谷歌新算法:内存占用暴降83%,性能提升八倍详解

智东西
编译 刘煜
编辑 陈骏达
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
智东西3月26日报道,昨天,谷歌于发布了一款针对大语言模型键值缓存(KV Cache)的无损极限压缩算法TurboQuant,它能够从根本上解决向量量化中内存开销问题。谷歌称,TurboQuant可将大语言模型键值缓存内存占用至少降至原来的1/6,推理速度最高提升8倍,同时保持100%精确程度。
Cloudflare的联合创始人、CEO兼执行主席Matthew Prince称,谷歌推出TurboQuant堪称“谷歌的DeepSeek时刻”。
▲Matthew Prince的推文(图源:X)
向量量化一直是企业为AI数据 “瘦身” 的主流技术,主要用于压缩高维向量、节省内存、提升检索与推理效率。但传统压缩方法通常会引入额外的内存开销(每一小块数据都要单独算、单独存一套完整的“压缩参数”),这些参数很占内存,每个数字都要多占1-2 bit,这样反而会影响向量量化的效果。
谷歌称,此次推出的TurboQuant借助了谷歌提出的1 bit无偏误差校正算法QJL与极坐标量化压缩技术PolarQuant,实现了压缩算法的突破。
谷歌官宣推出TurboQuant后,引发资本市场短期内对该技术会降低存储芯片采购需求的担忧,导致存储芯片板块集体回调。
当天美股盘中,美光股票跌幅超过5%,收盘时下跌3.4%,市值蒸发约151.6亿美元(约合人民币1047.37亿元)。闪迪股票下跌幅度更大,一度超过7%,收盘时下跌3.5%,市值蒸发约36.44亿美元(约合人民币251.75亿元)。韩股收盘时,SK海力士股价下跌了6.23%。
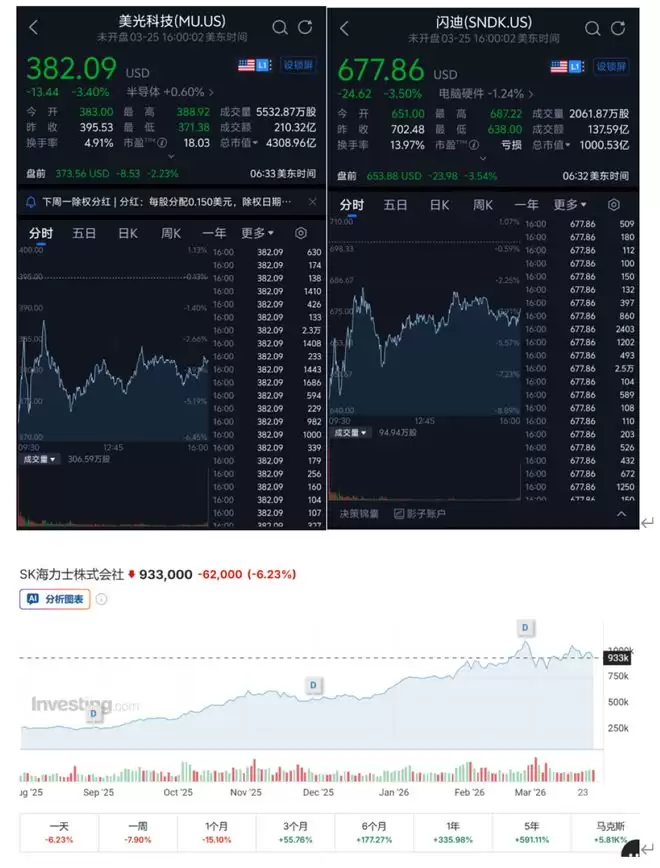
▲美光、闪迪股价图(图源:腾讯自选股)SK海力士股价图(图源:Investing)
博客链接:
https://research.google/blog/turboquant-redefining-ai-efficiency-with-extreme-compression/
一、TurboQuant的工作原理:高质量压缩与误差修正
TurboQuant能够在零精度损失下实现模型尺寸的大幅缩小,非常适合支持键值缓存压缩和向量搜索。它主要通过两个关键步骤实现这一目标。
TurboQuant首先对数据向量进行随机旋转变换,这样处理简化了数据的几何结构,使得TurboQuant可以对向量的每个部分单独应用标准的高质量量化器(量化器是一种将大量连续数值映射为更少并且离散的符号或数值的工具,比如音频量化与JPEG压缩)。
