NVIDIA CUDA护城河崩塌?AI算力新框架效能暴增82%

免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
新智元报道
编辑:桃子 好困
【新智元导读】 在 Claude Code 30 分钟迁移 CUDA 引发热议的背后,众智 FlagOS 社区已经给出了一条更系统的答案:通过 KernelGen 与统一编译器 FlagTree,让算子在多种 AI 芯片上实现自动生成、验证与优化,真正降低跨芯片软件迁移成本。
围绕「CUDA 护城河是否松动」的讨论,本质指向一个更现实的问题:
算子能否在不同芯片上被自动生成、正确运行,并具备可用性能?
算子生成综述(https://arxiv.org/abs/2601.15727)
算子自动生成,已经跑在多芯片上了
对此,众智 FlagOS 社区在2026年1月初推出了升级版KernelGen——一个支持多种AI芯片的高性能 Triton 算子生成自动化工具,并在真实多芯片环境下完成了系统性评测。
从实际数据来看,KernelGen 已不再停留在概念或 Demo 阶段:
生成可编译运行算子的成功率(生成成功率):82%
整体算子数值准确性通过(执行正确率):62%
覆盖英伟达,以及华为、摩尔、海光、天数等多款国产 AI 芯片
这里所说的「生成成功率」,是指代码能编译、能运行。但与普通代码生成不同,算子生成对数学精度提出了更为严苛的要求:需要在多种输入变化条件下,始终保持高精度、可复现的一致数值结果,这也正是文中所强调的「执行正确率」。
如果说「生成成功率」关注的是算子是否能编译、能运行,那么真正的技术门槛在于是否能跑得对。在多种芯片架构并存的场景下,这一挑战被进一步放大——当同一份算子代码需要同时适配华为、摩尔线程、海光、天数等架构各异的芯片时,数值精度、舍入策略、指令调度顺序、缓存层级等细微差异,都可能导致结果偏差,甚至引发正确性失效。
一次生成、一次编译,在多芯片平台上实现数值一致、结果可验证,才是算子自动生成真正需要跨越的核心门槛。
这些结果表明,算子自动生成在多芯片环境下已经具备可行性与工程实用价值。
实验与实现细节:KernelGen是如何工作的?
实现原理:从「写算子」到「生产算子」
KernelGen 的目标并非辅助开发者写代码,而是覆盖算子从需求到落地的完整生命周期:
输入层:用户可通过自然语言、数学公式或已有实现描述算子需求
生成层:基于大模型与智能体技术,理解算子语义并自动生成 Triton 内核
验证层:自动构建测试用例,在目标芯片上与 PyTorch reference 实现进行严格的数值一致性校验
评估与优化层:对生成算子进行性能评测,量化加速比,并通过自动化调优持续优化执行效率
KernelGen 地址:https://kernelgen.flagos.io,用户在对话框里仅需输入自然语言、数学公式或是已有实现表达算子开发需求
这一流程的核心目标是:
将算子开发从「专家手工活」,转变为可复制、可扩展的工程流程。
为什么必须与 FlagOS / FlagTree 协同?
在多芯片场景下,仅生成算子代码并不足以解决工程问题,不同 AI 芯片在以下方面差异显著:
并行模型与计算单元组织方式
内存层级与访存语义
指令集与编译稳定性
因此,KernelGen 从设计之初就被纳入FlagOS 生态,并与统一 AI 编译器FlagTree深度协同:
