清华破解强化学习安全悖论,14项测试基准实现全SOTA

免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
新智元报道
编辑:LRST
【新智元导读】清华大学李升波教授团队提出RACS算法,通过引入「探险者」策略主动探索违规边界,破解安全强化学习的「安全性悖论」。该方法在不增加采样成本的前提下,显著提升违规样本质量与系统安全认知,实现安全与性能的双赢,刷新多项基准的SOTA成绩。
随着强化学习(RL)在虚拟世界的统治级表现,将其迁移至自动驾驶、机器人控制等真实物理系统已成为行业共识。然而,物理世界的高风险特性画出了一道不可逾越的红线——「零约束违反」。
为了守住这道红线,学界提出了多种方案:OpenAI结合拉格朗日乘子法动态权衡安全与性能,UC Berkeley提出的CPO算法利用信赖域将策略限制在可行空间内。
然而,现有方法始终面临一个核心痛点:策略难以做到严格的「零违反」。大多数算法只能将违规控制在极低水平,一旦试图追求绝对的零违规,就会遭遇巨大阻力。
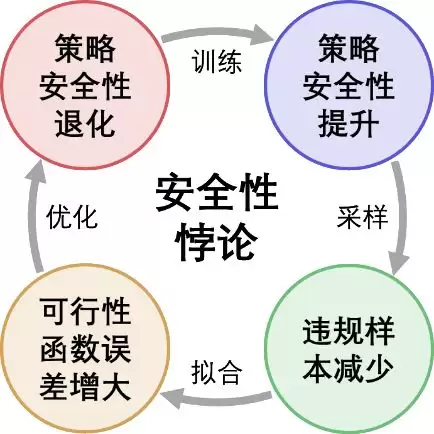
清华大学李升波教授课题组于安全强化学习领域获得突破性进展,首次在理论层面揭示并证明了安全强化学习(Safe RL)中的一个反直觉现象——「安全性悖论」(Safety Paradox):策略越追求安全,反而可能越不安全。

