MIT新算法挑战传统强化学习:后训练时代还继续有效吗?

机器之心编辑部
在当前的 LLM 开发中,后训练阶段通常被视为赋予模型特定能力的关键环节。传统的观点认为,模型必须通过强化学习(如 PPO、GRPO 或 RLHF)和进化策略(ES)等算法,在反复的迭代和梯度优化过程中调整权重,才能在特定任务上达到理想的性能。
然而,MIT CSAIL 的研究人员 Yulu Gan 和 Phillip Isola 在他们最新发布的论文中对这一传统认知发起了挑战。他们提出了一种名为RandOpt的新方法,通过简单的随机扰动和集成来突破传统后训练的限制。

论文标题:Neural Thickets: Diverse Task Experts Are Dense Around Pretrained Weights论文地址:https://arxiv.org/pdf/2603.12228
这一发现对大模型参数空间的理解具有颠覆性意义。早在 2001 年,Schmidhuber 等人提出「随机猜测」不能算作一种有效的学习算法,认为「优秀的解决方案在权重空间中的分布必须极其稀疏」。然而,Gan 和 Isola 的研究揭示了一个反直觉的现象:在完成预训练后,LLM 模型的权重空间实际上形成了一个密集的「神经丛林」(Neural Thickets),这一状态促使简单的随机采样就能发现有效的解决方案。

论文指出,预训练模型不仅仅是后训练的「起点」,其权重空间内已潜藏着大量任务专家。随着模型规模的增大,这些专家在权重空间中的分布密度急剧增加,足以让随机扰动和集成方法有效捕捉优越的解决方案。
基于这一理论,RandOpt 算法的操作方式非常简单:只需向预训练模型添加单步的高斯噪声(无需任何迭代、学习率或梯度计算),并对多个扰动后的模型副本进行集成。实验结果表明,仅凭这一极简的操作,模型就能够在数学推理、代码生成等复杂任务中达到,甚至超越 PPO 或 GRPO 等传统后训练方法的性能。
通过这一创新方法,RandOpt 为后训练的简化提供了新的可能,展示了预训练模型本身已隐含了丰富的任务专家,后训练过程更多是选择和集成这些专家,而非从零开始训练新能力。
这篇论文一经发布便在 AI 社区引发了轰动,不仅迅速登上 alphaXiv 榜单第二,其作者在 X 上的宣传帖子也获得了近 50 万的浏览量和极高的互动,谢赛宁也转发了该工作。