第一阶段,PolarQuant利用大部分压缩算力(绝大多数比特位)来捕捉原始向量的核心语义与特征强度,完成主体压缩。
PolarQuant不再使用表示各轴距离的标准坐标系(即X、Y、Z坐标)来描述向量,而是通过笛卡尔坐标系将向量转换为极坐标。这就好比把“向东走3个街区,向北走4个街区”,替换成“沿37度方向走5个街区”。
PolarQuant转换后只会保留半径(代表核心数据的强度)和角度(代表数据的方向或语义)。由于角度的分布规律已知且高度集中,模型不再需要执行计算代价高昂的数据归一化操作。它将数据映射到一个边界固定、可预测的圆形网格上,PolarQuant就不用再存那些“用来表示数据范围”的额外信息,从而省下了一大块内存空间。
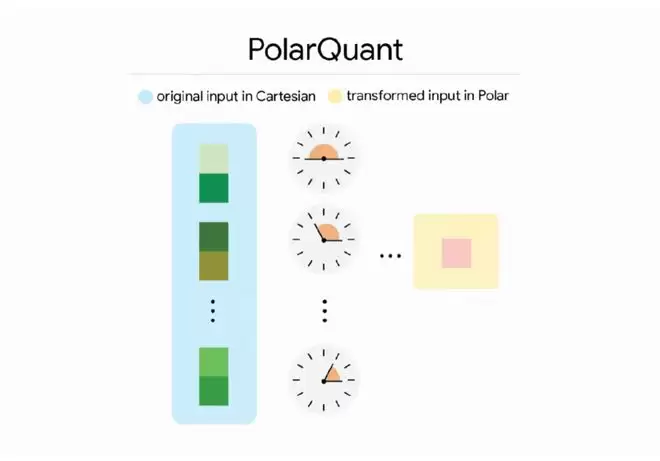
▲PolarQuant工作概念图(图源:谷歌正式)
第二阶段,TurboQuant仅以1 bit的极小额外内存开销,将QJL作用于第一阶段压缩后残留的微小误差上,消除误差。
QJL采用一种名为约翰逊–林登斯特劳斯变换(Johnson-Lindenstrauss Transform)的数学方法,在保留数据点之间基本距离与关联关系的前提下,把复杂的数据压缩成了一种超级简单、几乎不占额外内存、计算又特别快的格式。
QJL在高精度查询与低精度简化数据之间进行结构化平衡,相当于一个数学误差校正器,能够消除压缩带来的偏差。这使得模型能够精准计算注意力分数(即判断输入信息中哪些部分重要、哪些部分可安全忽略的核心过程)。
二、拆解测试:TurboQuant强在哪?
谷歌称,在实验中,TurboQuant能在完全不降低AI模型效果、不损失精度的前提下,显著解决键值缓存给模型推理带来的性能瓶颈。
谷歌拿Meta开源的Llama-3.1-8B模型做测试,将TurboQuant、PolarQuant和KIVI算法相比较,可以看到,与最新基准线Full Cache相比,TurboQuant能够将键值缓存量化至仅3.5 bit,并且没有损失模型精度。同时,PolarQuant也几乎实现了无损压缩。
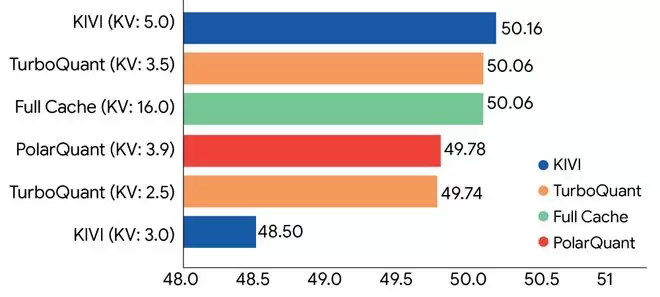
▲TurboQuant的缓存压缩性能图(横轴为性能得分,纵轴为量化方案)(图源:谷歌正式)
谷歌对3种不同量化位宽的TurboQuant进行测试,结果表明,在下图的所有序列长度(模型处理的文本token数量)中,TurboQuant 1 bit版本加速比最高,4 bit版本加速比最低。在1M超长上下文中,TurboQuant 1 bit版本加速比在13倍左右,4 bit版本在7倍左右。
