
新智元报道
编辑:KingHZ Aeneas
【新智元导读】思考token在精不在多。Yuan 3.0 Flash用RAPO+RIRM双杀过度思考,推理token砍75%,网友们惊呼:这就是下一代AI模型的发展方向!
硅谷的算力战争,已经不是「拼GPU」,而是「抢电网」。
OpenAI万亿豪赌Scaling,瞄准10GW级超级集群。
在孟菲斯,马斯克竖起xAI的Colossus,55.5万张GPU与2GW电力轰鸣待命。
还不止地面。马斯克已经把目光看向太空:下一座「算力堡垒」,仿佛就在地球近地轨道的黑暗里发光。

奥特曼在赌,马斯克在赌,整个硅谷都在赌:堆起最高的「算力山」,就能先摸到AGI的门把手。
可就在这场万亿级狂飙里,Anthropic的一个更刺耳的结论浮出水面——
模型越大,算力越多,不一定越聪明。更可能的是:浪费更大、思维链更乱、幻觉更猛。
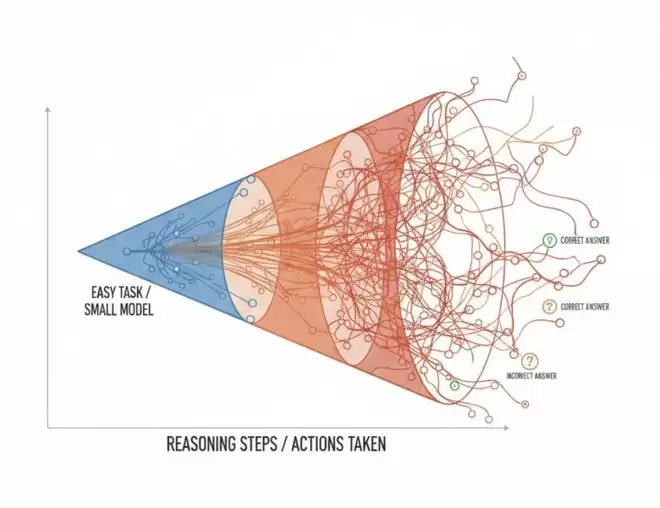
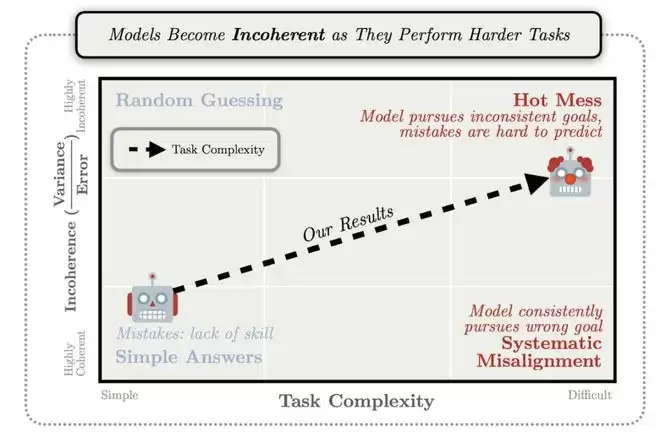
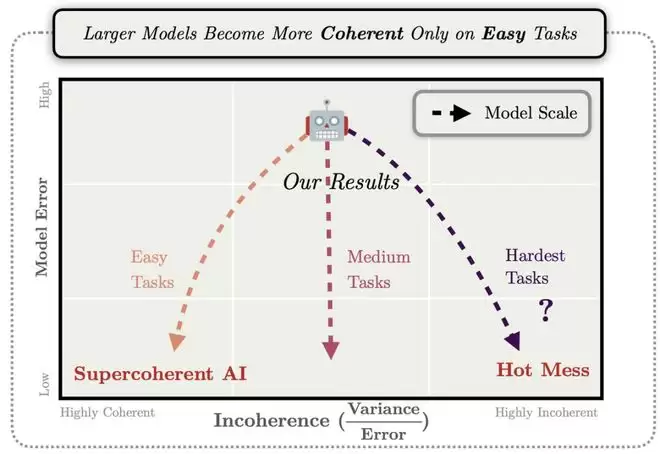
左右滑动查看
真正决定胜负的,可能不是更多GPU,而是能让模型在正确答案前及时刹车的算法。
而就在这个节点,Yuan 3.0 Flash悄然登场。
它出自YuanLab.ai团队之手——没有喧嚣的发布,没有张扬的宣告,却也吸引了全球开发者的注意。26年伊始,YuanLab.ai团队交出了它的阶段性的成果,向行业展示了自己的节奏。
可以说,Yuan 3.0 Flash不是又一个参数爆炸的巨兽,而是一场针对「想太多」的精准手术——以更高效的机制,实现更敏捷的思考。
40B总参数的MoE(Mixture-of-Experts)架构,仅激活约3.7B参数,却在多模态任务上展现出媲美甚至超越数百亿参数模型的表现。
更关键的是,它让模型学会「适可而止」,从训练阶段就教会它:什么时候该停手。

链接:https://arxiv.org/pdf/2601.01718
开源:https://github.com/Yuan-lab-LLM/Yuan3.0
因此,Yuan 3.0 Flash一经发布,就在全球开发者中引起了巨大轰动。
有人说,这是高效多模态AI迈出的一大步:一个400亿模型仅仅激活了37亿参数,这就是下一代AI模型的发展方向!