许多从业者和研究人员惊呼:「强化学习在后训练就死了?」「强化学习泡沫破裂?」。
尽管有人对其在细粒度对齐任务上的泛化能力持保留态度,但这种极简算法背后所揭示的参数空间现象,无疑迫使我们重新思考预训练与后训练的本质关系。
预训练权重的「丛林效应」
论文指出,模型规模决定了这些专家在参数空间中的分布形态:
小模型(大海捞针机制):未经过充分训练或规模较小的模型,在其初始权重附近的优秀解决方案密度极低。它们处于「大海捞针」的状态,发现有效解必须依赖梯度下降等结构化的多步搜索算法。大模型(神经丛林机制):大型且经过充分预训练的模型,其预训练权重周围密集地分布着大量能提升特定任务性能的专家。在这种状态下,仅靠随机采样就足以快速找到有潜力的适应性模型。
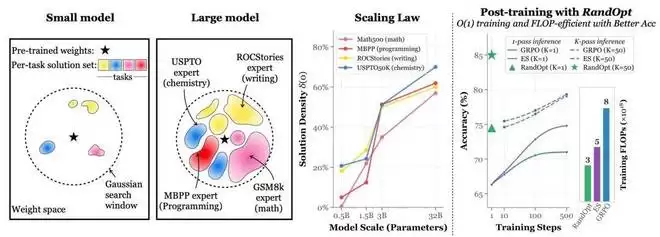
小模型(左)的大海捞针机制与大模型(右)的神经丛林机制示意图。大模型周围充满了代码专家、数学专家等特定任务的解决方案集。
为了量化这一现象,研究测量了两个核心指标:
解决方案密度:随机扰动能使基础模型性能提升特定幅度的概率。实验表明,这种密度呈现出明显的缩放定律:模型参数规模越大,其性能越好,周围高质量解决方案的密度就越高。解决方案多样性:这些随机采样出的好模型是「专才」而不是「通才」。一个扰动如果在一个特定任务上大幅提升了性能,往往会降低在其他任务上的性能。论文引入了「光谱不一致性」指标来衡量,发现随着模型规模增加,解决方案的多样性也单调增加,这意味着大模型周围的专家在能力上越来越互补且互不重叠。
为了直观展示神经丛林的存在,研究团队对参数量从 0.5B 到 32B 的 Qwen2.5 预训练模型注入了 1000 个随机权重扰动,并通过随机投影技术将其准确率景观可视化到了二维平面上。
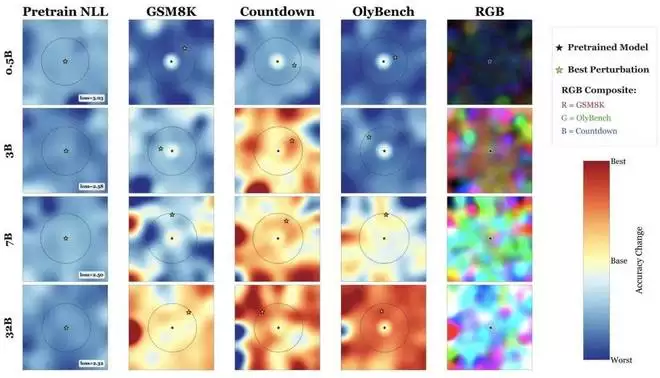
实验清晰地呈现了 Scaling Law:随着模型规模的扩大,景观中代表更高准确率的「红色区域」(即任务改善区域)显著增多并变得更加密集。
简而言之,大模型所处的参数空间不仅是一个宽阔的平原,其周围更是一个布满不同任务局部最优解的「盆地」。
那么,究竟是什么导致了这种奇特的「神经丛林」的涌现?
1D 信号预测实验揭示了这一现象的根本原因。研究者使用多层感知机(MLP)对混合的一维信号(如正弦波、方波等)进行自回归预测的预训练。通过对比不同预训练策略,实验揭示了三个阶段:
无预训练(大海捞针期):在随机初始化下,微小的权重扰动对模型功能几乎没有影响,好的解决方案距离极远,随机采样完全失效。单一任务预训练(高原期):如果只在单一信号(如仅线性函数)上预训练,模型在测试该任务时已经达到性能天花板(处于平缓的极小值处),但周围的权重没有展现出任何功能多样性,随机猜测无法带来额外收益。混合多任务预训练(丛林诞生期):只有当模型在多种不同的信号类型上进行过混合预训练后,参数空间才会孕育出能在不同方向上拟合不同信号的「专家丛林」。

1D 信号预测实验展示了三种机制。只有在「混合信号预训练」下(图 b),权重扰动才会炸开成形态各异的函数预测,形成神经丛林。
这也解释了为什么在海量混合数据上预训练的大语言模型,会天然自带一片生机勃勃的「专家丛林」。
RandOpt 算法:单步、无梯度、极致并行
基于「密度高」且「多样性强」的神经丛林现象,作者探索了一种极其简单且完全并行的后训练算法RandOpt。作者将其定义为:单步、无梯度、无学习率、无迭代、完全并行。

