MoE推理的正确玩法:跳过88%专家保住97%性能 | CVPR 2026
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
新智元报道
编辑:LRST
【新智元导读】CVPR新研究MoDES让多模态大模型推理效率飙升:无需训练,智能跳过88%冗余专家,仍保留97%性能,彻底打破「跳得多必掉点」旧认知,推理速度提升2倍。
多模态大模型正在迅速走向大规模。为了处理更高分辨率图像、更长视频序列以及更复杂跨模态任务,模型参数规模持续增长。
Mixture-of-Experts(MoE)架构成为主流选择:通过只激活部分专家网络,试图在保持模型规模的同时降低计算开销。
但问题在于——即便采用 MoE,多模态模型的推理成本依然很高。
每个token仍需与多个专家交互,大量计算发生在「并非真正关键」的专家上。MoE 的确避免了「全参数全激活」,却没有真正做到「按需计算」。
在视频理解或长上下文场景下,这种冗余会被迅速放大,成为推理瓶颈。
于是,一个自然问题出现:能否在推理阶段动态跳过冗余专家?
已有expert skipping方法在纯文本LLM上取得了一定效果,但一旦直接应用于多模态模型,往往出现明显性能下降。跳得越多,掉点越严重,高比例skipping下甚至直接崩溃。
来自香港科技大学、北航、北大等单位的研究团队提出了MoDES(Multimodal Dynamic Expert Skipping),系统分析了多模态MoE skipping失效的根本原因,并给出了一套面向多模态MoE的training-free动态专家跳过框架,该工作已被CVPR接收。

论文地址:https://arxiv.org/pdf/2511.15690
代码地址:https://github.com/ModelTC/MoDES
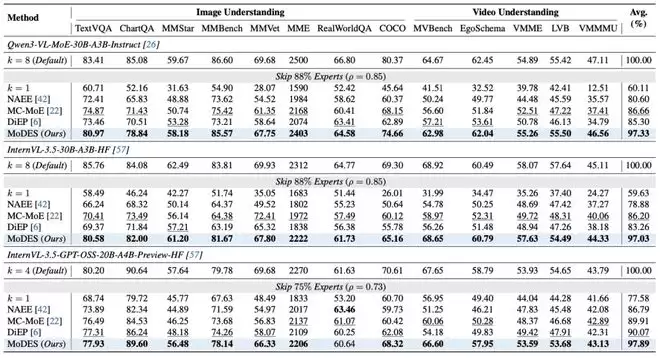
在Qwen3-VL-MoE-30B上,MoDES在跳过88%专家的情况下,仍保留97.33%原始性能,同时带来显著推理加速,打破了一个长期存在的共识:高比例专家跳过必然带来不可接受的性能损失。
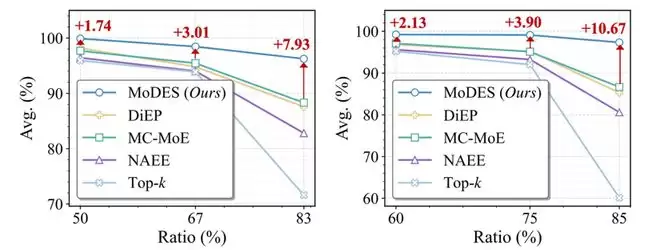
图表1 不同skipping比例下MoDES与现有方法在13个基准上的性能对比
MoDES并没有直接提出新规则,而是首先回答一个更基础的问题:为什么为文本模型设计的skipping方法,在多模态MoE上会明显失效?
论文给出了两个关键观察。
不同层专家对最终输出的全局贡献高度不均衡:现有skipping方法通常仅依据当前层的routing概率判断专家是否重要,但忽略了一个关键事实:不同层专家对最终预测分布的影响差异巨大。
实验表明,当减少routed experts数量时,浅层专家的减少会导致更显著的性能下降,而深层专家的影响相对较小。这意味着浅层误差会在后续层逐步放大,从而引发性能崩溃。
换言之,专家的重要性不仅是「局部routing概率」的问题,更是「对最终输出影响程度」的问题。如果采用层无关的统一规则,很容易在关键浅层跳得过多。相关现象如图表2所示。
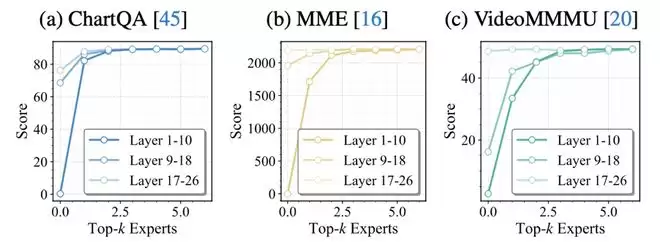
图表2 不同层范围减少专家后的性能变化
文本token与视觉token行为存在显著差异:论文进一步分析了模态差异。通过对FFN前后token表征的可视化与统计分析,研究者发现:文本token在FFN中的更新幅度明显更大;视觉token与专家权重更接近正交;专家对视觉token的影响相对较小。
这意味着,专家对文本推理更关键,而对视觉token存在更高冗余。如果skipping策略不区分模态,很可能误删对文本理解至关重要的专家,导致性能下降。相关分析见图表3。
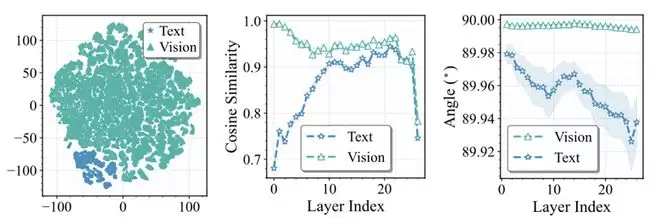
图表3 文本与视觉token在FFN中的差异分析
这两个观察共同指向一个核心结论:多模态MoE的专家重要性,需要同时具备output-aware(输出感知) 与modality-aware(模态感知)。
输出感知+模态感知
动态skipping框架
基于上述insight,MoDES构建了一个输出感知、模态感知的动态专家跳过机制,其整体流程如图表4所示。
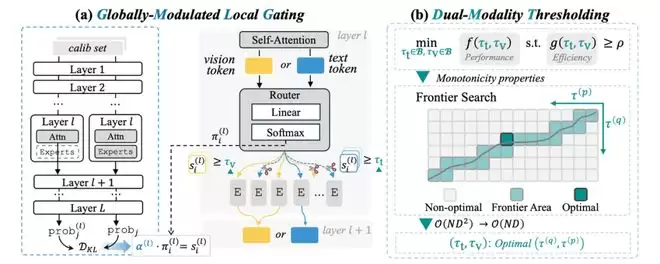
图表 4 MoDES框架图
首先,MoDES在原始routing概率基础上引入层级全局重要性因子,用于刻画第
l层专家对最终输出分布的整体影响。
该因子通过离线校准获得,即比较移除该层专家前后模型输出分布的差异,从而量化该层专家的全局贡献。新的专家重要性分数由局部routing概率与全局因子共同决定。这样一来,浅层专家会被更保守地保留,而深层专家可以更激进地跳过,实现真正的output-aware skipping。
其次,MoDES引入双模态阈值机制,为文本token与视觉token分别设定不同的skipping阈值。通过模态区分,使专家跳过决策更加精细化,避免误删关键专家。
最后,为高效寻找最优阈值组合,MoDES设计了frontier search算法,利用性能与 skipping比例之间的单调性,将搜索复杂度从降为,在保证结果一致性的同时将搜索时间缩短约45倍。