同时,谷歌称TurboQuant在JAX框架(谷歌的超级加速框架)的基础上,仍能实现显著加速。在英伟达的H100 GPU上,TurboQuant 4 bit版本相比不压缩的32bit原版键值缓存,速度最高提升8倍,不仅能加速大模型推理,还能大幅优化向量搜索、索引构建等关键场景。
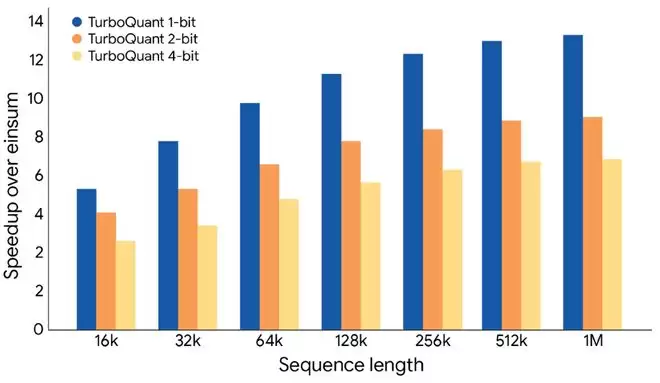
▲TurboQuant计算注意力logits的加速效果图(横轴为序列长度,纵轴为加速比)(图源:谷歌正式)
在高维向量搜索任务中,谷歌以1@k召回率(1@k召回率用于衡量算法在其前k个近似结果中,压缩后的向量和不压缩时算出“最相似结果”一样的概率。)为指标,将TurboQuant与当前最优方法PQ和RabbiQ进行了效果对比。
从下图可以看到,不管是2 bit还是4 bit版本的TurboQuant,都在召回率指标上持续取得了更优表现。这证实了TurboQuant在高维搜索任务中的稳健性与高效性。
同时,谷歌称,在GloVe数据集(维度d=200)(斯坦福大学发布的经典预训练词向量数据集)上,TurboQuant在与当前多种主流先进量化方法的对比中,展现出稳健的检索性能,并实现了最优的1@k召回率。
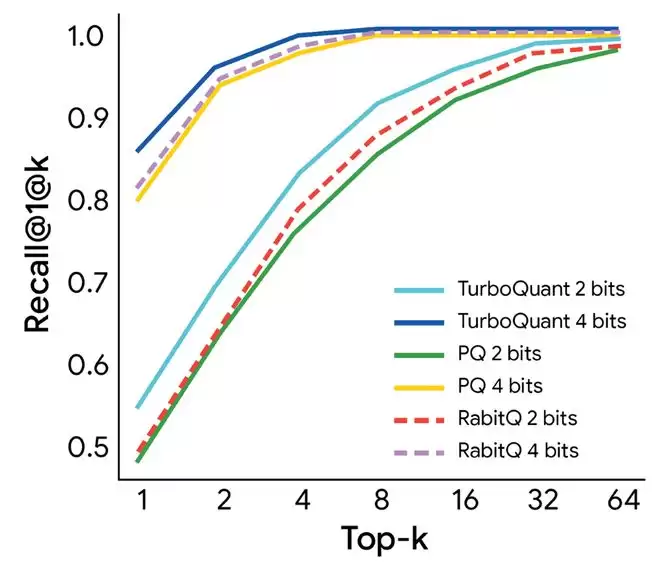
▲TurboQuant的召回率图(横轴是检索范围,纵轴是召回率)(图源:谷歌正式)
由此可见,TurboQuant在PolarQuant主体压缩的基础上,通过极低比特量化与误差校正,使键值缓存的存储空间显著减少,让模型能够在相同硬件条件下处理更长的上下文、更大的批量数据,同时降低推理成本。
此外,TurboQuant的推理速度极快,精度几乎达到无损效果,即使在超长文本下其推理能力依然稳定高效。
结语:算法博弈下的存储焦虑,企业推动大模型“瘦身”革命
TurboQuant在谷歌的测试中表现出了出色的出成绩,它能够以极低的内存占用、近乎为零的预处理耗时,完成大规模向量索引的构建与查询,这让“谷歌级别”的语义搜索变得更加快速高效。
早在2025年,英伟达于在arXiv上公开了第一版KVTC,证明它能把大模型的键值缓存压缩到原来的 1/20,同时精度损失不到1%。近期,英伟达更新了实测数据,称在H100 GPU上处理8000 Token的长提示时,模型生成第一个词的时间,从传统方案的3秒左右,缩短至380毫秒,速度提升8倍。
科技大厂正通过持续的算法创新与迭代,不断提升AI大模型的推理效率。在当前存储芯片供应紧张的背景下,企业通过对大模型推理过程中的键值缓存进行高效压缩,来提升大模型自身的推理效率,或许可以在一定程度上缓解存储芯片产能跟不上AI算力发展速度的局面。
相关攻略

