henry 发自 凹非寺
量子位 | 公众号 QbitAI
最强的大模型,已经把scaling卷到了一个新维度:百万级上下文
几天前,Claude Opus 4.6发布,让人第一次真切感受到了百万上下文的涌现能力——
单次吃进50万字中文内容、实现跨文档法律分析、多轮Agent规划……
此情此景,用户火速用脚投票,华尔街更是直接给出K线回应。
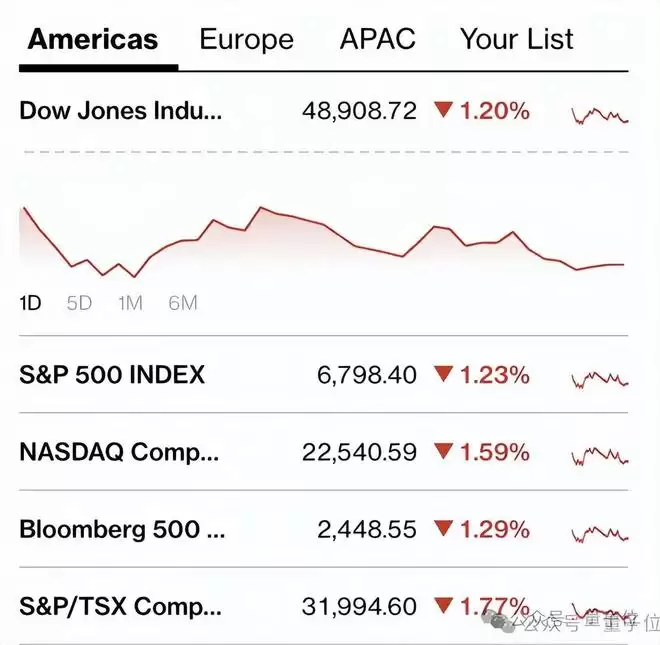
而这股scaling的风,也很快吹到了端侧。
刚刚,面壁智能带着首次大规模训练的稀疏与线性混合注意力模型,小年交卷——
这套新注意力架构,不仅解决了传统Transformer的计算冗余,还第一次在性能无损的前提下,让9B端侧模型能够在5090显卡上处理百万长文本
与此同时,基于SALA注意力架构的模型MiniCPM-SALA也将一并开源。
除此之外,面壁还以OpenBMB社区名义,联合SGLang与NVIDIA发起2026稀疏算子加速大奖赛(SOAR),将这套scaling能力直接交到开发者手中,推动端侧Agent部署的性能突破。
Linear-Sparse混合注意力架构
太长不看,咱直接说重点——
面壁这次全新的线性与稀疏注意力混合架构SALA(Sparse Attention-Linear Attention,SALA),究竟是怎么个混合法呢?
简单来说,这套架构将75%线性注意力(Lightning Attention)25%稀疏注意力(InfLLM v2)结合,并通过混合位置编码HyPE(Hybrid Position Encoding)实现两者的高效协同与超强的长度外推。
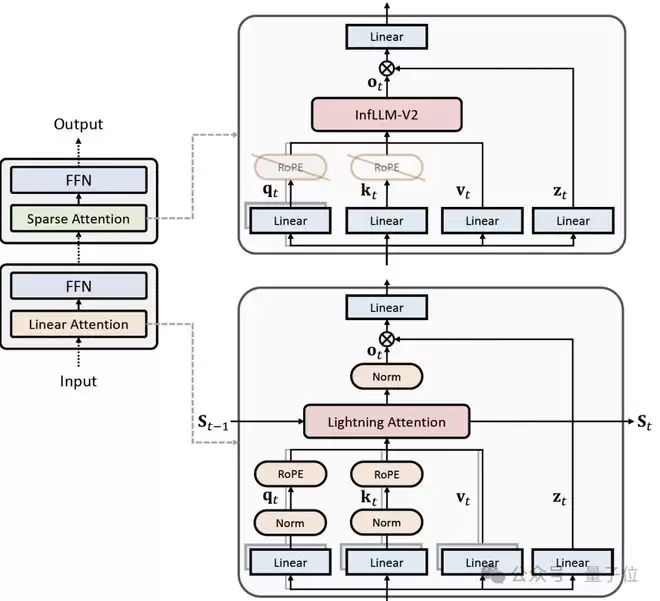
线性注意力模块,Linear-Sparse选用Lightning Attention作为核心算子,负责快速、稳定地建模长文本的全局信息
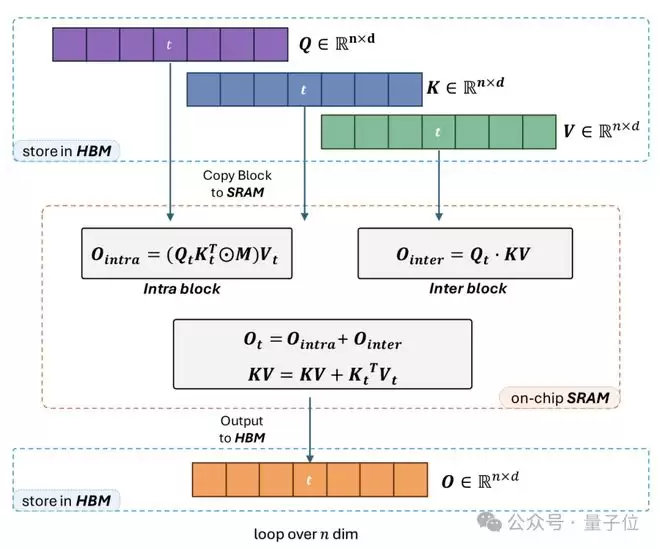
Lightning Attention的计算方式与传统全注意力接近,方便现有全注意力模型直接迁移到混合架构,无需从零开始预训练。
同时,借助QK-normalization输出门控机制,使线性层在百万级上下文训练下保持数值稳定,避免梯度爆炸或下溢。
稀疏注意力模块,Linear-Sparse采用InfLLMv2来精准捕捉长序列中的关键局部信息

InfLLM v2可按需选择关键KV,让每个Query只计算必要部分,从而大幅提高长文本处理效率。
值得一提的是,InfLLM v2还能在长文本中自动启用稀疏模式,在标准长度下回退为稠密计算,实现长短文本的无缝切换。
最后,混合位置编码HyPE(Hybrid Position Encoding)的引入,则保证了线性和稀疏两种注意力机制的充分协同。
一方面,线性层保留RoPE以维持与原全注意力模型在参数分布和特征空间上的一致性,保证中短文本性能稳健。
另一方面,稀疏层采用NoPE(无位置编码),让KV-Cache与位置信息解耦,规避长距离衰减问题,使模型在百万长度上下文中仍能高效检索极远信息。
训练上,MiniCPM-SALA采用Transformer-to-Hybrid低成本构建方法(HALO)
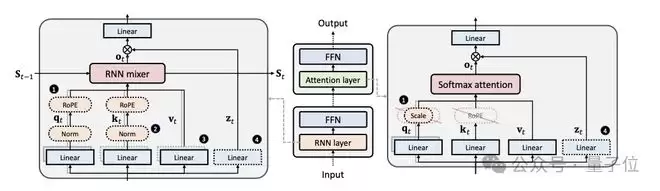
具体而言,模型通过HALO方法将75%的全注意力层转换为线性注意力层,整个过程包括参数转换、隐状态对齐、层选择以及知识蒸馏四个步骤。
最终,这套Linear-Sparse设计让MiniCPM-SALA在端侧处理超长文本时,不仅显存占用极低、计算高效,而且语义精度依然保持领先水平。
