(文/陈济深 编辑/张广凯)
在狂飙突进的AI时代,算力芯片的"卡脖子"是显性的。
过去几年里,全行业都在盯着GPU的短缺,国内企业也纷纷在这个赛道上发力。如今,随着国产计算芯片的短板被逐步填补,算力底座的初步成型已经有目共睹。
然而,当所有人以为跨过GPU这道坎就能畅通无阻时,另一个隐蔽却致命的空白浮现了出来。
随着大模型参数从千亿迈向万亿,算力集群的规模正从千卡走向万卡,并加速向十万卡逼近。据工信部今年1月披露的数据,我国已建成万卡智算集群42个,智能算力规模超过1590 EFLOPS。而在这个量级下,决定系统生死的不单纯是单张显卡有多强,而是成千上万张卡能不能连在一起高效工作——而将它们连在一起的核心技术,高速互联网络,恰恰依然被英伟达牢牢掌控着。
在GPU赛道上演过一次的剧本,正在互联网络这条赛道上酝酿重演。
3月12日,中科曙光正式发布首款全栈自研的400G原生无损RDMA高速网络——scaleFabric,从底层的112G SerDes IP、硬件设备到上层管理软件实现100%自研。中国工程院院士邬贺铨评价称,scaleFabric"补齐了国产高速网络的短板"。这款产品的问世,填补这个浮出水面的关键空白。

十万卡集群的"生死线"
拆开大规模智算集群的运作逻辑,就能看清这根"传送带"为何如此致命。
训练一个万亿参数的大模型,单张GPU的算力远远不够,必须将数以万计的加速卡组成集群协同计算。在分布式训练中,每一轮迭代结束后,所有节点都需要同步各自计算出的梯度参数——这个过程叫做AllReduce。它要求集群中每一个节点几乎在同一时刻完成数据交换,任何一个节点的通信延迟,都会拖慢整个集群的训练进度。
当集群规模从千卡扩展到万卡,参与同步的节点数量增长了十倍,但节点间的通信路径和潜在冲突是指数级增长的。研究表明,在大规模分布式训练中,网络通信耗时占比已达到30-50%。这意味着花重金购入的计算卡,有将近一半时间不是在计算,而是在等数据搬运完成。
中科曙光高级副总裁李斌在产品发布会上直言:"计算决定了计算系统性能的上限,但是如果是网络系统拉垮的话,有可能会把整个性能下限归零了。"他在会后对观察者网进一步解释,十万个节点要协同好,"能稳定跑上一个小时、两个小时,这个技术挑战非常大"。
北京科技大学 计算机与通信工程学院储根深从用户角度印证了这一判断:在以往的大规模计算中,"大部分的时间是在通信方面",算力利用率往往只有百分之六七十。"在硬件上把通信的性能补齐之后",利用率可以提升到80%至90%。在算力极度昂贵的今天,每提高十个百分点的利用率,都是真金白银。
这个需求的规模正在急剧膨胀。
过去以CPU为核心的计算节点,一台服务器只需要一张网卡;如今以GPU为核心,一台机器要出八张甚至更多。李斌算了一笔账:"相比原来的数据中心高速网络的用量,基本上提高了10到20倍。"网络已经从算力基础设施的配角,变成了增量最大的主角。
悬在国产算力头顶的断供风险
制造这根顶级"传送带"的核心技术,长期以来并不在中国企业手里。
目前,数据中心高速网络领域存在两条主流技术路线。一条是RoCE(RDMA over Converged Ethernet),本质上是在传统以太网基础上嫁接RDMA远程直接内存访问能力。这条路线的优势在于兼容现有以太网基础设施,部署门槛较低,国内也有不少厂商在做。但它的问题同样明显:以太网本身并非为高性能计算设计,在超大规模集群场景下,拥塞控制、无损传输和扩展性都存在天然短板。
另一条是InfiniBand(IB)原生路线,这是一套从底层协议栈开始就专为高性能计算和低延迟通信量身定制的技术体系。在带宽、时延、无损传输等关键指标上,IB都是公认的顶级水准。
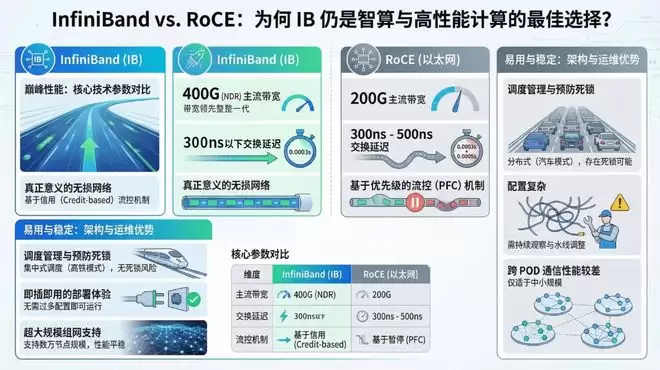
根据TOP500榜单,目前全球约60%的高性能计算系统采用InfiniBand网络架构。在全球最大规模的AI训练集群中,IB更是近乎标配。
但IB路线面临一个严峻的产业现实:尽管IB协议本身是开放标准,但核心交换芯片、商用设备、生态适配几乎被英伟达独家掌控。
更关键的是,这不仅是技术壁垒,还在演变为商业捆绑。英伟达收购IB之后,在推进过程中绑定越来越紧密,除了技术上,还有商业模式上的绑定。
对于正在崛起的国产AI算力而言,这是一个极其危险的信号。当你倾尽全力造出了国产大模型和国产算力卡,准备搭建万卡甚至十万卡集群时,却发现唯一满足需求的互联网络只存在于别人的封闭生态里。如果说计算芯片的断供是"明面上的封锁",那么高速互联网络的垄断,就是随时可能勒紧的"暗门"。
计算“卡脖子”之外,可能马上就是网络,其实现在已经感受到了。