没想到,开源模型竟然能有这种级别的控制力,这种AI,是真的可以应用于生产环境的。
打破业内魔咒
想太多,就更好吗?
推理模型的兴盛,引发了全行业对「长思维链」的追逐。
然而,企业AI落地时,却存在着这样一个「TOKEN成本悖论」——
想要高智能,就必须承担成倍增长的Token消耗和推理延迟;
想要控制成本,往往只能牺牲模型能力。
要知道,对企业而言,每一个无效消耗的Token,都是真金白银的流失!
真正的成本黑洞,不在「求解」,而在「答对之后」:很多推理模型一旦摸到正确答案,就开始反复确认、来回推翻、没有新证据也要继续「再想想」。
事实上,在数学与科学任务中,超过70%的token消耗发生在正确答案之后,却仍在进行无效反复验证的阶段。
举个例子,你问了AI一个数学题,它会先给出正确解,然后又开始「但是……或许……再检查一遍」,最终输出比答案本身长三倍的文字。

答案早已浮现,却被淹没在无休止的自我对话中。
这不是「幻觉」,是当下大模型的普遍顽疾:过度反思(overthinking)。
为了解决这一矛盾,Yuan 3.0 Flash正式登场了!团队的目标是——「用更少算力,实现更高的智能」。
四两拨千斤
更少算力,但更高智能
Yuan 3.0 Flash,在MoE架构的基础上,实现了RIRM(反思抑制奖励机制)和RAPO(反思感知自适应策略优化)两项算法创新,这样就从根本上修正了模型的「过度思考」。
由此,模型实现了以下突破:
· 精准定位:准确识别首次得出正确答案的关键节点
· 抑制冗余:有效抑制后续冗余推理行为
· 双重提升:在提升精度的同时,将推理token数量降低约75%
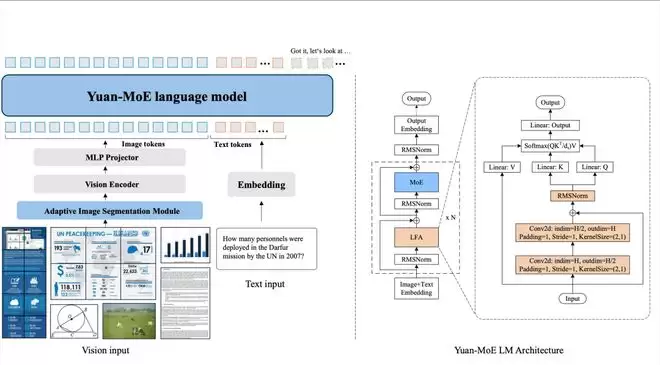
首先,来看它在架构上的优雅革命。
传统稠密模型像一支全员出动的军队,每一次推理都调动所有神经元。
Yuan 3.0 Flash则更像一支特种部队:MoE机制只唤醒最合适的「专家」应对当前任务。
视觉编码器处理高分辨率图像,通过自适应分割机制将图片拆分成高效token,避免显存爆炸;语言主干网络采用Local Filtered Attention(LFA),进一步降低计算开销。
结果很出彩——
上下文长度轻松达到128K,在「needle-in-a-haystack」(大海捞针)测试中实现100%准确召回。
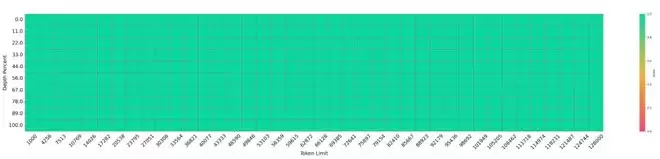
就是说,它能从海量文档中精准定位关键信息,而不会因为长度而迷失。
