3月4日,谷歌正式发布Gemini 3.1 Flash-Lite,宣称这是Gemini 3系列中速度最快、性价比最高的模型。该公司表示,3.1 Flash-Lite专为开发者的大规模、高吞吐量工作负载而设计,在其价格区间和模型级别中展现出极高的质量。
即日起,3.1 Flash-Lite将通过Google AI Studio中的Gemini接口向开发者开放预览版,并通过Vertex AI面向企业用户推出。
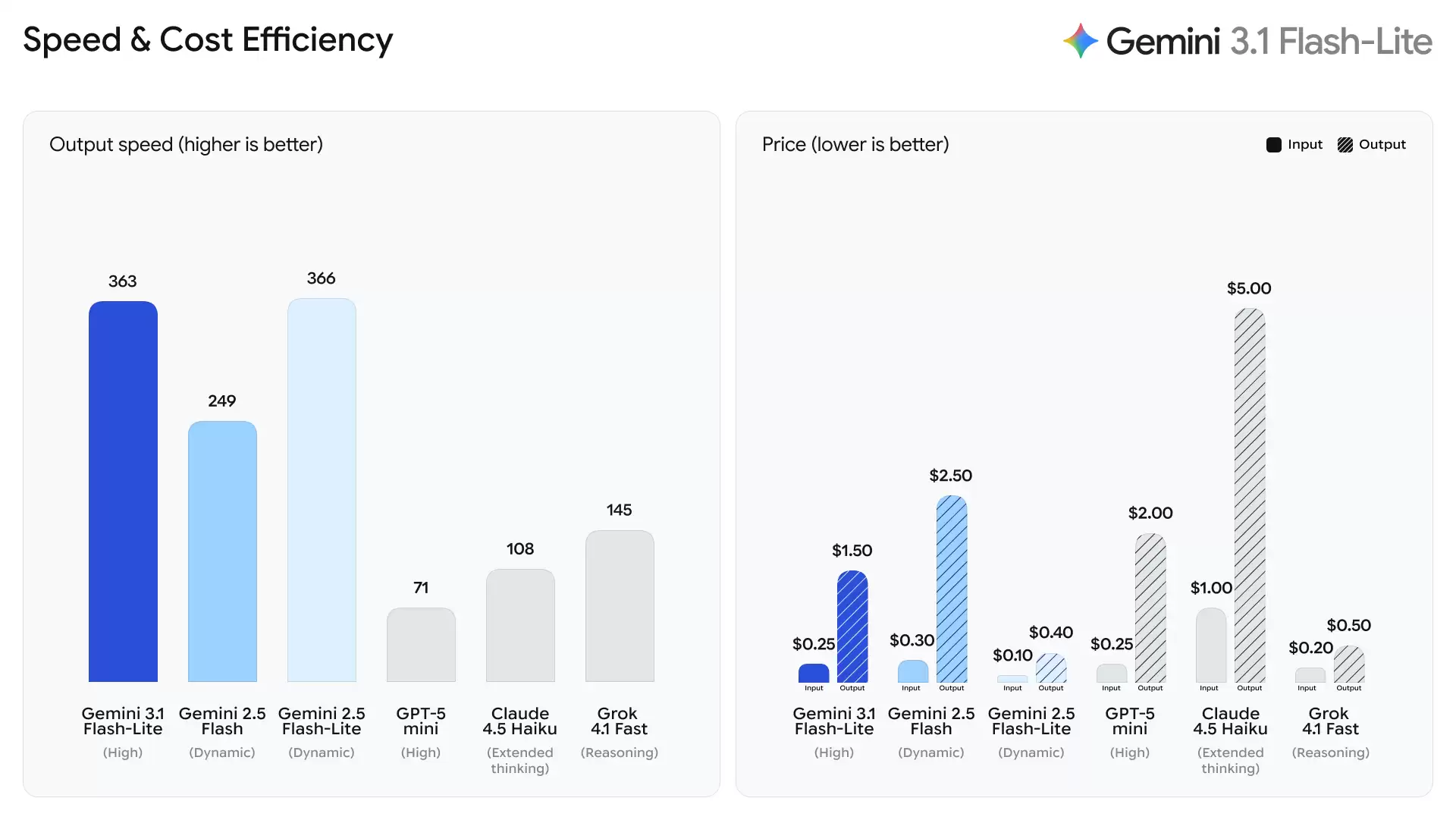
3.1 Flash-Lite每百万输入Token收费0.25美元,每百万输出Token为1.50美元。根据Artificial Analysis的基准测试,3.1 Flash-Lite在保持同等或更高质量的前提下,性能表现优于2.5 Flash。其首字响应速度提升了2.5倍,输出速度也增长了45%。谷歌称,这种低延迟特性是高频工作流的必备条件,使其成为开发者构建响应式实时体验的理想模型。
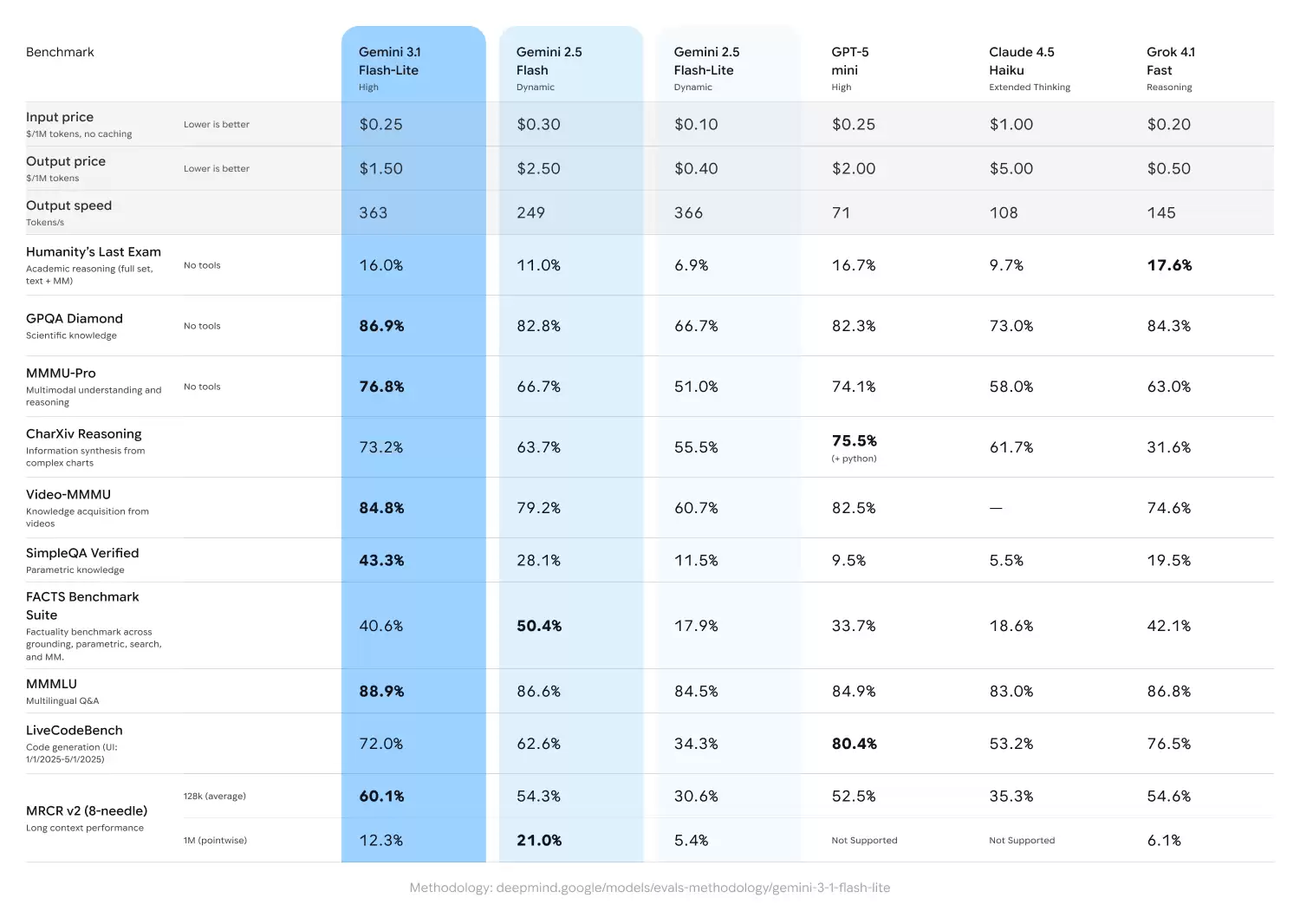
3.1 Flash-Lite在Arena.ai排行榜上获得了1432分。在推理和多模态理解的各项基准测试中,它的表现均超越了同级别的其他模型。例如,它在GPQA Diamond测试中取得了86.9%的成绩,在MMMU Pro测试中获得了76.8%的成绩。这一表现甚至超越了前几代体积更大的模型,如2.5 Flash。
除了原生性能外,Gemini 3.1 Flash-Lite在AI Studio和Vertex AI中还标配了“思考等级”功能。这让开发者能够灵活控制模型针对特定任务的“思考”深度,对于管理高频工作负载而言,这一功能至关重要。3.1 Flash-Lite能够处理大规模任务,例如对成本敏感的大批量翻译和内容审核。同时,它也能胜任需要深度推理的复杂工作,例如生成用户界面和仪表板、创建模拟环境以及遵循复杂指令。
谷歌表示,AI Studio和Vertex AI的早期接入开发者,以及拉提图德、卡特维尔和威灵等公司,已经开始使用3.1 Flash-Lite来解决大规模的复杂问题。早期测试人员强调了3.1 Flash-Lite的效率和推理能力。他们表示,该模型能够以大体量模型的精度处理复杂输入,并能严格遵循指令,保持高度的一致性。




