MIT全新RandOpt算法,破解大模型训练久耗痛点
只需向模型添加高斯噪声,性能就能比肩甚至超越GRPO/PPO等经典调参算法。
MIT新论文向大家都在头疼的“调参”开炮了!
为了将预训练模型变成某一任务领域专家,无数人夜以继日,纷纷掉发。
然而现在,一对来自MIT的师生用一篇新论文告诉大家:
不用复杂调参,随机改改参数再整合结果,模型效果就能和GRPO/PPO等专业调参方法差不多。

在这篇论文诞生前,我们熟悉的论调是:专家模型是训练出来的。
甭管是靠梯度下降还是强化学习,都得一步一个脚印慢慢优化参数。
但这篇论文却揭示,专家模型早就存在,只是藏在权重空间里,预训练模型的真实形态be like:
专家模型像灌木一样密密麻麻长在周围。(即论文提到的“Neural Thickets(神经丛林)”现象)

△注:以上为AI生成,非论文内容
就是说,只要在预训练权重附近稍微扰动一下参数,就可能“碰到”一个新的任务专家。
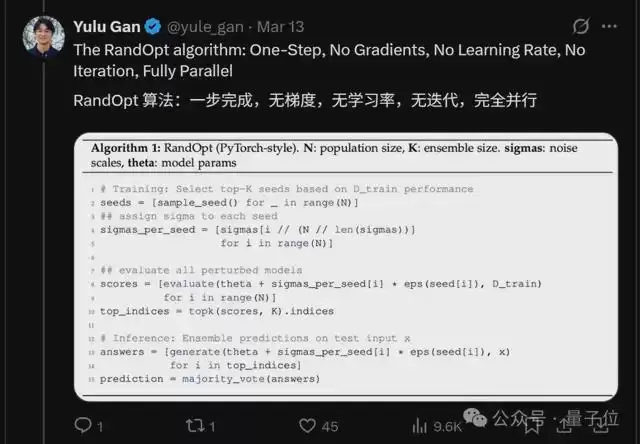
基于此,作者进一步提出了一种非常简单的方法RandOpt:
只需向大语言模型添加高斯噪声(单步操作——无需迭代、无需学习率、无需梯度),然后将它们集成起来,就能在数学推理、编程、写作和化学任务上取得与标准GRPO/PPO相当甚至更优的性能。
而且作者发现,模型越大,效果越好。
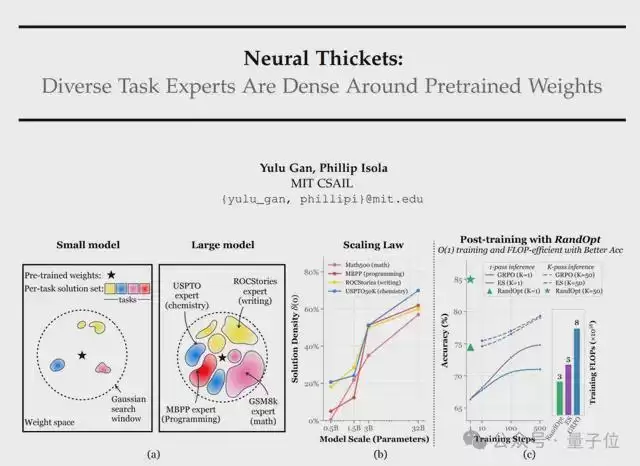
预训练模型周围藏着“神经丛林”
简单来说,论文给出了一个反直觉的结论——
预训练模型周围早就存在大量“专家模型”。
在权重空间里,能解决不同任务的模型并不是零散分布的,而是密集地“长”在预训练权重附近。
所以理论上,并不一定需要复杂的训练过程,只要在这片区域里多试几次,就有机会找到表现不错的任务专家。
听到这里,估计很多人的反应是:啊这,难道这不就是靠猜、靠试吗?
没错,还真就是靠猜。
一直以来,随机猜测都被认为是不够靠谱的机器学习算法,比如随机猜出ChatGPT的参数向量,概率几乎为零。
但论文发现,到了预训练模型这里情况就变了——
模型权重周围,能提升任务表现的参数扰动变得很密集,所以随机猜测也能找到有效改进方案。

