30余顶尖高校联合发布视频推理数据集,规模达百万级

新智元报道
编辑:LRST
【新智元导读】AI视频生成已能「画得像」,但不会「想得对」。VBVR推出百万级视频推理数据集,首次系统评测模型对空间、物理、逻辑和抽象的推理能力,发现顶尖模型通过率仅68%,暴露其缺乏真实认知,推动视频AI从「视觉模仿」迈向「智能推理」。
近年来,视频生成模型在视觉质量、时序一致性和文本对齐等方面取得了显著进展,从最初的模糊光影到如今足以乱真的好莱坞级画面,「视觉质量」的竞争已趋于白热化。然而,一个被长期忽视的深层命题逐渐浮出水面:视频模型真的「理解」它所创造的世界吗?
现有研究和评测体系,更多聚焦于「好不好看」「像不像」,而视频中真正与智能相关的能力——对空间、物理、逻辑、因果与抽象规则的推理——却长期缺乏系统性刻画。一个核心瓶颈在于,视频推理领域至今缺少一个规模足够大、任务覆盖足够全面、且评测可验证、可复现的数据集与基准。
现有工作往往停留在零散demo或小规模benchmark 上,难以研究规模效应与泛化行为;
任务定义高度碎片化,空间、物理、逻辑、抽象等能力混杂在一起,缺乏统一的「推理能力定义」;
训练数据与评测任务严重脱节,模型更像是在「生成得更稳」,而非「想得更对」。
近日来自NTU、CMU、斯坦福、UCB等32所高校的研究员联合提出VBVR(Very Big Video Reasoning),并不是一个单点 benchmark,而是一套一次性补齐所有短板的面向视频推理研究的完整基础设施。

论文链接:https://arxiv.org/pdf/2602.20159v2
视频链接:https://www.youtube.com/watch?v=isnyV_BDgBE
前所未有的超大规模:研究人员构建了包含200 个精心策划的推理任务和超过 100 万个视频剪辑的 VBVR-Dataset。其规模比现有同类数据集大出约1000 倍,为系统研究视频推理的算法革新提供了坚实的土壤。
六大核心认知支柱:基于人类认知架构理论设计任务,研究人员将推理能力细分为:感知、空间性、物理规律、逻辑与符号、抽象、以及变换。
完全规则化、可复现的评测标准VBVR-Bench:研究人员摒弃了模糊的「LLM-as-a-judge」,引入了可验证的规则评分器。这种评估方式与人类判断高度一致,确保了结果的科学性和稳定性。
超强baseline:通过在Wan2.2 I2V 14B上的规模实验去回答「数据扩大会不会带来泛化」的核心问题
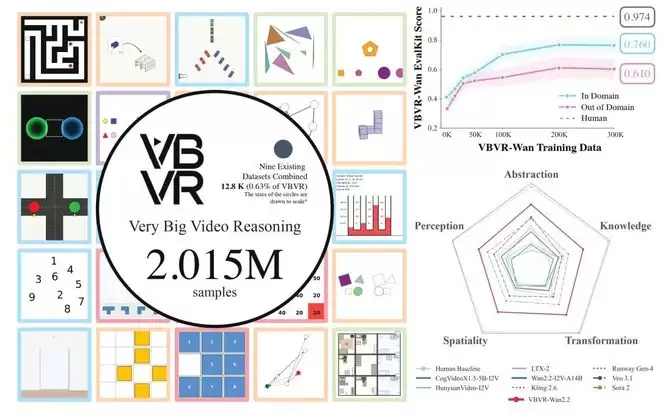
图片1VBVR 概览。 左侧:网格展示了覆盖认知架构的代表性任务,并根据其对应能力进行颜色编码:空间性(Spatiality)、变换(Transformation)、知识(Knowledge)、抽象(Abstraction)和感知(Perception)。在网格中心,展示了 VBVR(2.015M 样本) 与其他 九个数据集总和(12.8K 样本) 的规模对比:圆的大小按比例绘制。右上:在域内(in-domain)和域外(out-of-domain)评估中的扩展行为(scaling behavior)。右下:基于五种认知能力的基准性能表现。