想象一下,你的企业需要分析一份数百页的财务报告,夹杂着复杂嵌套表格和图表。
过去,模型或许卡顿、幻觉频出,或者token消耗到天价。
而Yuan 3.0 Flash像一位专注的审计师,多模态输入(文本+图像+表格+文档)无缝融合:
RAG(检索增强生成)准确率达64.47%,
Docmatix多模态检索65.10%,
MMTab表格理解58.30%,
SummEval摘要生成59.30%。
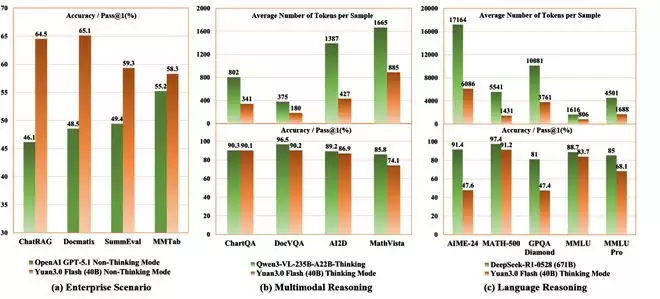
在企业场景,Yuan 3.0 Flash远超GPT-5.1的46.10%,直接瞄准了LLM的痛点。
RIRM:拒绝无效内耗
真正让Yuan 3.0 Flash脱颖而出的,就是对「过度反思」的致命一击。
在MATH-500和AIME等数学基准上,传统推理模型的token分布像一座冰山:
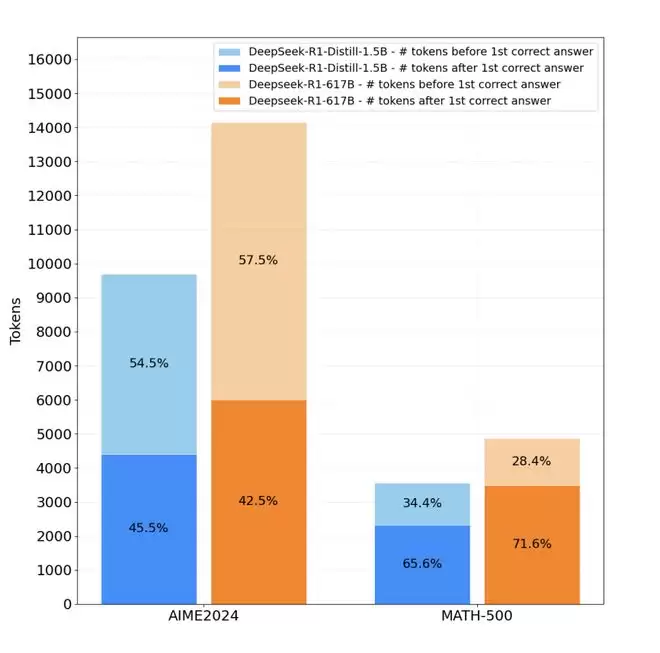
浅色部分是问题求解,深色巨大区域是后答案反思
比如,在MATH-500上,「后答案反思」占比高达71.6%,整体token在3362上居高不下。
为了显著降低这一无效反思的占比,团队提出了一种创新机制——反思抑制奖励机制(RIRM)。
RIRM的原理简单却深刻:在强化学习中,它识别模型首次输出正确答案的「节点」,然后对后续缺乏新证据的重复验证、自我推翻施以负奖励。
模型不再被鼓励「想得越久越好」,而是学会辨别「足够好」的边界。
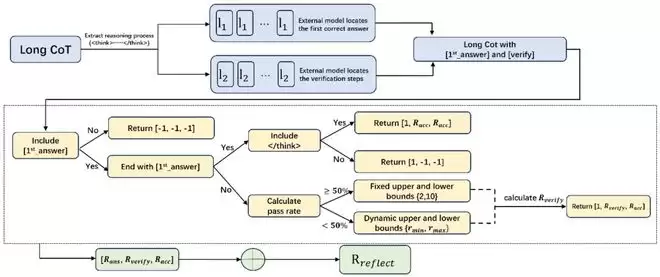
RIRM工作流程示意
从首次正确答案识别到反思阶段奖励抑制的完整链路
也就是说,在强化学习中,RIRM首次教导了模型识别「何时思考已足够」。它会奖励模型在首次得出正确答案后停止无效反思,而非鼓励无止境的推演。
为此,团队引入了三个维度的奖励:首次正确答案、最终正确性,以及反思步骤数量是否落在合理区间内。
果然,Yuan 3.0Flash引入RIRM后,上面这座冰山被腰斩:反思阶段token占比骤降至28.4%,总token压缩至1777左右,减少约47%,而准确率不降反升(MATH-500从83.20%提升至89.47%)。
这就说明被压缩的并不是有效推理,而是答案已经确定之后的反复自检、复述与格式化解释等低价值token。
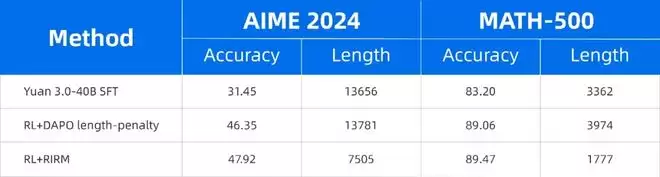
不仅如此,该模型在数学、科学等领域也表现出强大的推理能力,直接把无效反思的Token消耗最高削减至75%,即可达到前沿模型的精度水平!