图表5 校准与搜索时间对比
实验结果
在主实验中,QVGen在W4A4/W3A3在大规模实验中,MoDES在多个主流多模态MoE模型上进行了系统评估。
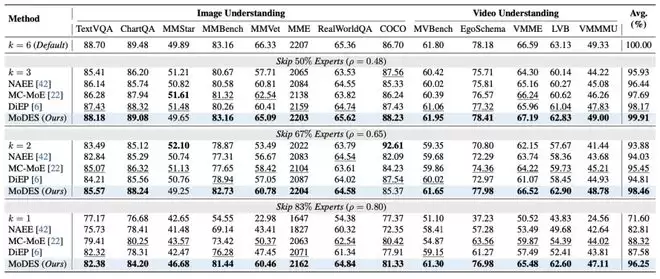
在Kimi-VL-A3B-Instruct上,当跳过83%专家时,多数现有expert skipping方法平均性能下降超过11%,而MoDES仍然保留96.25%原始性能(见图表 6)。这一结果说明,高比例skipping并不必然导致性能崩溃,只要专家的重要性建模足够准确,冗余专家可以被有效识别。
在更大规模的Qwen3-VL-MoE-30B-A3B-Instruct上,MoDES的优势更加明显。在跳过88%专家的条件下,MC-MoE仅保留86.66%性能,DiEP保留85.30%,而MoDES仍然能够保留97.33%原始性能(见图表 7)。在13个图像与视频理解基准上,MoDES均取得最优或接近最优表现。
图表6 Kimi-VL不同skipping比例性能对比
图表7 跨backbone性能对比
这一结果表明,高比例skipping并非不可行,关键在于是否能够正确建模专家对最终输出的全局贡献以及不同模态token的行为差异。
推理效率与量化兼容性
在实际推理测试中,MoDES在H200 GPU上实现了显著加速。在Prefill阶段获得约2×加速,在Decoding阶段仍有约1.2×提升(见图表 8)。由于MoDES为training-free方法,推理阶段不引入额外计算开销,因此加速效果更加稳定。
此外,MoDES与混合精度量化具有良好兼容性。在低比特量化条件下仍能保持较高性能,说明skipping与量化可以从结构与数值两个层面形成互补,共同降低多模态MoE的计算成本。
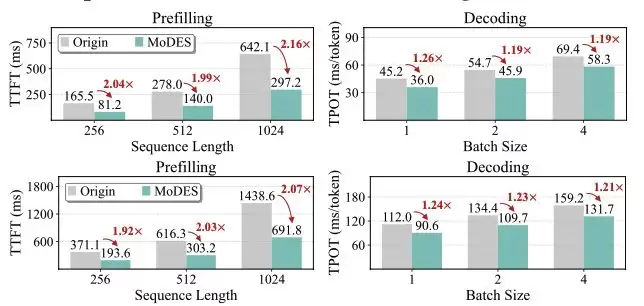
图表8 推理速度对比。(上)Qwen3-VL;(下)Kimi-VL。
总结
MoDES的核心贡献在于:提出了一种真正output-aware、modality-aware的多模态专家跳过机制。
通过显式建模不同层专家对最终输出分布的全局贡献,以及不同模态token在专家网络中的更新特性,MoDES证明了一件重要的事情:即便跳过80%以上的专家,只要跳得足够「聪明」,模型性能依然可以稳定保持。
在多模态模型规模持续扩大的背景下,这种基于输出影响建模的skipping思路,为大模型推理效率优化提供了一条更加稳健且可落地的路径。
参考资料:
https://arxiv.org/pdf/2511.15690
相关攻略