论文链接:https://openreview.net/forum?id=BHSSV1nHvU
代码仓库:https://github.com/yangyujie-jack/Feasible-Dual-Policy-Iteration
在安全强化学习中,智能体通常依赖交互数据学习一个可行性函数(Feasibility Function),以此判断当前状态是否长期安全,从而规避危险区域。
然而,研究通过严格的理论证明揭示了一个严峻事实:
随着策略变得越来越安全,其产生的违规样本会变得极度稀疏。这直接导致可行性函数的估计误差急剧增大,进而使指导策略优化的约束函数出现偏差,最终导致策略安全性崩塌。
这就像一个从未见过悬崖的人,在行走时即便再小心翼翼,也会因为缺乏对「悬崖边缘」的确切认知,而无法精准判断危险界限究竟在哪里。越是刻意追求安全,对危险边界的认知就越模糊,最终反而导致安全防线失效。 这就是所谓的「安全性悖论」——策略陷入了一个自我挫败的死循环。
针对这一困境,团队提出了Region-wise Actor-Critic-Scenery(RACS)算法,通过引入专门收集违规样本的「探险者」策略,成功打破悖论,在权威基准Safety-Gymnasium上刷新了SOTA成绩,该工作发表于人工智能顶会ICLR 2026。
破局之道RACS算法
既然「不敢越雷池一步」会导致认知盲区,那么破解之道便是主动探险、直面危险。
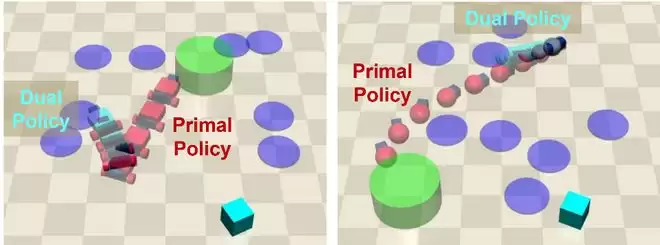
研究团队提出了Region-wise Actor-Critic-Scenery(RACS)算法,创造性地引入了双策略架构:
(1)原始策略(Primal Policy):扮演「守规矩的执行者」。它负责在满足安全约束的前提下,尽可能最大化任务奖励。
(2)对偶策略(Dual Policy):扮演「无畏的探险者」。它的目标与前者相反,旨在策略性地最大化约束违反,主动触探原始策略不敢涉足的危险边界。
通过这种「左右互搏」的机制,RACS在不增加总采样成本的前提下,显著提升了关键违规样本的比例,从而让系统对「安全边界」有了清晰、精准的认知。
为了解决双策略数据混合带来的分布偏移(Distributional Shift)问题,RACS采用了重要性采样(Importance Sampling)技术进行数学修正,并约束对偶策略与原始策略间的KL散度,确保训练过程的平稳收敛。
实验结果:刷新SOTA
研究团队在安全强化学习权威基准Safety-Gymnasium上进行了广泛验证。结果表明,RACS在14项任务中的综合性能达到了State-of-the-art(SOTA)水平:
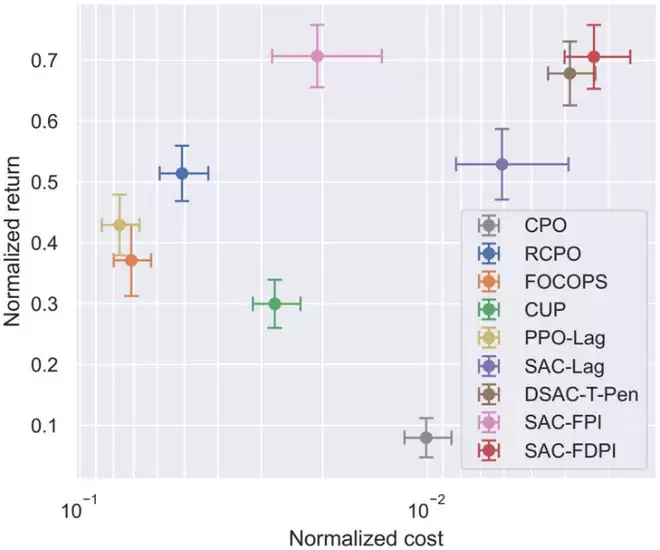
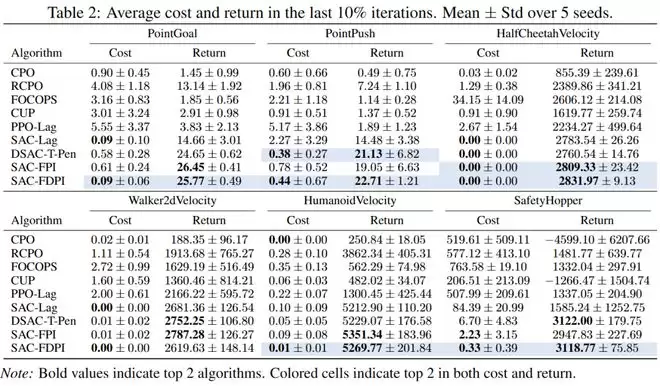
(1)安全性显著提升:RACS实现了最低的平均约束违反次数(Cost),显著优于现有的拉格朗日乘子法或信赖域方法。特别是在HalfCheetahVelocity、Walker2dVelocity等任务中,实现了严格的零约束违反。
(2)控制性能无退化:在保证安全性的同时,RACS的平均累积回报(Return)依然位居榜首,实现了安全与性能的双赢。在高维的HumanoidVelocity、复杂的PointPush(推箱子导航避障)等多项高难度任务中,安全指标与任务性能均名列前茅。
为探究性能提升的根本原因,研究团队统计了增加对偶策略后的关键指标变化:
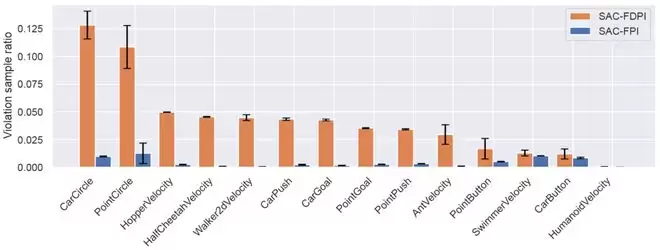
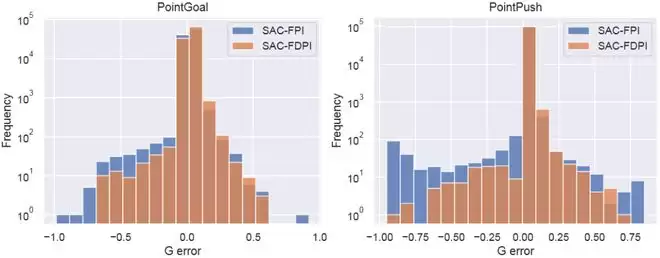
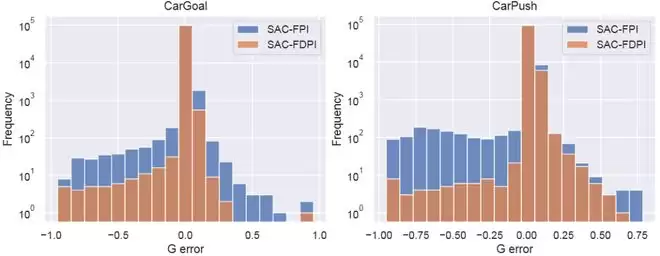
(1)违规样本显著增加:在所有 14 项任务中,对偶策略成功采集了大量高价值的违规样本,大部分任务中的样本量提升了一个数量级。
(2)估计误差大幅降低:统计显示,可行性函数的拟合误差显著减小,尤其是「低估风险」(误差小于零)的频率大幅降低。这意味着系统不再将危险状态误判为安全,从而从根本上提升了策略的安全性。
总结与展望
该研究从理论上揭示了强化学习中的「安全性悖论」,阐明了违规样本稀疏性与可行性函数估计误差之间的内在因果。
RACS算法通过对偶策略的「对抗式」探索打破了「安全性悖论」,证明了一个深刻的道理:为了真正的安全,必须充分地了解危险。
该研究为自动驾驶、机器人等高风险场景下的强化学习落地提供了坚实的理论基础与有效的解决方案。
参考资料:
https://openreview.net/forum?id=BHSSV1nHvU
相关攻略