由 FlagTree 提供统一的硬件抽象与编译基础
将硬件差异尽可能收敛在编译器的中间表示层
提升算子在多芯片环境下的编译性能与正确性
这也是算子自动生成首次具备跨芯片工程可行性的关键前提。
FlagTree:支撑算子自动生成的统一AI编译器底座
KernelGen 能够在多芯片环境下实现算子自动生成与验证,并不只是模型能力的结果,其关键支撑来自统一AI编译器 FlagTree。
FlagTree 是众智 FlagOS 社区长期推进的统一编译器项目。从2025 年 3 月发布 v0.1,到2026 年 1 月 5 日发布 v0.4,已逐步发展为面向异构 AI 计算的通用编译基础设施:
已支持12 家厂商、近 20 款AI芯片,覆盖芯片包括华为昇腾、寒武纪、沐曦、摩尔线程、海光等
支持架构从DSA、GPGPU,扩展到RISC-VAI芯片、ARM等多种体系
在技术设计上,FlagTree 主要解决两类问题:
硬件差异隔离:通过统一的硬件中间表示(计算单元、内存层次、原子操作等),将芯片差异最大程度收敛在编译器内部,而不是暴露给算子生成逻辑。
性能与易用性的平衡:在保留 Triton 高级语法的同时,引入硬件感知优化,避免「一套代码跑所有芯片」带来的性能和稳定性问题。
在FlagTree v0.4中,FlagOS 社区进一步引入TLE(Triton Language Extensions),以分层方式扩展 Triton 的跨芯片表达能力:
TLE-Lite:一次编写,多后端运行,适用于快速验证与轻量级优化
TLE-Struct:面向算子开发者的架构感知调优接口
TLE-Raw:允许直接内联 CUDA、MLIR 等厂商原生代码,用于极致性能场景
通过 FlagTree 的编译支撑,KernelGen 自动生成的算子才能在不同芯片上保持较高的编译通过率和执行稳定性。
FlagTree 项目地址:https://github.com/flagos-ai/flagtree
性能指标与验证情况:多芯片、多模型、多轮评测
不同芯片上的生成与执行正确率(用户真实场景)
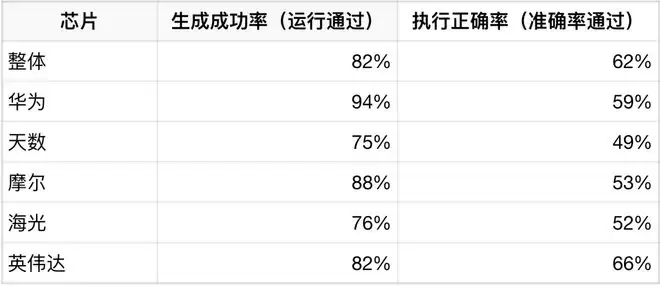
数据表明:
华为芯片在生成成功率上表现最优
英伟达芯片在执行正确率(数值准确性)上表现最佳
国产多样化架构下仍存在进一步优化空间
整体结果验证了 KernelGen在降低人工开发成本、提升跨芯片适配效率方面的核心价值。
110 个 Torch 算子的多芯片正确性与性能评测
为验证算子自动生成在真实工程场景下的可用性,评测选取了110 个代表性 TorchAPI算子,每个算子进行5 轮迭代式自动生成,并在多芯片环境下完成完整对比测试。
评测覆盖华为、海光、天数、摩尔、Nvidia等平台,并在每个平台上分别对比:
芯片原生 Triton 编译器
FlagOS / FlagTree Triton 编译器
评测重点关注两项核心指标:
执行正确率:是否成功编译运行,并在多种输入 shape 下与 Torch reference 数值一致
执行正确率与性能汇总(110 个算子)
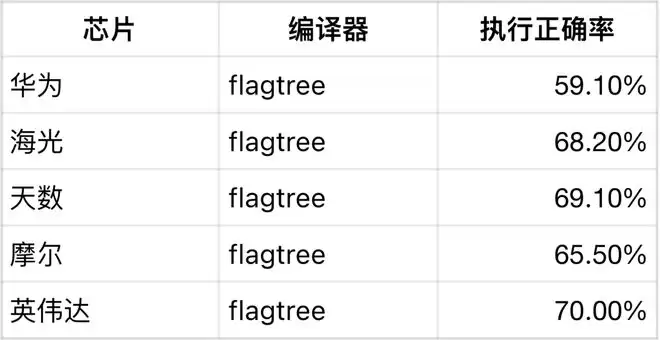
主要结论
FlagTree 在多芯片平台上整体执行正确率更高、稳定性更强
在海光、天数、摩尔及 Nvidia 等平台上,FlagTree 的通过率普遍高于原生 Triton,其中 Nvidia 平台达到70%,为各组合中最高。