RandOpt 的操作避开了所有序列化的梯度更新,主要分为两个阶段:
训练(随机猜测与检查):算法从标准高斯分布中采样出 N 个随机种子和对应的噪声尺度,将其直接加到基础模型的权重上,生成 N 个扰动后的模型副本。随后,让这些模型在一个小的训练集(或验证集)上运行,并根据得分选出表现最好的 Top-K 个模型。推理(预测集成):在面对测试输入时,算法利用筛选出的 K 个模型分别生成预测,最终通过多数投票机制聚合这些预测,得出最终答案。
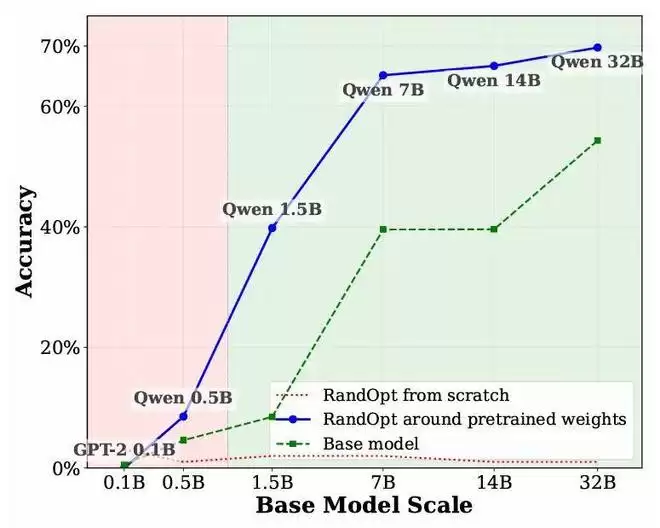
RandOpt 性能与基础模型规模的关系。图表显示,如果从头开始使用 RandOpt(不进行预训练),性能几乎为零;而对于经过预训练的模型,在参数量达到约 1.5B 时,RandOpt 的性能提升开始迎来爆发。
这种机制的一个关键特性是它完全不需要计算梯度,也不涉及任何序列化的优化步骤,所有的模型生成和评估都可以完全并行处理。
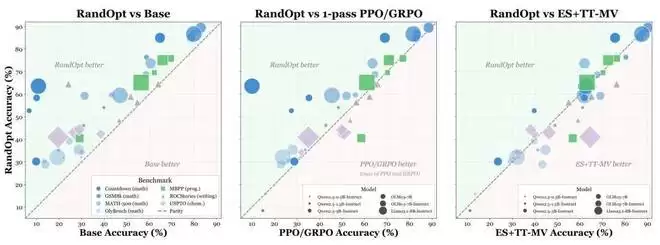
RandOpt 与传统方法的对比
这种看似「简单粗暴」的方法,在实际基准测试中展现出了惊人的战斗力。研究团队在跨越 0.5B 到 8B 参数规模的多个模型(Qwen、Llama、OLMo3)上,对数学推理(Countdown、GSM8K 等)、代码生成(MBPP)、创意写作(ROCStories)以及化学(USPTO)任务进行了全面测试。
在消耗相同训练 FLOPs(浮点运算次数)的前提下,RandOpt(通常设置 K=50)在绝大多数设定中不仅追平,甚至超越了 PPO、GRPO 和 ES 等标准后训练方法。
此外,RandOpt 在训练时间(Wall-clock time)上具有颠覆性的优势。传统基准方法需要运行数百个序列化更新步骤(时间复杂度为 O(T)),而 RandOpt 的训练步骤是 O(1)。论文指出,在一组包含 200 个 GH200 GPU 的集群上使用 RandOpt 训练 OLMo-3-7B-Instruct 模型,设定 N=2000 和 K=50,仅需 3.2 分钟即可完成,并在 Countdown 任务上达到 70% 的准确率。
不仅是语言模型,RandOpt 同样适用于视觉语言模型(VLM)。在冻结视觉编码器、仅扰动语言模型权重的情况下,RandOpt 将 3B 参数的 Qwen2.5-VL-Instruct 模型在 GQA 视觉推理数据集上的准确率提升了 12.4%。
提升究竟来自哪里?代价又是什么?
为了验证模型能力的真实来源,作者在 GSM8K 数据集上对性能提升进行了细致的错误归因分解。
数据表明,对于集成后达到 86.7% 准确率的 RandOpt(K=50),其提升中有19.0% 来源于「格式丛林」(Format Thicket)(即基础模型算对了,但输出格式不符合严苛的评估要求,扰动模型修正了格式);更重要的是,有12.3% 来源于真实的「推理丛林」(Reasoning Thicket)(即基础模型原本算错,而扰动后的模型真正学会了正确的推理并得出正确答案)。这一结果有力地证明了,神经丛林中确实存在着掌握不同实质性技能的专家,而不仅仅是表面的格式微调。
不仅如此,这种丛林现象在文本到图像生成领域(如 Stable Diffusion XL 模型)中表现为「色彩丛林」(Color Thickets)。某些参数空间的局部区域会优先生成具有特定调色板(如蓝色或黄色主导)或视觉风格的图像,展现出了极高的生成多样性。