智通财经APP获悉,因谷歌(GOOGL US)研究人员宣传一项新的压缩技术引发市场对需求的担忧,计算机内存及存储产品股价大幅下挫,但这一冲击可能只是短期扰动,而非生存威胁。韩国交易所市场上,AI应用

新智元报道编辑:LRST【新智元导读】清华大学李升波教授团队提出RACS算法,通过引入「探险者」策略主动探索违规边界,破解安全强化学习的「安全性悖论」。该方法在不增加采样成本的前提下,显著提升违规样

【编者按】在人工智能技术浪潮席卷全球的今天,“超级智能”(Superintelligence)已从科幻叙事与理论推想,日益演变为一个严肃的学术议题与未来现实关切。这一概念自哲学与计算机科学领域萌芽,
热门专题







热门推荐

需求人群 无论是需要打造品牌形象的企业,筹划宏大叙事的纪录片团队,还是灵感迸发的个人创作者,都能在这里找到得心应手的工具。它的适用面,覆盖了从专业到日常的广泛创作场景。 使用场景 想制作一部充满科技未来感、带有粒子地球特效的企业宣传片?用它。需要快速为夏装童装上新打造一个可爱又吸引眼球的优惠视频模板

需求人群 不论是企业团队还是个人创作者,只要有多媒体内容创作的需求,都可能成为它的用户。覆盖面其实相当广。 使用场景 对企业来说,最典型的莫过于制作口播视频。传统方式费时费力,现在借助数字人技术,能大幅压缩制作周期和成本,效率的提升是实实在在的。 个人用户则会偏爱它的在线图片设计功能。不需要掌握专业

需求人群 无论是想快速制作动画短视频的创作者,还是运营自媒体需要生成手绘、文字、图文或相册短视频的朋友,这套工具都能满足你的需求。 使用场景 它的应用场景非常明确:帮你高效解决企业宣传短视频的制作难题,轻松搞定微课视频,同时也是征战抖音、快手等平台的短视频制作利器。 产品特色 那么,它具体能做什么?

需求人群 如果你正在使用在线约会软件,或者经常需要通过文字进行社交互动,希望更高效、更得当地开启和推进对话,那么这类工具正是为你设计的。 使用场景 想象一下,在Tinder上匹配到心仪对象,却为第一句话绞尽脑汁。这时,一个智能工具能帮你生成独特的破冰语,轻松给人留下深刻的第一印象。 不止于此,在后续

需求人群 说到给图片换背景,那可是个磨人的活儿。自己动手抠图,费时费力不说,边缘还总处理不干净。好在现在有了 BgSub 这类工具,但凡工作中需要频繁处理图像、进行视觉设计,或者只是想给社交媒体发张精美图片的朋友,它都能帮你把大量时间省下来。效率的提升,是实实在在的。 产品特色 那么,这款工具到底强