更高的「能跑通」比例,为后续性能优化保留了更大空间
对规模化算子生成而言,执行正确率是第一门槛,FlagTree 在这一维度上更具工程优势。
在执行正确率方面,KernelGen 对不同数据类型设定了工业界要求的严格且可量化的精度约束:整型与布尔类型要求完全一致(零误差),而浮点与复数类型则依据其数值表示能力设定明确的误差上限——例如 FP16/FP8 级别控制在 1e-3,BF16 控制在 1e-2 量级,FP32 与 Complex64 达到 1e-6 级别。通过这种按数据类型精细分级的精度标准,KernelGen 在追求极致性能的同时,确保算子替换与跨后端生成具备可验证、可复现的数值正确性。
注:评测基于110 个算子 × 多平台 × 双编译器的完整结果,算子级明细已随 KernelGen / FlagOS 项目提供。
不同大模型在算子生成任务中的差异(以华为 Ascend 为例)
在算子自动生成场景中,大模型并非只承担「代码补全」的角色,其对算子语义理解、shape 泛化以及边界条件处理能力,都会直接影响生成算子的可执行性与稳定性。
在统一使用FlagTree Triton 编译器、并以华为 Ascend平台为目标硬件的条件下,评测对比了多种主流大模型在110 个 TorchAPI算子生成任务中的表现,重点统计其执行正确率(数值准确性通过)。
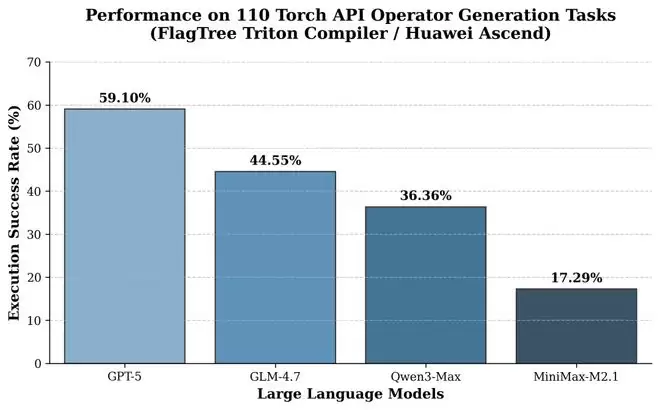
从评测结果可以看到,不同大模型在算子生成任务中的能力差异较为明显,整体呈现出清晰的分层:
GPT-5 表现最优,在 110 个算子中有 65 个能够成功生成 Triton 实现并通过多种输入 shape 的一致性校验,显示出其在算子语义理解、控制流生成和边界条件处理方面的综合优势。
GLM-4.7 位于第二梯队,在部分复杂算子和 shape 泛化场景中仍存在不稳定情况,但已具备较强的自动算子生成能力。
Qwen3-Max 与 MiniMax-M2.1在算子生成这一高约束场景下成功率相对较低,主要受限于对算子细粒度语义和底层 Triton 编程模式的理解能力。
这一结果表明,在算子自动生成这一高度结构化、强约束的任务中,模型本身的推理与结构化生成能力,仍然是影响最终工程效果的关键因素之一。
专家知识注入与算子性能进化(英伟达)
在引入模型自反思与外部专家知识后,KernelGen 的算子性能持续提升:
算子执行正确率最高可达 75.5%
74.2% 算子加速比 >0.8
68.5% 算子加速比 >1.0
加速比中位数1.04x,平均1.07x
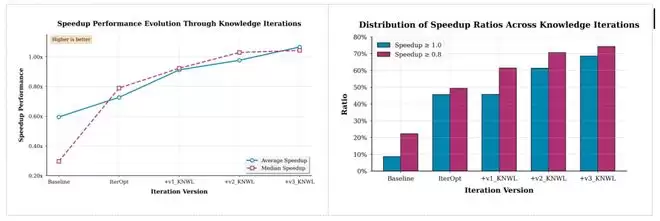
Baseline 为基于智能体自反思的迭代方法;IterOpt为面向优化目标的反思迭代方法;v1_KNWL在优化迭代中引入模型轨迹总结知识;v2_KNWL与v3_KNWL分别在不同轮次进一步融合外部专家种子知识
这表明,算子自动生成已从「能跑」迈向「能用、可优化」。
总结
Claude Code 的 30 分钟迁移案例,让行业看到了AI正在改变「写代码」的方式。
而 KernelGen 与 FlagOS 所展示的,是另一层更工程化的进展:
在硬件高度碎片化的时代,通过算子自动生成、统一编译器与跨芯片生态协同,让算子开发不再成为AI系统落地的核心瓶颈。
这不是一次演示的胜负,而是一条正在被验证、并持续演进的系统软件路线。