为什么百万上下文,必须是“混合注意力”?
要回答这个问题,得先回到传统的Full Attention
在经典Transformer里,每生成一个新token,都要和之前所有token做两两计算,其计算复杂度是典型的O(N²)。
这意味着,把上下文从1万拉到100万,计算量不是涨100倍,而是直接飙升1万倍。与此同时,为了让模型“记住”所有历史信息,还得把KV对全攒在显存里。
随着上下文长度增加,KV Cache迅速膨胀,很快就会爆显存。
由此可见,想解决长上下文问题,注意力机制是核心瓶颈
过去几年,业界围绕这一瓶颈探索了多条路线,本质上都是在精度、效率与可部署性之间寻找平衡点
第一类是线性注意力,通常为线性和全注意力结合的混合设计。
它用记忆状态替代传统两两打分,能将计算复杂度从O(N²)降到O(N)。
优点是可以吃下百万级上下文,但底层采用有损压缩,序列越长,早期信息越容易被稀释,导致上下文遗忘和模型能力下降。
第二类是原生稀疏注意力
只计算关键位置,精度接近全注意力,但为了支持长程历史回顾,仍需全量保存KV Cache,导致端侧部署成本高。
第三类是放弃显式注意力的状态空间模型,如Mamba。
这类方法推理效率高、几乎不需要KV Cache,但在精确指令遵循和长距离精确检索上,仍不够稳定。
综上,我们不难看出注意力机制改动是长上下文scaling的主战场
但真正能同时兼顾百万级上下文能力、推理效率和端侧可落地性的方案,仍然稀缺。
这也是为什么面壁提出Linear-Sparse混合注意力架构的出发点。
用线性机制承担大规模上下文的承载,用稀疏机制补足关键位置的精确建模能力。
在这一架构下,模型不再需要对所有token做完整的两两计算,也不必无条件保存全量KV Cache。
新的混合注意力架构可以在显著降低推理开销和显存占用的同时,避免纯线性注意力在长程信息召回上的精度损失,以及稀疏注意力在端侧设备要求上的局限。
基于这一设计,面壁还开源了MiniCPM-SALA,用来验证该架构在真实长上下文场景下的潜力。
在效果层面,得益于显著更低的显存占用和更高的推理效率,MiniCPM-SALA首次在5090这样的消费级显卡上,将1M上下文完整跑通,为长上下文从云端走向端侧提供了一条现实可行的路径。
与此同时,在不依赖投机推理等额外加速算法的前提下,相比同尺寸开源模型,MiniCPM-SALA在256K序列上实现了2倍以上的速度提升。
当序列长度进一步提升至512K甚至1M时,部分同尺寸模型已经遭遇显存瓶颈,而MiniCPM-SALA依然能够稳定运行。
(详细测评结果可参考MiniCPM-SALA的GitHub或Hugging Face README)
从这些结果来看,未来的大模型,并不一定需要Full Attention才能具备完整能力。
当上下文成为第一性资源时,像Linear-Sparse混合注意力这样的新型注意力设计,正在成为影响模型能否真正落地的重要变量。
2026稀疏算子加速大奖赛
如果说MiniCPM-SALA让Linear-Sparse混合架构的能力有了实证,那么今年的SOAR(稀疏算子加速大奖赛)就是让这套技术“落地跑起来”的舞台。
这场比赛由面壁智能、OpenBMB联合SGLang社区和NVIDIA共同发起。
旨在通过全球极客的深度协作,共同探索MiniCPM-SALA这一全球首创“稀疏+线性”混合架构模型在1M长文本推理上的性能极限。
具体来说,大赛聚焦于稀疏算子融合与编译优化等底层技术挑战,尝试在消费级GPU上实现百万Token推理且KV Cache<6GB的极致效率。
比赛时间从2月11日持续到5月29日,设有总奖池超过70万人民币的奖励。