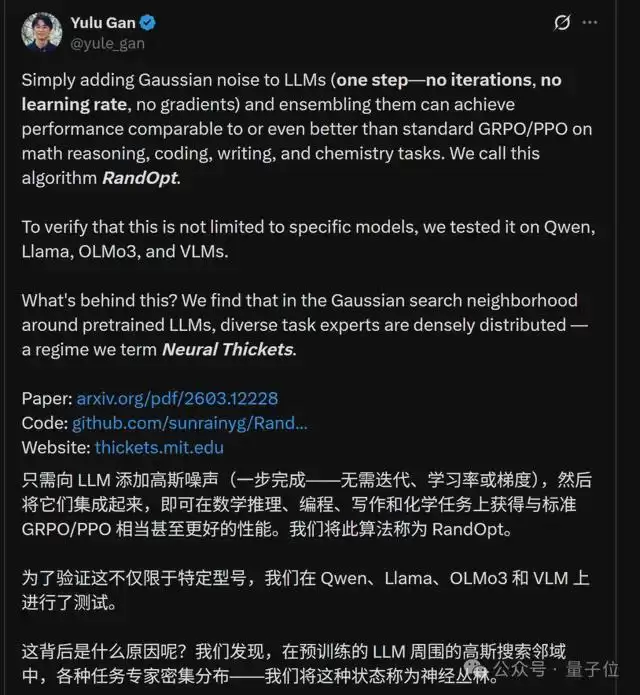
在论文中,作者对预训练的Qwen2.5模型(0.5B~32B)施加了1000次随机权重扰动,并通过随机投影将其投影到二维平面。
结果发现,模型越大,周围“高精度区域”越密集;小模型扰动后大多性能下降(蓝色区域),而大模型周围随处可见性能提升的“专家”(红色区域)。
换言之,模型越大,这种扰动效果越明显、越起作用。
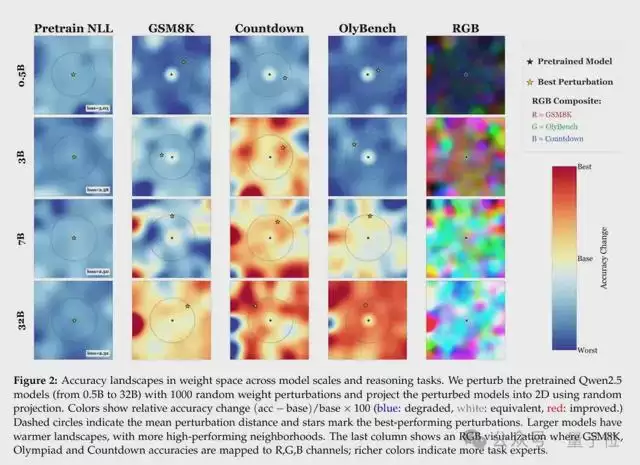
而且需要注意,这些随机扰动最后带来的不是“全能选手”,而是“偏科战神”。
实验显示,没有任何一个随机改动能让模型在所有任务上都实现提升。例如,某一个改动能让模型数学算得更准,但写代码会变菜;另一个改动能让模型化学题做得好,但写故事不行。
并且同样的,模型越大,这种偏科越明显。
至于模型为啥会出现这种“周围偷偷藏一堆高手”的现象,论文也通过一个极简实验给出了初步解释。
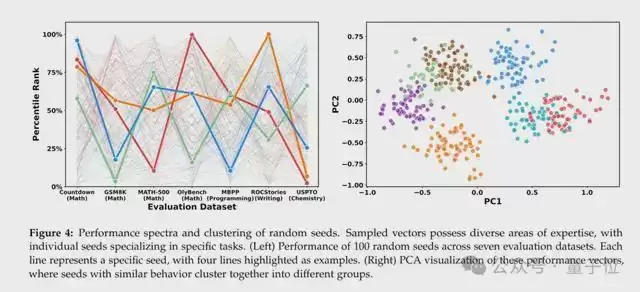
他们选用了结构最简单、最容易看懂的1D信号自回归模型,让其学习预测一段时间序列信号的下一个数值。
结果出现了三种情况:
无预训练:不论怎么添加扰动,模型周围都完全找不到可以提升性能的改动,随机猜测无意义;单一任务预训练:模型只能把经过预训练的任务做到极致,参数周围不会冒出其他优质改动;多任务混合预训练:模型参数周围瞬间布满能提升性能的扰动,随便加个小改动,就能解锁擅长某类信号预测的专项能力,成功复刻“神经丛林”的密集状态。
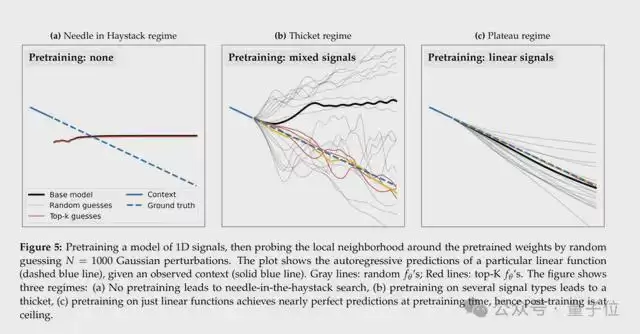
由此论文得出核心结论,“神经丛林”现象的诞生,关键就在于大模型的海量多任务预训练。
换言之,正因为底子够足,所以周围很容易找到可以随机扰动的“专家”。
启发了RandOpt算法
而上述研究,也启发论文作者提出了一种新的算法,RandOpt。
RandOpt的运行机制可以分成简单两步:随机找高手+组队投票。
“随机找高手”就和前面提到的类似,给预训练模型的参数随机做N次扰动,然后就会得到N个“新版本模型”。
再用少量验证数据简单测一测这些模型,我们就能找出其中表现最好的K个。
拿到这K个模型后,接下来进入实战推理阶段——
让这K个“高手”各自回答问题,最后按“少数服从多数”的原则决定最终结果。
整个过程有两个值得注意的点:
一是在添加扰动sigmas(即噪声强度)时,RandOpt会尝试不同强度的噪声(比如小扰动、中扰动、大扰动),以确保能找到各种类型的专家。
二是这N个模型可以同时在多块GPU上运行,速度很快。
当然了,论文也试着用不同模型测试了这一新算法。
初步结果显示,对于纯语言大模型,在数学、编程、写故事、化学等任务上,RandOpt的准确率和现在主流的专业调参方法(PPO/GRPO/ES)差不多,有的甚至更高。
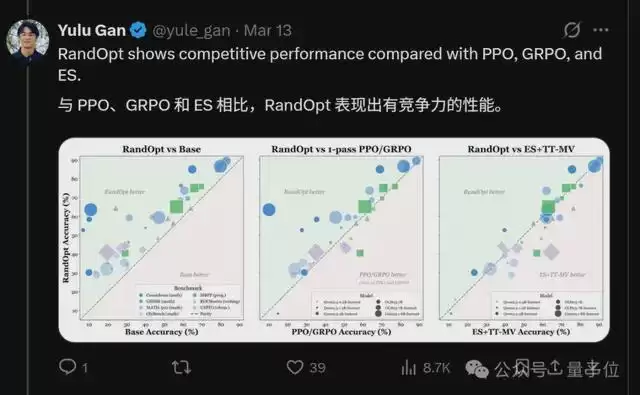
而对视觉-语言模型来说, RandOpt的提升作用则更加明显,准确率直接从56.6%涨到69.0%。

