编辑|Panda
Alex Radford,出生于1993 年 4 月,即将 33 岁,但已经拥有超过 32 万的引用量。因为这位「独立研究员」不仅是 GPT、GPT-2 和 CLIP 的第一作者,同时还参与了 GPT-3、GPT-4、PPO 算法等多个重大研究项目。
近日, Anthropic 和斯坦福研究者 Neil Rathi 与这位传奇研究者联合发布了一篇新论文,并得到了一些相当惊人的新发现。
在这项研究中,他们挑战了当前大模型安全领域的一个核心假设。长期以来,业界普遍认为要在模型发布后通过 RLHF 或微调来限制其危险行为。但 Neil Rathi 和 Alec Radford 提出了一种更本质的解法:在预训练阶段,通过 Token 级别的数据过滤,直接从「大脑」深处切除危险知识。

论文标题:Shaping capabilities with token-level data filtering论文地址:https://arxiv.org/abs/2601.21571代码地址:https://github.com/neilrathi/token-filtering
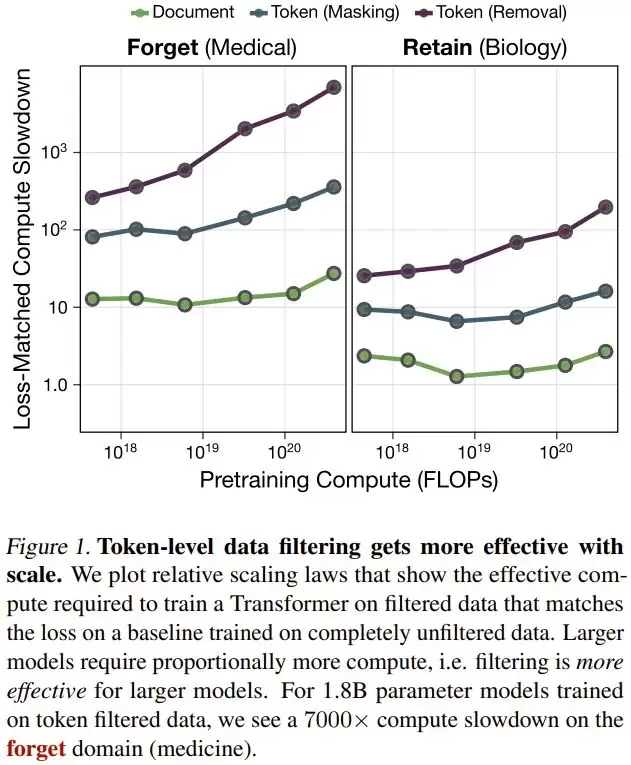
这项研究不仅证明了这种方法的可行性,更揭示了一个令人兴奋的 Scaling Law:模型越大,这种过滤机制的效果越好。
对于 18 亿参数的模型,Token 级过滤能导致目标领域的学习效率下降 7000 倍。
这意味着,攻击者想要恢复被删除的能力,将付出难以承受的算力代价。下面我们就来详细看看这项研究。
为什么我们需要在预训练阶段「动手术」?
目前,减少大语言模型有害能力(如制造生物武器、策划网络攻击)的主流方法大多是事后干预(Post hoc)。无论是 RLHF(基于人类反馈的强化学习)还是最近兴起的「机器遗忘」(Machine Unlearning),本质上都是在模型已经学到了所有知识之后,再通过一层「护栏」来抑制其输出。
这种做法存在一个巨大的安全隐患:猫鼠游戏。
一旦基础模型掌握了某种能力,单纯的对齐微调很难将其彻底根除。攻击者可以通过「越狱」或对抗性微调轻松绕过这些防御,重新激活模型深层的危险能力。