被逼出来的全栈自研
面对这堵墙,中科曙光的研发团队最初也试图找到一条更快的路。
项目启动之初,团队系统评估了几乎所有可行的技术捷径:直接购买成熟的IB链路IP做集成、在开源方案基础上二次开发、或者退而求其次走RoCE路线。
但评估结果令人沮丧——市面上可获取的IP达不到支撑超大规模集群的性能和可靠性要求;开源方案的性能天花板太低;而RoCE路线虽然上手快,但从根本架构上无法提供原生IB的无损传输和极致时延。
中科曙光高速网络互联产品部总工程师万伟坦言了当时的困境:"一开始我们打算买一些IB的(链路IP),但是发现确实都不符合我们的要求,我们最后只有招团队专门做这个事情。"
所有捷径都走不通,只剩下一条最难的路:从底层物理层开始,全栈自研一套原生IB体系。
这意味着要从零搭建一个完整的技术垂直栈——最底层是112G SerDes高速串行接口IP,这是决定信号传输质量的物理基础,与芯片制造工艺强相关,是整个链条中最硬的"硬骨头";往上是自研的交换芯片,负责海量数据包的高速转发和路由调度;再往上是基于这些芯片打造的网卡和交换机硬件;最顶层则是驱动程序、网络管理软件以及与上层通信库的适配。从晶体管级到应用层,每一层都必须自己啃下来。
李斌回忆这段历程时没有回避不确定性:"这个过程我们做的非常痛苦,最开始做的时候,也没有那么多信心说这个出来能达到IB的水平。"
但结果超出预期,恰恰是因为团队此前长期使用海外IB产品,对其设计中的不足了如指掌。李斌说:"我毕竟是站在巨人肩膀上,原来我们用他的产品也非常多,他中间不太好的设计,我们自研的过程中可以改进,可以去规避。"
最终交出的scaleFabric 400系列产品,核心技术指标为:端到端通信时延低至0.9微秒,链路故障恢复时间小于1毫秒,单子网互连规模达到传统InfiniBand的2.33倍,理论可支持最大11.4万卡集群部署。
万伟对观察者网表示,"这是网卡性能的上限”。这跟英伟达CX7在同一个水平线上,交换机单端口带宽800Gbps,整机交换容量达双向64Tbps,交换时延约260纳秒。与英伟达NDR相比,交换机端口密度提升25%,网卡最大QP数支持提升100%,同时网络总成本降低约30%。
储根深作为独立的高校用户,给出了自己的评价:"其实这两个差不多同一层次,甚至我们比他高。"他特别补充了一个前提——曙光目前主要是在国产硬件和算力上完成的验证,"英伟达最新的GPU,我们很难买到"。换句话说,这个成绩是在受限条件下取得的。
这些也不只是纸面参数。这套国产网络已在国家超算互联网位于郑州的核心节点稳定运行超10个月,支撑起3万卡规模的智算集群,承载真实大模型训练任务。该网络系统仅用36小时便完成三套万卡级集群的网络部署上线。国产原生RDMA网络,已经从"能不能做"跨入了"能不能用好"的阶段。
这标志着中国在智算基础设施的关键一环——高速网络领域,已从"跟跑"走向"并跑"。
用开放生态给出"国产答案"
打破旧的垄断,绝不意味着要建立一个新的封闭帝国。
海外巨头的强大,很大程度上来自从芯片到网络到软件的闭环生态锁定。但中国算力产业的格局不同——当前国内多款AI芯片百花齐放,如果高速网络也走绑定路线,只会制造新的内耗。李斌的态度很明确:"别一家独大,把整个技术做开放,市场的蛋糕大家共享。"
不过,李斌对InfiniBand的定性并非简单的"封闭"二字。"从某种意义上说,英伟达体系内构建了自身闭环生态。"但他同时指出,"它有自己的协议、标准组织,某种意义上也是开放的。"中科曙光的策略,是在继承InfiniBand开放性的基础上,打破其在英伟达体系内的商业绑定。
因此,scaleFabric从第一天起就确立了开放逻辑:提供标准化网络接口,不做自家业务的强制绑定,向下兼容国内不同厂商的算力芯片。在技术路线上也预留了融合空间——未来将在原生RDMA基础上探索对RoCE的兼容,让不同路线的用户都能接入。
与此同时,中科曙光牵头在光合组织下成立了AIDC高速网络工作组。

曙光信息产业(北京)有限公司副总裁李柳解释了工作组要做的核心事情:建立统一技术标准——"未来的标准不建立起来,还是让大家走很多无效的路径";基于开放平台做生态适配,让更多用户使用和反馈;联合国内科研力量,推动产学研用协同。
这种开放策略的底层逻辑很清晰:要瓦解一个封闭生态,靠一家公司远远不够,必须让整个国产产业链都能参与进来。
从显性的计算芯片,到隐性的互联网络,中国算力产业正在一步步夺回底层基础设施的自主权。当万卡乃至十万卡集群成为大模型训练的常态配置时,我们终于可以确认:在这座庞大的超级数字工厂里,不仅有了国产的"心脏",也真正接管了至关重要的"动脉"。