这样,就能让算力聚焦于真正有价值的推理步骤。可以说,RIRM的作用并非「压长度」,而是让模型学会在正确节点停止思考。
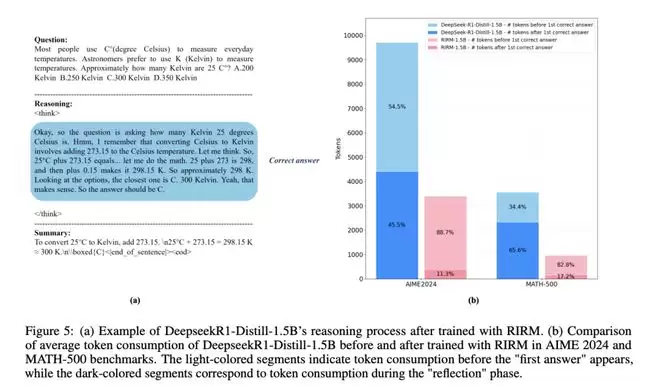
RIRM训练前后Token消耗对比
反思阶段(深色部分)显著缩减,而首次解题阶段基本保持不变
RAPO:高效训练引擎
然而,仅靠对推理行为的抑制,并不足以支撑一个稳定、高效的企业级模型训练。
由此,团队引入了RAPO(反思感知自适应策略优化),这并非一次局部技巧的优化,而是对强化学习训练框架的一次系统性改进。
它兼顾了训练效率、训练稳定性及推理效率,使模型能在多任务、异构场景中形成更具实用价值的策略。
具体来说,它从训练框架层面实现保驾护航:
自适应动态采样(Adaptive Dynamic Sampling,ADS):动态过滤掉低信息量的重复样本,训练效率提升52.91%
80/20高熵token更新规则:只更新不确定性最高的前20%的token梯度,聚焦真正需要优化的部分
优化双剪裁:同时对策略梯度和值函数梯度进行双重裁剪,防止MoE架构常见的梯度爆炸
多任务交替训练+KL散度正则,让大型MoE模型也能稳定收敛
让整个RL过程效率提升52.91%,即使在大型MoE模型上也保持稳定。
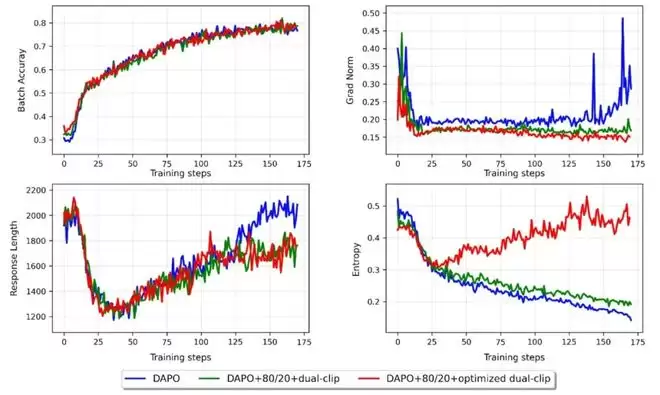
这不是强制缩短输出,而是重塑模型对「好推理」的认知: 从「长度即真理」,转向「时机即智慧」。
更重要的是,RAPO与RIRM是协同设计的。
RAPO决定模型「如何学习」,而 RIRM明确模型「学到什么程度该停」。
当然,任何创新都有其张力。
RIRM在抑制冗余的同时,可能在极度不确定、需要多轮探索的任务中略微限制有益反思——这需要在实际部署中持续观察与平衡。
AI下半场,YuanLab.ai团队这样想
Yuan 3.0 Flash指向一个清晰的结论:当模型具备基础推理能力后,其进化的关键已非「延长思考」,而在于 「优化思考的质量与效率」。
它不仅为企业提供一种「更少算力、更高智能」的选择,更重要的是对「长思维链」竞赛的理性补充。
背后团队YuanLab.ai深深理解深度推理的价值,但也知道隐藏的算力浪费风险。
因此,Yuan 3.0 Flash提供了追求「有效思考」的平衡方案,推动行业关注智能的实用性与经济性。

Yuan 3.0 Flash被网友盛赞:这不是一个demo, 而是一个真正为生产构建的模型!
