,会发现一个清晰的现象:
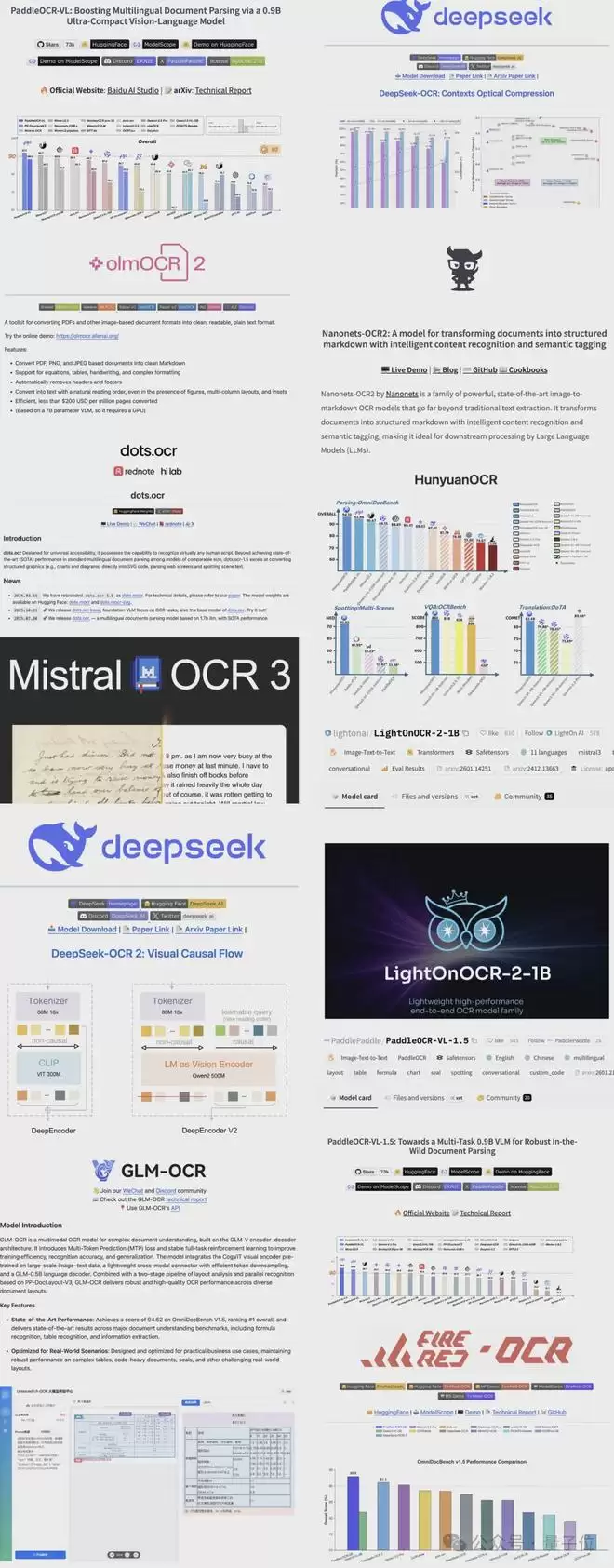
近半年,从巨头到创业公司,国内外OCR赛道迎来集体爆发。
2025年10月,百度PaddleOCR-VL、DeepSeek-OCR、Allen AI olmOCR-2、Nanonets-OCR2-3B、dots.ocr.base几乎同时发布。
抱抱脸模型趋势榜一度被OCR模型“屠榜”。
到了11月,腾讯HunyuanOCR问世;12月,Mistral OCR 3发布。
2026年1月,LightOnOCR-2、DeepSeek-OCR-2、百度PaddleOCR-VL-1.5接踵而至。
2月,智谱GLM-OCR发布;3月,小红书FireRed-OCR加入战局。
为什么这么卷?两个字:数据
互联网公开的高质量数据快被“啃”完,模型训练面临数据亏空。行业广泛判断,大量有价值信息仍沉淀在文档、书籍、合同、表格、扫描件等离线载体中。
OCR就是那把钥匙。
这些海量非结构化信息,无法直接被大模型理解与利用,必须经过OCR,将图像中的文字、版面结构、表格、公式等转化为机器可处理的电子化文本。
所以OCR的身份正在被重写:
从早期依赖手工规则的扫描小帮手,到特征工程与深度学习驱动的高精度字符识别工具,再到如今与Transformer和Agent深度融合的新阶段,它早已跳出“办公室里的文档提取器”定位。
现在,它是大模型数据生态的基座,是Agent理解真实世界的“眼睛”,是大模型变聪明的“钥匙”
就连启蒙全球千万学习者的AI大牛吴恩达,今年年初推出的新课程也是聚焦OCR。课程内容就是关于智能体文档提取(Agent Doc Extraction),也就是教你怎么给OCR装上智能体大脑。
当各家大模型的参数规模越来越接近,决胜的关键反而回到了最底层的数据获取与处理能力。谁拥有更强的OCR能力,谁就掌握了现实世界的信息入口,谁就能为自己的大模型提供源源不断的高质量养料。
PaddleOCR的登顶,正是这场角色转换中最具标志性的事件之一。
更值得关注的是,这场竞争才刚刚开了个头。
未来,OCR的比拼会越来越“钻”。可以想象的一种方向是场景化,不再追求大而全,而是把金融票据、医疗档案、教育试卷等垂直场景做深做透;另一种是端云协同,轻量模型跑在手机、扫描仪上,本地快速识别,云端精准优化,既省算力又保隐私。
更大的想象空间在于OCR和多模态大模型、Agent更深度地融合,我们或许能看到真正的“全能信息处理助手”。
PaddleOCR的登顶,为中国厂商在OCR赛道拿下了领先身位。它背后折射出的,是中国开源整体实力和全球影响力的加速赶超。
从底层基础设施到前沿技术突破,中国开源正在越来越多的赛道上拿出世界级的表现。OCR,只是其中一块拼图。
相关攻略