这就好比一个人已经学会了造炸弹,你只是命令他「不要说」,但只要换一种问法或者施加一点压力,他依然能造出来。
Rathi 和 Radford 的思路则截然不同:他们主张在预训练阶段就进行干预,通过调整训练数据,让模型根本就没有机会学到这些危险能力。
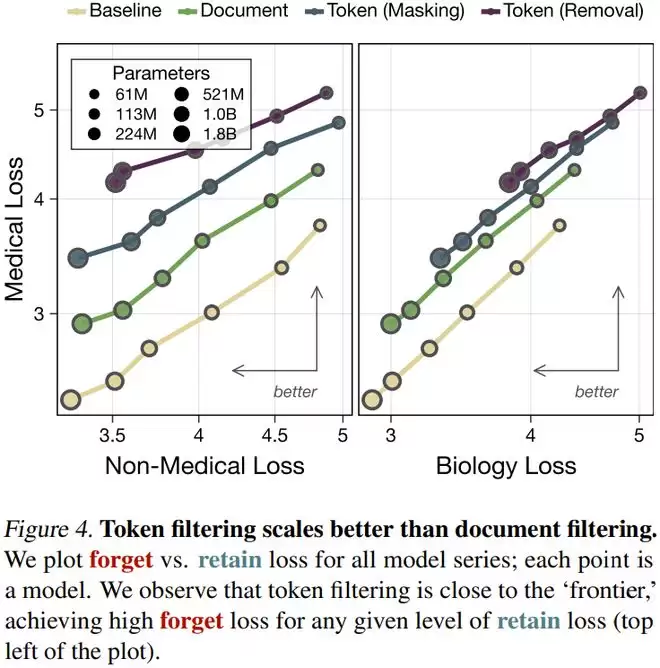
为了验证这一思路,他们选择了一个具有代表性的代理任务:移除「医学知识」(作为危险知识的替身),同时尽可能保留「生物学知识」(作为有益知识的替身)。这是一个极具挑战性的任务,因为医学与生物学在概念上高度重叠,很难在切除前者的同时不伤害后者。
Token 级过滤:手术刀般的精准
传统的预训练数据清洗通常是基于「文档」级别的。如果一篇文章包含有害内容,整篇文章就会被丢弃。这种做法不仅浪费数据,而且极其粗糙。
这篇论文的核心创新在于引入了 Token 级别的过滤机制。研究者认为,危险知识往往并不分布在整篇文档中,而是潜伏在特定的词句序列里。
团队测试了两种 Token 级过滤策略:
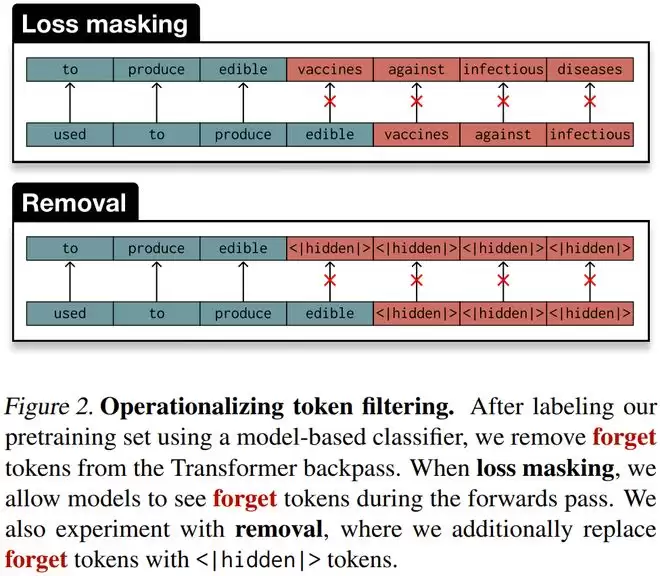
损失掩码(Loss Masking):模型在训练时可以看到危险的 Token,但在计算梯度和更新权重时,这些 Token 产生的损失会被忽略。这保证了上下文的连贯性,但切断了模型从中学到知识的路径。移除(Removal):更加激进的做法,直接将危险 Token 替换为特殊的标记。这不仅切断了梯度,甚至剥夺了模型看到这些词的机会。
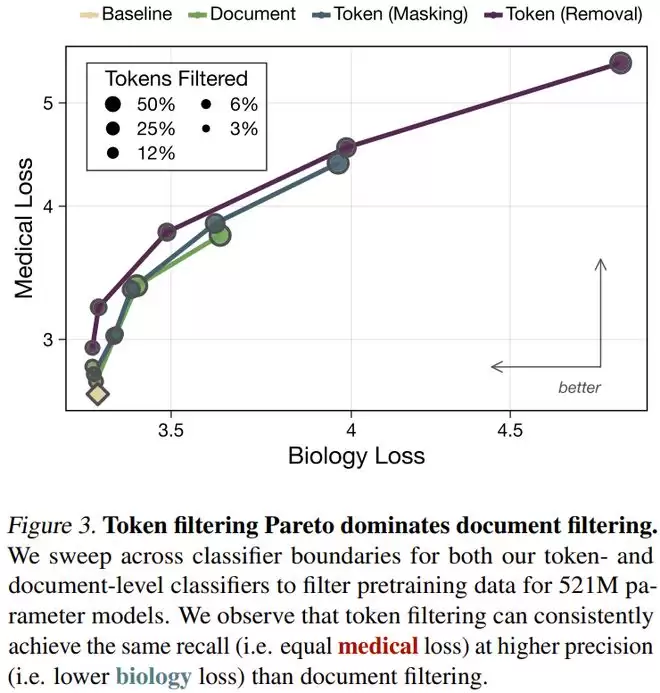
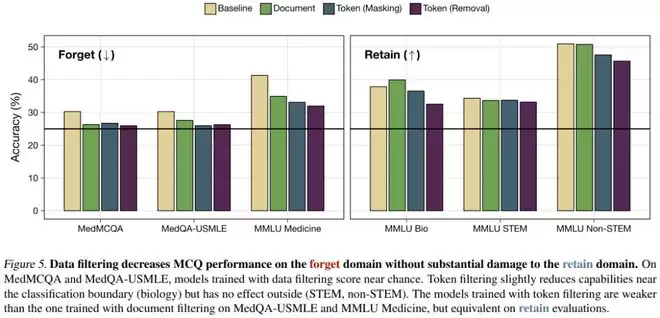
实验结果表明,Token 级过滤构成了对文档级过滤的帕累托改进。在同等程度地去除医学知识的前提下,Token 级过滤对生物学等通用知识的保留效果显著优于文档级过滤。这就像是用手术刀精准切除肿瘤,而不是直接截肢,最大限度地保留了健康的机体组织。
7000 倍算力阻滞:安全性的 Scaling Law
这项研究最令人震撼的发现在于「过滤」与「规模」的关系。