与此同时,除了语言和视觉-语言模型,论文也在图像扩散模型中观察到了类似的“神经丛林”现象——
参数空间的某些特定区域会倾向于生成具有特定色调或视觉风格的图像。

以及论文作者提醒,RandOp在以下情况下效果更佳:
随机改的次数越多,挑的“高手”越厉害。模型越大,RandOpt效果越好。
论文作者介绍
最后介绍一下这项研究的两位作者。
Yulu Gan,北大工程硕士,目前是MIT计算机科学与人工智能实验室(CSAIL)的博士生。
此前曾在微软实习,研究方向主要为多模态大语言模型、推理、多智能体系统以及AI for science。

另一位作者Phillip Isola是他的导师,现任MIT电子工程与计算机科学系副教授。
Phillip Isola在加州大学伯克利分校做完博士后研究后,曾在2017年以技术人员的身份加入OpenAI。
不过干了不到一年,后面又去谷歌当了一年访问学者。
再然后就是回到读研时的母校MIT,任教至今。
Phillip Isola的主要研究方向为AI基础理论和计算机视觉,曾参与提出pix2pix、LPIPS感知损失等经典工作,谷歌学术论文被引量超10w+。
通过本次研究,师徒二人想重新告诉大家:
是时候重新认识预训练模型了,它不只是“一个能用的模型”,更是“一堆高手的集合”。
只要预训练做得足够好,后续想让模型干好具体任务,根本不用复杂调参,像RandOpt这样随机改改、组队投票就行,省时间省算力。