需求人群 如果你正寻找一个能精准处理文档、提取关键信息的工具,那么Pixl OCR Solution API的定位就非常清晰了。它主要服务于那些日常与大量文档打交道的场景,比如从各类表单、报告中自动提取数据,构建系统化的文档管理体系,或者需要在海量资料中快速检索目标信息。本质上,它是为提升信息数字化

OCR Space是什么 简单来说,OCR Space就是一个在线的“智能扫描仪”。它由a9t9 software GmbH开发,核心能力是光学字符识别(OCR),专门帮你把扫描件或手机拍的文件照片,“变”成可以直接复制、编辑的文字。整个过程在线上完成,不仅免费,还不用注册就能用。对于手头有一堆纸质

西风 发自 凹非寺量子位 | 公众号 QbitAIGitHub OCR项目之王刚刚历史性易主。诞生近40年、统治OCR领域的技术标杆Tesseract OCR,被中国开源拉下王座——百度文心衍生模型

这项由百度千帆团队主导的研究发表于2026年3月17日的arXiv预印本平台(论文编号:arXiv:2603 13398v1),该研究推出了一个名为Qianfan-OCR的革命性文档智能模型,这个拥

2月12消息,上海人工智能实验室 OpenDataLab 团队、 DeepLink 团队及国产芯片厂家携手,于日前先后完成了昇腾、平头哥、沐曦、海光、燧原、摩尔线程、天数智芯、寒武纪、昆仑芯、太初元
热门专题







热门推荐

在日常工作、线上沟通或是学习过程中,截图几乎成了每个人的高频操作。面对市面上琳琅满目的截图工具,如何选择一款清晰、高效又功能趁手的软件,确实是个值得聊聊的话题。今天,我们就来盘点几款备受好评的截图应用,希望能帮你轻松应对各种截图场景。 1、截图帝:功能全面的效率助手 这款工具主打操作简便与功能实用,

对于日语学习者而言,选择合适的工具往往能让学习效果事半功倍。面对市场上琳琅满目的学习资源,一款设计科学、功能匹配的App,能够高效地帮助你从五十音图入门,逐步攻克词汇、语法乃至听说读写的各个难关。那么,目前有哪些备受好评的日语学习软件值得推荐呢?以下这几款应用,或许能成为你日语进阶之路上的得力伙伴。

近期,CGMagazine对赛睿SteelSeries推出的旗舰级游戏耳机Arctis Nova Pro OMNI进行了全面评测。这款耳机的最大亮点,无疑是其创新的OMNIplay多设备互联功能——它允许用户在多个音源设备间实现无缝切换,甚至能同步监听多个音频输入。设想一下,当你沉浸于激烈的游戏对战

探讨Cosplay的魅力,总离不开那些令人印象深刻的精彩演绎。今天为大家带来的这组作品,出自韩国知名Coser(@baby_hippo__)之手,她也被粉丝们亲切地称为“韩援大姐姐”。凭借其出众的身材条件和极具张力的形体表现,这组作品再次证明,在视觉艺术领域,完美的“身材数据”本身就是一种极具说服力

在《明日方舟:终末地》中,前瞻兑换码是玩家开荒阶段获取资源的重要途径,能有效加速前期发展,积累宝贵物资。不过,如何高效领取并使用这些福利,其中有一些实用技巧值得了解。 首先,关键在于信息获取。官方渠道始终是最可靠的信息来源,建议密切关注游戏官网公告、官方社交媒体账号以及游戏内的系统邮件。一旦有新的兑