当模型能够在获得正确答案时主动停止推理,本质上意味着它开始进行一种隐式的成本—收益分析。从此,token成为推理过程中可被模型内部感知和调节的计算资源。
这就标志着推理目标的一次转变:从单纯模仿人类冗长、外显的思维过程,转向更适合机器的、以最小token预算达成正确性的效用导向智能形态。
为什么这种更高效的智能,是出自YuanLab.ai团队之手?
实际上,这个成果可以看作YuanLab.ai团队在此领域多年经验的厚积薄发。作为在行业内深耕多年的大模型探索者,团队的发展足迹本身已成为中国大模型演进历程中一个真实而生动的缩影。
2024年,当业界对大模型的认知尚处朦胧时,YuanLab.ai团队便已勇闯无人区,发布了2457亿参数的源1.0大模型,这是对GPT-3架构的成功验证。
发布之际,团队开源了平台、代码以及珍贵的中文数据集,滋养了国内早期大模型成长土壤。
随着ChatGPT的横空出世,YuanLab.ai团队立足自身技术积累与市场需求,于同期成功推出自主研发的「源2.0」大模型。
2024年5月,团队发布了采用创新MoE架构的源2.0-M32,以仅2.25万亿Tokens的训练量,实现了出色的性能。
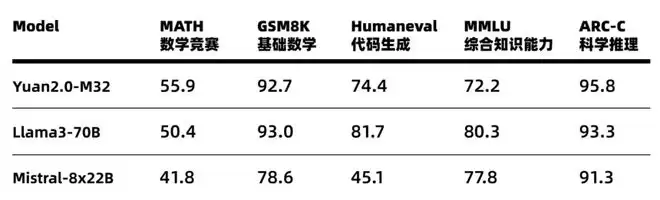
站在「源2.0-M32」的肩膀上,YuanLab.ai团队已向着下一个里程碑进发——「源3.0」 ,剑指多模态、更少算力、更高智能的AGI路径。在此过程中,也有了团队近期交出的阶段性成果——Yuan 3.0 Flash。
AI下半场,走向哪里
回望过去,我们或许会发现,AI的下半场真的来了。
上半场,大家追求的是「大」:更大的参数、更多的显卡、更高的智能。那是AI的青春期,迅速成长。
下半场,我们开始追求「准」:更精炼的逻辑、更克制的表达、更高效的决策。这是AI成年礼的开始。
当我们不再迷信「越大越强」,而转向「更精炼、更适配」,AI才真正从实验室走向生产,从昂贵的玩具变成可持续的工具。
此时,我们触及了本质:AI智能的边界,正在从「深度」转向「时机」。
真正的聪明,往往不是想得最多,而是知道何时果断收手。
人类智慧最珍贵的部分,从来不是喋喋不休的长篇大论,而是由于洞察本质而带来的适时沉默。
所以,当你下一次面对AI冗长输出时,不妨问自己:它是在推理,还是在演推理?
在AGI星辰大海里,我们或许不再需要追逐参数巨兽,而是学会点亮一盏更精准、更节制的灯塔。
大厂需要学会的,是参与一场「适可而止」的革命。
参考资料:
https://arxiv.org/pdf/2601.01718
https://github.com/Yuan-lab-LLM/Yuan3.0