不过缺点也很明显,大致呢有下面这几个:
依赖优质预训练,这是一个基本大前提。模型只能基于预训练数据找改进,无法让模型学会新技能。K越大效果越好,但推理时要跑K个模型,虽然蒸馏能缓解,但蒸馏不适用于所有场景(比如生成式任务)。只适合有明确答案的任务,像写故事、设计分子这种结构化生成任务,还需要进一步改进集成方式。

目前相关论文和代码已公开,感兴趣可以继续关注。
论文:
https://arxiv.org/pdf/2603.12228
GitHub:
https://github.com/sunrainyg/RandOpt
项目主页:
https://thickets.mit.edu/
相关攻略

近日,开源具身智能原生框架Dexbotic宣布正式支持以RLinf作为其分布式强化学习后端。对具身智能开发者而言,这不仅是一次普通的工程适配,更意味着VLA模型研发中长期存在的「SFT与RL割裂」问题,正在被真正打通。 这是一种典型的「乐高式协作」:双方不强行Fork、不粗暴揉合代码,而是保持清晰边

随着大模型参数规模不断增长,混合专家(Mixture-of-Experts, MoE)架构因其稀疏激活特性,成为平衡模型性能与计算开销的主流方案。然而,在实际的Web级应用部署中,一个关键挑战日益凸显:传统MoE的路由机制通常是“无记忆”的。 试想,在搜索引擎、智能问答或多轮对话等高并发场景下,用户

编程十年的一点分享 在软件开发的路上走过十几年,从一个爱好者到以此为业,有些体会或许值得聊聊,就当是抛砖引玉吧。 最早接触编程,是从BASIC和C语言开始的。工作后,随着需要,陆续学习了dBase、Access这类桌面数据库的开发。真正以开发为职业,可以说始于FoxPro 5 0,之后技术栈随着项目

引言 编程,是一门实践科学。这意味着,学习它的最佳方式就是动手去敲代码。但这是否意味着,我们可以因此轻视理论的学习呢? 入门编程 如果你去各大技术社区提问“该如何入门编程”,五花八门的答案会瞬间涌来。 不过,仔细梳理一下,无外乎以下几种流派: 学院派 他们推荐从C语言入手,并辅以数据结构、操作系统等

想象一下这个场景: 你让 AI Agent 帮你修一个代码 Bug。它打开项目,读了 20 个文件,改了改,跑了一下测试,没过,又改,又跑,还是没过……来回折腾了十几轮,终于——还是没修好。 你关掉电脑,松了口气。然后收到了 API 账单。 上面的数字可能让你倒吸一口凉气——AI Agent 自主修
热门专题







热门推荐

微星PRO MAX系列ATX 3 1全模组电源现已于京东平台全面上市。该系列精心规划了850W、1000W与1200W三档功率规格,全线产品均严格通过80PLUS白金能效认证,为用户带来高效节能的供电体验。首发期间,850W版本售价579元,1000W版本679元,1200W版本799元,参与晒单活

行业首款集成视觉能力的AI智能耳机即将面世。光帆科技近日正式宣布,其创新产品“光帆全感AI耳机”定于5月15日全面发售。这款耳机以“全感知、主动式、个性化”为核心定位,旨在彻底革新用户与可穿戴音频设备之间的交互模式。 本质上,它颠覆了传统耳机的被动响应模式。根据官方介绍,这款AI耳机能够主动感知并理

止损是交易中控制风险的关键手段,在币安等交易平台设置止损时,主要参考市场波动率、技术分析关键位以及个人风险承受能力。合理的止损应基于对价格走势的客观判断,而非情绪化决策,同时需结合仓位管理,避免因单次止损过大而影响整体资金安全。动态调整止损位以适应市场变化,是提升交易纪律性的重要环节。

过去两年,要问大模型最习惯用什么格式交付内容,答案多半是Markdown。 原因不难理解:Markdown足够干净,没有冗余格式,复制到文档、知识库、GitHub,甚至直接粘贴到微信公众号后台,基本都不会出问题。某种程度上,它已经被公认为AI时代最理想的标记语言。 不过,随着Agent时代的到来,M

距离2026-2027年度旗舰手机的大幕拉开,大约还有四个月时间。按照惯例,届时在全球舞台上率先亮相的主流旗舰,很可能依然是苹果的iPhone 18 Pro系列。 就在昨天(5月8日),知名爆料人Jon Prosser发布了iPhone 18 Pro Max的视频渲染图,与此同时,关于该系列手机的七