图片2VBVR-Dataset 的示例任务实例,按五种认知能力进行组织。每个序列展示了为得到有效解所需的结构化推理过程。这些任务通过生成器实现,支持可扩展的实例变化。
在规模层面,VBVR-Dataset 的数字很醒目:200 个任务、2,015,000 张图像、1,007,500 个视频片段,约为既有同类资源的三个数量级。本文还特别设置了公开任务与隐藏任务,用于后续排行榜评估,避免基准被过度「刷榜化」。
研究团队根据人类认知理论,将视频推理能力划分为六大核心支柱(Pillars),涵盖 200 个精心设计的任务。同时这个数字随着社区的不断贡献还在增长,每一类都对应可参数化的任务生成器,能够持续采样新实例:
感知 (Perception):测试边缘检测、颜色和形状感知及辨别能力。
空间性 (Spatiality):考察位置表征、几何关系及导航能力(如迷宫寻路)。
变换 (Transformation):涉及心理旋转、物体状态演变等精神表征的操纵。
知识 (Knowledge):关于世界的命题性内容,可能来源于经验学习,也可能是先天赋予的。
抽象 (Abstraction):考察从特定经验中提取通用知识的能力。
VBVR-Bench
基于规则的系统可验证评分
VBVR-Bench 的核心主张是:视频推理评测应从「模型当裁判」(LLM-as-a-Judge)的主观评估范式,转向基于规则的可验证评分机制。在该基准中,每一个测试任务都配套明确的任务规则与加权评价指标,评估维度涵盖目标识别、路径合法性、执行效率、时序一致性以及逻辑有效性等关键因素。
这种设计带来的首要优势是,
完全可复现:对于同一模型输出,在相同规则体系下应始终得到稳定一致的评分结果,不会因评审模型的温度设置、提示词差异或上下文变化而产生波动。
深度诊断能力:它不仅能给模型打分,还能通过分析五大认知支柱(感知、空间,知识、变换、抽象)下的细分表现,揭示出模型在不同认知能力之间的相互依赖与权衡。研究者能够准确定位模型失败的具体原因,例如是目标识别错误、路径规划违反约束(如穿越障碍),还是由于生成视频抖动而导致的任务完成失败。
为了验证这种自动化规则评分是否靠谱,研究团队进行了人类偏好对齐实验。结果显示,VBVR-Bench 的自动化评分与人类判断的 Spearman 相关系数超过了0.9,证明了规则评分的权威性。
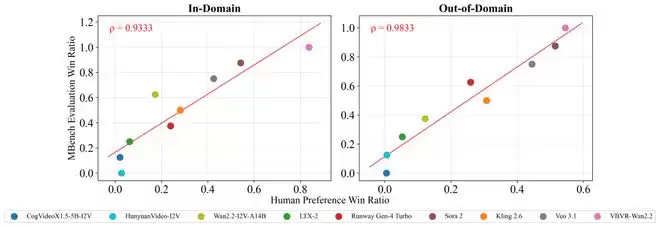
图片3人类偏好对齐分析:VBVR-Bench 自动胜率与人工偏好胜率呈高度相关。
VBVR-Wan2.2实验洞察
谁是当前的推理王者?
推理能力的 Scaling Law (规模化规律)
实验揭示了明显的规模效应,在基础模型Wan2.2-I2V-A14B上利用VBVR-Dataset 上微调后,得到的VBVR-Wan2.2模型在基准上实现了取得了显著性能提升。
从0.371跃升至0.685整体相对提升达到84.6%,并在多个能力维度上超过当时的主流专有模型。
泛化能力的「早期信号」
虽然域内与域外任务之间存在性能差距,但研究观察到随着数据规模扩大,模型开始表现出向未见过任务迁移推理能力的趋势。这意味着模型不仅仅是在记忆模式,而是在逐步内化某些通用的物理或逻辑规则。
这种性能提升并非可以无限持续。随着训练,域外任务与域内任务之间仍然存在约15%的泛化差距。
也就是说,仅依赖于「增加同类型数据规模」虽然能够带来显著性能增益,但仍不足以完全弥合系统性的泛化鸿沟。论文因此反复强调一个重要结论:规模化能够显著提升性能,但其效果仍然受到结构性上限的限制。
研究人员希望VBVR-Dataset也能够为下阶段研究提供一个实验土壤,社区可以以此为基础,进行架构层面的改造,例如显式状态跟踪、结构化推理模块、和自校正机制。
场景可控性是可验证推理的先决条件(Controllability before reasoning):通过定性分析发现,领先模型的高分本质上源于其极强的「约束执行」能力。
相比于基础模型在生成时会随意重写背景或物体标识,导致中间状态不可验证VBVR-Wan2.2展现出了一种「外科手术式」的精确度:它能严格遵循指令执行删除、旋转或多步操作,而不对画面其他元素产生任何意外扰动。
这种「非必要不修改」的确定性证明,模型已开始摆脱随意的「视觉脑补」,转而学习在物理规则的框架内进行受控演进。