通常我们担心,随着模型越来越大,它们会变得越来越「聪明」,从而能够通过哪怕一丁点数据泄漏就学会危险知识。
但实验数据给出了相反的结论:Token 级过滤的效果随着模型规模的增加而显著增强。
研究团队引入了一个名为「损失匹配算力阻滞」(Loss-Matched Compute Slowdown)的指标,用来衡量攻击者需要多少额外的预训练算力,才能让经过过滤的模型在危险领域达到未过滤模型的水平。
数据很 nice:
对于较小的模型,过滤带来的阻滞效果相对有限。但随着模型规模扩大至 18 亿参数,Token 级过滤导致模型在遗忘领域(医学)的学习效率下降了7000倍。
这意味着,如果我们对未来的万亿参数级模型实施这种过滤,攻击者想要通过微调让模型重新掌握被切除的危险能力,将需要消耗天文数字般的算力。这实际上为模型构建了一道基于物理算力成本的天然屏障。
对抗性微调:比「机器遗忘」更坚固的盾牌
为了验证这种方法的鲁棒性,研究团队模拟了最坏的情况:攻击者拥有模型的权重,并试图通过在相关数据上进行微调来重新通过模型获取危险知识。
作为对比,他们选取了当前最先进的机器遗忘算法RMU(Representation Misalignment via Unlearning)作为基线。
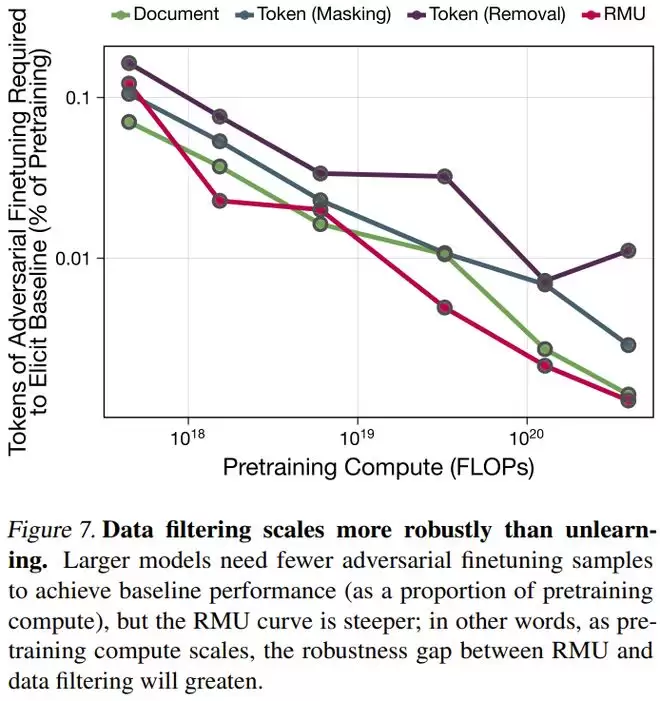
实验结果相当一边倒。RMU 虽然在初始测试中表现出很低的危险知识留存率,但极其脆弱。仅仅经过极少量的对抗性微调步骤,RMU 模型的防御就瞬间瓦解,危险能力迅速恢复。
相比之下,经过 Token 级过滤预训练的模型表现出了极强的韧性。随着模型规模的增加,这种韧性优势还在不断扩大。对于 18 亿参数的模型,攻击者想要恢复同等水平的能力,面对 Token 移除策略模型所需的微调数据量是面对 RMU 模型的 13 倍以上。
这揭示了一个深刻的道理:从未学过(预训练过滤)和学过再忘(机器遗忘)在神经网络的表征层面有着本质的区别。前者让模型在危险领域如同一张白纸,后者则只是暂时掩盖了留下的痕迹。
AI 的拒绝:无需知恶也能拒恶
在 AI 安全领域,一直存在一个悖论:为了让模型拒绝回答危险问题,模型是否必须先「知道」什么是危险的?