近日,开源具身智能原生框架Dexbotic宣布正式支持以RLinf作为其分布式强化学习后端。对具身智能开发者而言,这不仅是一次普通的工程适配,更意味着VLA模型研发中长期存在的「SFT与RL割裂」问题,正在被真正打通。 这是一种典型的「乐高式协作」:双方不强行Fork、不粗暴揉合代码,而是保持清晰边

随着大模型参数规模不断增长,混合专家(Mixture-of-Experts, MoE)架构因其稀疏激活特性,成为平衡模型性能与计算开销的主流方案。然而,在实际的Web级应用部署中,一个关键挑战日益凸显:传统MoE的路由机制通常是“无记忆”的。 试想,在搜索引擎、智能问答或多轮对话等高并发场景下,用户

编程十年的一点分享 在软件开发的路上走过十几年,从一个爱好者到以此为业,有些体会或许值得聊聊,就当是抛砖引玉吧。 最早接触编程,是从BASIC和C语言开始的。工作后,随着需要,陆续学习了dBase、Access这类桌面数据库的开发。真正以开发为职业,可以说始于FoxPro 5 0,之后技术栈随着项目

引言 编程,是一门实践科学。这意味着,学习它的最佳方式就是动手去敲代码。但这是否意味着,我们可以因此轻视理论的学习呢? 入门编程 如果你去各大技术社区提问“该如何入门编程”,五花八门的答案会瞬间涌来。 不过,仔细梳理一下,无外乎以下几种流派: 学院派 他们推荐从C语言入手,并辅以数据结构、操作系统等

想象一下这个场景: 你让 AI Agent 帮你修一个代码 Bug。它打开项目,读了 20 个文件,改了改,跑了一下测试,没过,又改,又跑,还是没过……来回折腾了十几轮,终于——还是没修好。 你关掉电脑,松了口气。然后收到了 API 账单。 上面的数字可能让你倒吸一口凉气——AI Agent 自主修
热门专题







热门推荐

5月12日,马来西亚吉隆坡成功举办了一场具有前瞻性的行业盛会——中国-马来西亚电动汽车、电池技术与新能源人才创新发展论坛。来自两国政府部门、领军企业、顶尖高校及国际组织的代表共聚一堂,深入交流了在未来产业协同、清洁能源技术创新及高端人才培养等核心领域的合作路径与机遇。 马来西亚第一副总理兼乡村及区域

具身智能要迈过的第一道硬门槛,从来都是量产。 过去几年,全球人形机器人行业反复印证了这一点:舞台演示可以很快,工程验证可以很快,视频传播也可以很快。但当一台机器人要从实验室走向产线,再走向客户现场,问题的复杂度会呈指数级上升。 特斯拉的Optimus就是一个典型的参照系。马斯克多次表达过对Optim

向朋友问路时,如果对方清楚路线,通常会立刻回答“直走然后左转”。但如果对方并不确定,往往会先停顿一下,犹豫地说“呃……好像是……往那边?”。这个开口前的短暂迟疑,往往比最终给出的答案更能说明问题——对方是否真的知道答案。 近期,美国天普大学计算机与信息科学系的一项研究,正是捕捉到了AI回答问题时类似

这项由浙江大学、华南理工大学、南京大学和北京大学联合开展的前沿研究,于2026年4月正式发布,其论文预印本编号为arXiv:2604 24575。 图像分割技术听起来或许有些专业,但它早已深度融入我们的日常生活。无论是智能手机拍摄的背景虚化人像、AI系统在CT影像中精准勾勒病灶轮廓,还是自动驾驶汽车

“大唐”预售热潮尚未平息,“大汉”已蓄势待发,比亚迪王朝系列正以前所未有的攻势,叩响高端市场的大门。 在北京车展引发轰动的比亚迪大唐,预售订单已迅速突破10万台大关,彰显了市场对比亚迪高端产品的强烈期待。而最新信息显示,汉家族即将迎来一位重磅新成员——“大汉”,这款定位D级旗舰的轿车,目标直指20-