图片4域外任务的定性概览:部分A展示了VBVR-Wan2.2与Sora 2在三个任务上的同任务、同样本对比;部分B展示了VBVR-Wan2.2在完全没见过的任务上的涌现现象; 部分C展示了VBVR-Wan2.2在任务上的实际边界。即使在改进后,模型仍可能在长生成任务中仍会出现一些问题,例如结果看似正确,但中间步骤并不遵循真实决策逻辑。这类「答案对了、过程错了」的现象,正是下一阶段视频推理评测必须继续强化的部分。
开源共建, 赋能社区,定义数据生产新范式
VBVR团队坚信,开放与共享是推动视频推理社区发展的基石。
VBVR-Dataset的百万级视频数据已向社区全量公开。
不仅如此,各个任务的参数化生成器代码以及高效的DataFactory云端架构也将同步开源。
基于云端无服务器的架构系统( AWS Lambda)支持多达990个节点并行作业,仅需2-4小时即可完成百万级数据的生产,且单次运行成本控制在800-1200美元之间,实现了极高的数据生产效能。
参考资料:
https://arxiv.org/pdf/2602.20159v2
相关攻略

这项由谷歌DeepMind阿姆斯特丹团队完成的开创性研究发表于2026年3月的arXiv预印本平台(论文编号:arXiv:2603 20155v1),为人工智能文本生成技术带来了革命性突破。有兴趣深

最近有支叫《霍去病》的 AI 短片让我印象深刻,播放量轻松破亿,逼真得让人以为是重工业大制作。真相是:3 个人,48 小时,从立项到成片。 核心创作者还不是影视科班出身,人家之前只是一名内容运营。同

新智元报道编辑:LRST【新智元导读】AI视频生成已能「画得像」,但不会「想得对」。VBVR推出百万级视频推理数据集,首次系统评测模型对空间、物理、逻辑和抽象的推理能力,发现顶尖模型通过率仅68%,

这项由德国马克斯·普朗克信息学研究所与萨尔兰大学联合开展的研究发表于2024年,研究编号为arXiv:2603 03282v1,有兴趣深入了解的读者可以通过该编号查询完整论文。当你打开手机与语音助手

当你和ChatGPT对话时,有没有觉得它的回答总是一个字一个字慢慢蹦出来?这种现象背后其实隐藏着人工智能领域的一个核心难题。来自加州大学圣地亚哥分校的研究团队最近发表了一项突破性研究,他们开发出一种
热门专题







热门推荐

广东无人机适飞空域扩大16%至10 24万平方公里,覆盖全省57%陆地面积,滨海、郊野、工业园区及非核心城区公园等区域开放,深圳市区新增连片适飞区。飞行需通过民航局UOM平台提前申请,严禁“黑飞”,违者将受处罚。平台已升级,实现全国规则统一与分钟级空域更新,支持低空物流与巡检等应用。

杭州Costco门店因iPhone17系列手机引发抢购热潮,数百人排队致迅速断货。抢购源于官方降价与地方补贴叠加:iPhone17Pro全系直降千元,同时当地青年消费补贴可再减10%,最高省千元。双重优惠下,256GB版iPhone17Pro到手价低至7172元,较电商平台便宜近千元,吸引本地及周边消费者。目前门店仍处缺货状态,补货时间未定。

5月17日晚,长征八号运载火箭在海南商业航天发射场点火升空,成功将千帆星座第九批组网卫星送入预定轨道。此次发射是该发射场启用以来的第15次成功发射,也是今年第5次发射,体现了我国商业航天发射能力的日益成熟和常态化运营的稳步推进。

七彩虹新款iGameM15 M16Origo2026款游戏本已发售,起售价11499元。M15为15 3英寸黑色机身,配备2 5K300Hz屏,最高可选Ultra9处理器与RTX5070显卡。M16为16英寸白色款,屏幕规格相同,处理器性能更强,电池容量更大。两款均提供多种配置,享受国家补贴后价格更具竞争力,面向中高端游戏玩家与创作者。

联想在北美市场推出新款ThinkPadT14Gen7商务笔记本,支持用户自行更换LPCAMM2内存。该机型提供多款英特尔酷睿Ultra处理器选项,内存可选16GB至64GB,电池与屏幕亦有多种配置,其中顶配版搭载OLED屏幕。产品起售价为1618美元,高配版本价格超过3700美元,主要面向商用及专业办公市场,兼顾性能、可升级性与不同预算需求。