RandOpt 在推理时需要进行 K 次前向传播,这对实际部署是不利的。为了解决这一问题,研究者提出了一种蒸馏方案:他们利用 RandOpt 筛选出的 Top-50 模型生成数万条包含推理轨迹的响应,然后从中挑选出基础模型容易出错的「困难样本」。接着,只对基础模型进行两轮监督微调。
实验结果令人振奋:在 GSM8K 上,蒸馏后的单一模型性能(84.3%)与庞大的集成模型(87.1%)极为接近,而这个蒸馏过程的计算成本仅占 RandOpt 训练成本的约 2%。
更多细节请参见原论文。
相关攻略

近日,开源具身智能原生框架Dexbotic宣布正式支持以RLinf作为其分布式强化学习后端。对具身智能开发者而言,这不仅是一次普通的工程适配,更意味着VLA模型研发中长期存在的「SFT与RL割裂」问题,正在被真正打通。 这是一种典型的「乐高式协作」:双方不强行Fork、不粗暴揉合代码,而是保持清晰边

随着大模型参数规模不断增长,混合专家(Mixture-of-Experts, MoE)架构因其稀疏激活特性,成为平衡模型性能与计算开销的主流方案。然而,在实际的Web级应用部署中,一个关键挑战日益凸显:传统MoE的路由机制通常是“无记忆”的。 试想,在搜索引擎、智能问答或多轮对话等高并发场景下,用户

编程十年的一点分享 在软件开发的路上走过十几年,从一个爱好者到以此为业,有些体会或许值得聊聊,就当是抛砖引玉吧。 最早接触编程,是从BASIC和C语言开始的。工作后,随着需要,陆续学习了dBase、Access这类桌面数据库的开发。真正以开发为职业,可以说始于FoxPro 5 0,之后技术栈随着项目

引言 编程,是一门实践科学。这意味着,学习它的最佳方式就是动手去敲代码。但这是否意味着,我们可以因此轻视理论的学习呢? 入门编程 如果你去各大技术社区提问“该如何入门编程”,五花八门的答案会瞬间涌来。 不过,仔细梳理一下,无外乎以下几种流派: 学院派 他们推荐从C语言入手,并辅以数据结构、操作系统等

想象一下这个场景: 你让 AI Agent 帮你修一个代码 Bug。它打开项目,读了 20 个文件,改了改,跑了一下测试,没过,又改,又跑,还是没过……来回折腾了十几轮,终于——还是没修好。 你关掉电脑,松了口气。然后收到了 API 账单。 上面的数字可能让你倒吸一口凉气——AI Agent 自主修
热门专题







热门推荐

机器人行业迎来里程碑式突破。以视频生成模型Vidu著称的生数科技,正式发布了名为Motubrain的“世界动作模型”。这并非一次普通迭代,而是被定位为机器人的“物理大脑”,其核心目标在于:用一个统一的通用模型,彻底取代以往依赖多个专用系统拼凑而成的复杂架构。 正如其“一个大脑,无限可能”的口号所揭示

xAI正式进军AI编程智能体领域,于近日发布了专为软件工程与复杂编程任务设计的Grok Build。 简单来说,Grok Build是一款能在终端里直接跑起来的AI编程助手。它被定位为一个具备智能体能力的命令行工具,开发者用自然语言告诉它要做什么,它就能生成代码,甚至帮你搞定一系列编程和自动化任务。

近日,谷歌对其搜索引擎的核心规则进行了重要更新,此次调整直指当前备受关注的AI搜索领域。具体而言,谷歌在其垃圾内容政策中新增了明确条款,正式将“操纵AI搜索结果”的行为列为违规操作,划定了新的质量红线。 根据权威行业媒体Search Engine Land的报道,本次谷歌算法更新的核心在于,将任何企

硅谷的科技巨头们或许曾以为,自己已经远离了AI数据中心带来的电力压力——毕竟,高昂的地价和电费早就把大型数据中心项目“赶”到了别处。但现实总是出人意料,这场能源危机的涟漪,正悄然涌向他们心爱的度假后院。 没错,说的就是太浩湖。这个湾区精英们钟爱的避世天堂,如今正站在一场电力风暴的边缘。距离它必须找到

这项由高通AI研究院(Qualcomm AI Research)主导的创新研究于2026年5月正式发布,论文预印本编号为arXiv:2605 07721。 研究背景:当AI越想越费内存,我们该怎么办 设想一下,手机导航应用会在出发前规划好整条路线,而一位真正智慧的向导则会边走边思考,遇到路障时灵活应