此前的研究(如关于毒性内容的过滤)往往发现,如果模型在预训练中完全没见过毒性内容,它就很难分辨并拒绝毒性指令。
然而,Rathi 和 Radford 的这项研究打破了这一固有认知。在针对医学知识的过滤实验中,他们发现经过 Token 级过滤的模型在接受「拒绝训练」时,表现反而优于未过滤的基线模型。
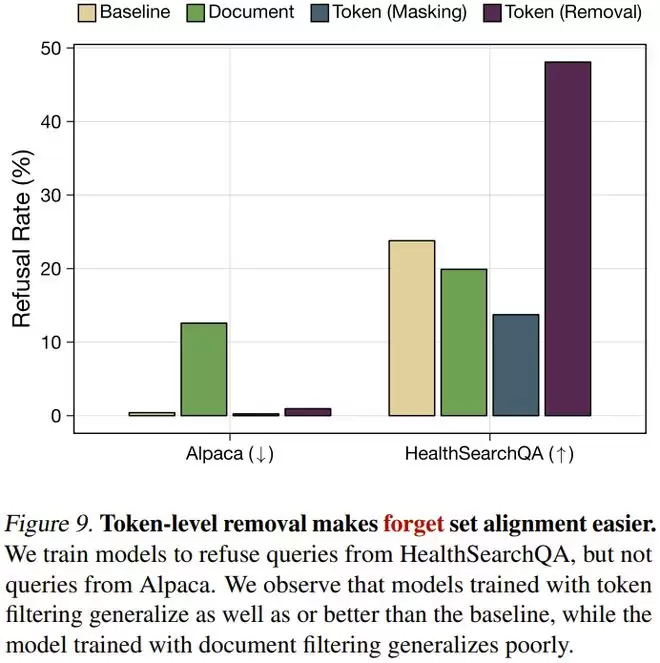
具体来说,当研究人员试图教会模型「拒绝回答医学问题」时:
Token 移除策略的模型在拒绝正确率上比基线模型高出 2 倍。文档级过滤的模型则表现糟糕,它往往会将这种拒绝行为错误地泛化,导致对正常的通用问题也进行拒绝。
研究者认为,这是因为 Token 级过滤创造了一个清晰的「已见 / 未见」边界。对于模型来说,拒绝任务从复杂的「判断内容是否有害」简化成了「判断这个概念我是否见过」。这种基于分布内 / 分布外的区分,比基于语义的判断更加稳健。
这为安全研究提供了一个极具价值的启示:我们不需要为了对齐而让模型先成为「绝命毒师」。通过制造知识真空,我们反而能训练出更听话、更安全的模型。
弱监督与自动标签:低成本实现的可能
实施 Token 级过滤的一个最大工程挑战在于:如何准确地给海量预训练数据打上「危险」或「安全」的标签?如果需要人工标注,成本将是不可接受的。
这也正是这篇论文在工程实现上的亮点。研究团队提出了一套基于「稀疏自编码器」(SAE)的弱监督流程。
特征提取: 他们利用 Gemma Scope 的 SAE 提取模型激活的潜在特征。自动标注: 使用 Claude Sonnet 4 等模型对这些特征进行解释,识别出与「医学」相关的特征,并据此生成一部分高质量的 Ground-truth 标签。训练分类器: 利用这些标签训练一个小型的、双向的语言模型(biLM)作为分类器。

有趣的是,研究发现我们并不需要一个完美的神级分类器。实验显示,通过「弱到强泛化」,即使是基于含有噪声标签训练出来的分类器,或者是仅基于小模型特征训练的分类器,在配合激进的过滤阈值后,依然能在更大规模的模型上实现出色的过滤效果。
这一发现极大地降低了该技术的落地门槛。开发者不需要拥有一支庞大的标注团队,仅凭现有的开源工具和小模型,就能构建出有效的预训练过滤器。
结语:构建纵深防御体系
Rathi 和 Radford 的这项工作并非宣称可以替代 RLHF 或后续的安全措施,而是倡导一种「纵深防御」(Defense-in-depth)的策略。
在预训练阶段进行 Token 级过滤,相当于为模型打下了坚实的安全地基;在此基础上进行的对齐训练,将不再是空中楼阁。这种方法特别适用于那些通过 API 开放模型权重的场景 —— 即便攻击者拿到了模型,他们面对的也是一个在物理层面「缺失」了危险能力的残缺大脑。
随着 AI 模型向着更大规模演进,Token 级数据过滤所展现出的优越 Scaling Law,或许将成为未来 AGI 安全架构中不可或缺的一块拼图。
对于像 OpenAI、Anthropic 这样的前沿实验室而言,这项研究无疑指明了一条在 Scaling 的同时也 Scale Safety 的可行路径。