随着大模型参数规模不断增长,混合专家(Mixture-of-Experts, MoE)架构因其稀疏激活特性,成为平衡模型性能与计算开销的主流方案。然而,在实际的Web级应用部署中,一个关键挑战日益凸显:传统MoE的路由机制通常是“无记忆”的。 试想,在搜索引擎、智能问答或多轮对话等高并发场景下,用户

编程十年的一点分享 在软件开发的路上走过十几年,从一个爱好者到以此为业,有些体会或许值得聊聊,就当是抛砖引玉吧。 最早接触编程,是从BASIC和C语言开始的。工作后,随着需要,陆续学习了dBase、Access这类桌面数据库的开发。真正以开发为职业,可以说始于FoxPro 5 0,之后技术栈随着项目

引言 编程,是一门实践科学。这意味着,学习它的最佳方式就是动手去敲代码。但这是否意味着,我们可以因此轻视理论的学习呢? 入门编程 如果你去各大技术社区提问“该如何入门编程”,五花八门的答案会瞬间涌来。 不过,仔细梳理一下,无外乎以下几种流派: 学院派 他们推荐从C语言入手,并辅以数据结构、操作系统等

想象一下这个场景: 你让 AI Agent 帮你修一个代码 Bug。它打开项目,读了 20 个文件,改了改,跑了一下测试,没过,又改,又跑,还是没过……来回折腾了十几轮,终于——还是没修好。 你关掉电脑,松了口气。然后收到了 API 账单。 上面的数字可能让你倒吸一口凉气——AI Agent 自主修

Discord接入:让OpenClaw成为你的社区智能管家 对于全球数亿的游戏玩家和社群爱好者来说,Discord几乎等同于线上“大本营”。那么,有没有可能让你精心搭建的Discord服务器也拥有一个聪明能干的AI助手呢?答案是完全可行。通过创建Discord Bot(机器人),你可以将OpenCl
热门专题







热门推荐

当RPA机器人面临复杂决策场景时,企业通常可以采取以下几种经过验证的有效策略来应对,确保自动化流程的顺畅与准确。 借助人工智能技术 一种广泛应用的解决方案是将RPA与人工智能技术深度融合,特别是机器学习与自然语言处理。通过集成AI的预测分析与模式识别能力,RPA能够处理非结构化数据并应对模糊的业务情

当智能制造与人工智能技术深度融合,这不仅是两种前沿科技的简单叠加,更是一场旨在重塑全球制造业竞争格局的系统性变革。其核心目标在于,通过深度嵌入人工智能等前沿技术,全面提升制造业的智能化水平、生产效率与国际竞争力。那么,如何有效推进这场深度融合?以下六大关键策略构成了清晰的行动路线图。 1 加强关键

对于已经部署了RPA的企业而言,项目上线远不是终点。要让自动化投资持续产生价值,对机器人性能进行持续优化是关键。这就像保养一台精密的机器,定期维护和调校,才能确保其长期高效、稳定地运行。 那么,具体可以从哪些方面着手呢?以下是一些经过验证的优化方向。 一、并行处理与任务分解 首先,看看任务执行本身。

面对海量数据源的高效抓取需求,分布式数据采集架构已成为业界公认的核心解决方案。该架构通过精巧的设计,协调多个采集节点并行工作,并将数据汇聚至中央处理单元,最终实现数据的集中分析与深度洞察。这套系统看似复杂,但其核心原理可拆解为几个关键组件的协同运作。 一、系统核心组成 一套典型的分布式数据采集系统,

Gate io平台活动页面多样,新手易混淆注册奖励、邀请与正常开户页。本文梳理三者核心区别:注册奖励页通常含专属链接与限时福利;邀请页强调社交分享与返利机制;正常开户页则提供基础功能与安全验证。清晰辨识有助于用户高效参与活动,避免错过权益或操作失误,提升在Web3领域的入门体验。