参赛者不仅能测试混合架构在真实硬件上的极限,还能探索端侧高效长文本处理的新方法。
比赛链接:https://soar.openbmb.cn/

面壁为什么执着于用SALA重构长上下文?
这并不是为了“卷长上下文指标”。
面壁的一大目标是从Densing Law(密度法则)的第一性原理出发,将通用能力强的模型落到智能终端如手机、汽车、机器人等上,而SALA架构的创新是通往罗马的关键:
正是基于对注意力机制的创新,MiniCPM-SALA模型才能足够高效、显存占用足够低,面壁才能首次在5090这样的消费级GPU 上,把一兆级长文本端侧推理真正跑通。
这一步一旦成立,长上下文就不再只是云端模型的特权,而成为端侧智能可以依赖的基础能力。
如果把面壁今年的动作放在一起看,其实不难理解其在端侧智能上的整体思路:
从模型底层直通端侧生态,核心就是上下文
无论是模型架构的迭代,还是长文本的竞技,本质上都是一次针对端侧落地的“两步走”战略。
而这,并非偶然。
放眼整个行业,Agent的核心瓶颈已从单纯的参数量转向上下文能力——
从模型层的Claude Opus 4.6,到应用层的Claude Cowork、Clawdbot(现OpenClaw),再到评估层的CL-Bench,行业共识已经非常明确:
能否一次吸收、理解并持续利用大量上下文,是决定Agent可用性的关键。
与此同时,基于注意力机制优化上下文处理,也已成为学界到产业公认的主战场。
去年NeurIPS 2025最佳论文给到门控注意力;产业侧,Kimi的KDA、DeepSeek的NSA、MiniMax的Lightning相继推出新方案——
几乎所有核心玩家,都在attention这条线上持续加码。
因为这不是一个“工程调优”问题,而是架构级问题。
只有真正具备AGI野心和技术纵深的公司,才有能力从底层架构一路改到上层算法。
也只有真正想把模型能力推到边界的团队,才有魄力去挑战已经被奉为主流、但显然仍有优化空间的Transformer传统范式。
而面壁选择这条路,更是因为其与端侧部署的目标高度契合:
首先,端侧Agent要处理的包括通讯录、位置信息、聊天记录。
出于隐私保护,这些数据无法走向云端。只有让模型本身具备超长上下文能力,个人助理才能在本地真正“懂你”。
其次,通用榜单已进入红海,端侧开发者关心的问题也已从特定的benchmark,转向真实世界环境的上下文应用。
这正如DeepSeek研究员苟志斌所言:
预训练能scaling,RL也能scaling,上下文也能scaling,模型仍在继续scaling。

换句话说,参数规模已经不再是唯一指标,真正的竞争力在于模型/Agent在复杂上下文中持续推理和行动的能力,这将直接决定模型从demo走向仓库级代码助手、行业知识库Agent。
最后也是最本质的,不解决长文本推理部署成本,端侧智能也就无法真正落地。
所以面壁不只做模型,更在做生态:从开源MiniCPM-SALA,到举办端侧长文本比赛降低部署成本,再到深耕开发者社区,面壁正在拼出一条剑指“百万上下文时代个人智能体”的主线。
比赛链接:
https://soar.openbmb.cn/
技术报告:
https://github.com/OpenBMB/MiniCPM/blob/main/docs/MiniCPM SALA.pdf
Github:
https://github.com/openbmb/minicpm
HuggingFace:
https://huggingface.co/openbmb/MiniCPM-SALA
ModelScope:
https://www.modelscope.cn/models/OpenBMB/MiniCPM-SALA