相关攻略

宇树科技IPO,豪华“股东团”浮出水面。美团作为最大外部股东,占股达9 65%。据了解,早在2024年美团就决定重投宇树科技,当时宇树估值10亿上下。等到一些互联网大厂开始跟进,已是2025年6月,

中新经纬3月29日电 (周奕航 谢婧雯)“Token已成为AI时代的‘货币’。人与AI交互,AI与AI协作,都以Token为核心媒介完成。”2026中关村论坛年会期间,摩尔线程相关技术负责人向中
中新经纬3月28日电 (谢婧雯 周奕航)“当理科生指挥AI打车时,他会说‘打快车回酒店’,但文科生会说‘打个能快速接上我的车,以最短距离到酒店’。”2026中关村论坛年会期间,荣耀具身智能首席营

3月最后一个周末,流媒体平台集体上新。Netflix、Apple TV+、Disney+、HBO Max(现Max)同步放出9部重点内容,从火星殖民到漫威重启,从英国悬疑到热带惊悚。我们按平台拆了一

当全球芯片行业陷入摩尔定律逼近极限的焦虑,当西方仍试图用技术封锁扼住中国芯片产业的咽喉时,一则重磅消息传来,中国芯取得了重大突破!没错,又是复旦团队,成功研制出二维半导体芯片“无极”,中国首款!全球
热门专题







热门推荐

在当今数字化阅读的时代,凡文阅读成为了许多人喜爱的阅读工具。那么,凡文阅读究竟该怎么用呢?下载与安装首先,要使用凡文阅读,需要在手机的应用商店中搜索“凡文阅读”,找到对应的应用程序

在游戏“代号妖鬼”中,摧毁骑的搭配至关重要,能让玩家在战斗中发挥出强大实力。首先是核心卡牌的选择。“火焰冲击”是必备的,它能对敌方造成高额的火焰伤害,在战斗初期就能给对手带来巨大压

使用SUMIF、IF+SUM、SUBTOTAL、排序法或动态数组(SCAN+FILTER)可解决Excel累计求和因空白中断问题,各方法分别适用于不同场景与版本。如果您在Excel

在使用谷歌浏览器时,有时候我们可能希望隐藏扩展程序插件图标,让浏览器界面看起来更加简洁。下面就为大家详细介绍几种隐藏扩展程序插件图标的方法。方法一:使用浏览器自带的隐藏功能谷歌浏览

在洛克王国的奇妙世界里,咕噜球可是捕捉宠物的关键道具。了解各种咕噜球的特点,能让你在捕捉宠物时事半功倍。普通咕噜球这是最基础的咕噜球,捕捉成功率相对较低。适合捕捉一些初始出现且比较